知网博硕论文信息爬虫
声明 代码
首先声明这段代码,是我刚毕业进公司写的,整个爬虫系统我还没写完,就被调去学python支援公司的某个项目去了,所以代码距离我写文章时候,其实已经过去了大半年有余了,代码后面因为项目的终止,再也没更新过,其中需要说明的是Tools类不能使用,因为这是以前公司大佬写的底层解析HTML的类,建议你使用Jsoup或者正则表达式去解析HTML文本。
这只是个爬取信息的爬虫,它能获取到就是 一篇论文它的作者、导师、专业、学校、毕业年份这些信息。
效果的话我计算过了,当时知网关于博硕论文总共是370万,爬虫最多的一次是爬取了350万份信息,如果你想抓取完全,是很简单,你只要将已经抓取的信息,存储在redis中,在抓取的过程中进行检验,已抓取的跳过,几轮循环下来必然能获取所有的博硕论文信息。
再者我还需要说明关于代理的事情,众所周知一个大规模的爬虫,不使用代理是不可能的,代码中的代理是阿布云的代理,账户已经过期了,如果你想拿代码继续使用,请购买阿布云代理,听着像硬广哈,但是实施就是这样,如果你想使用其他的代理,就要修改代码。
最后,我想要说的是,要想加大爬取的速度,一个是好的爬取流程,另一个就是并行抓取,也就是多线程工作,其实还有一个是高质量的代码,在这里我使用的是线程池,而不是常规的构建多线程,望周知。
代码简洁
接下来我会简介代码的工作流程。
开始部分
它的开始部分是utils 包里的 Utils,它是整个爬虫的总控制。
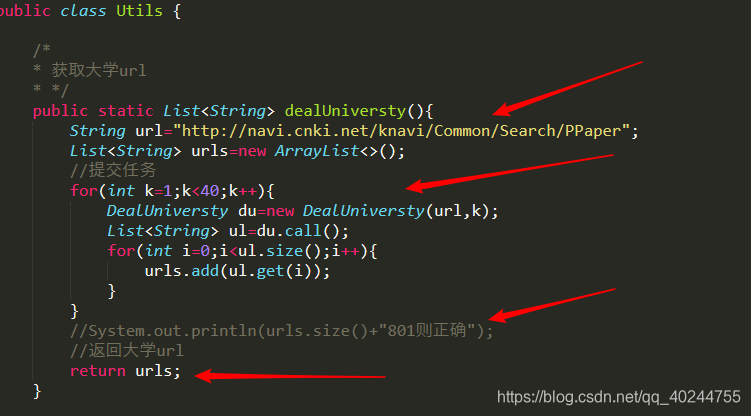
其中801是801大学的意思,现在不一定正确,正确的大学数量,需要自己看知网。
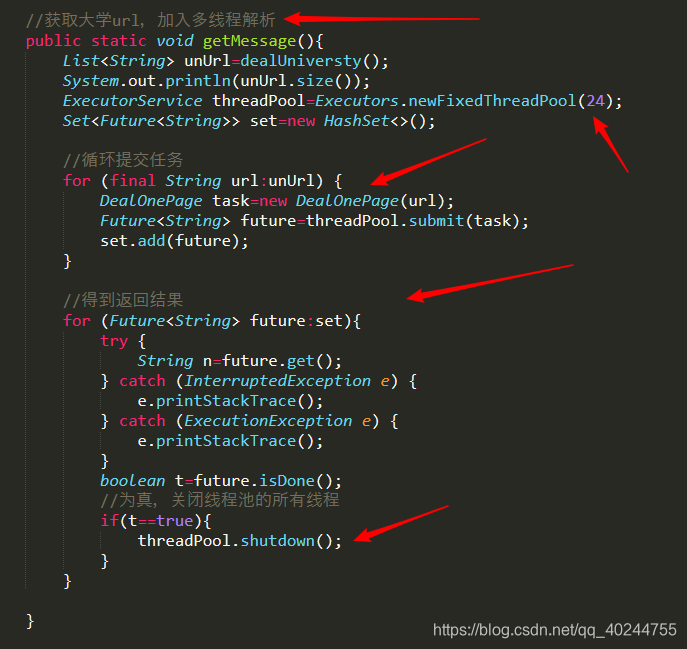
获取到各个大学的地址后,就会提交爬取任务,for迭代正是用到了线程池提交任务写法。如果你是习惯了常规的构造多线程,
建议去学习线程池的写法,很方便,但是弊端就是它可能不会如手写那么细致。
24是线程数,可修改。
得到的大学信息会生成一个csv文件,里面有它的对应的网址,所以这个由CsvReaderUtils读取并执行真正抓取各个大学的信息。
该类通过post请求获取到所有大学的title和id
通过正则表达式得到title和id
throws InterruptedException
使用jackson-data-format-csv 写入csv文件
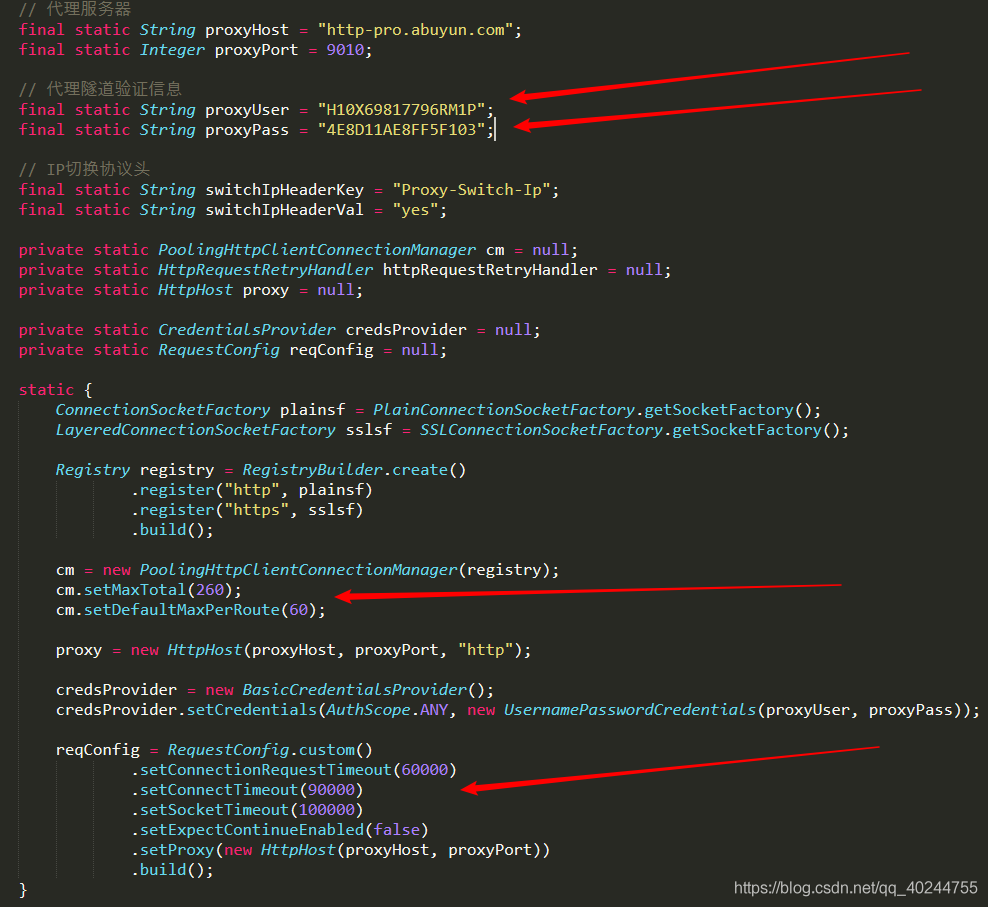
此为设置代理,使用的是阿布云的官方写法。
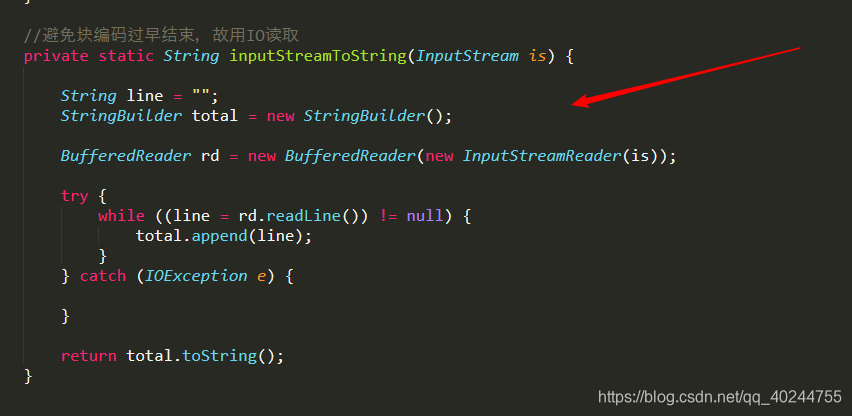
作用如注释所写,很重要。
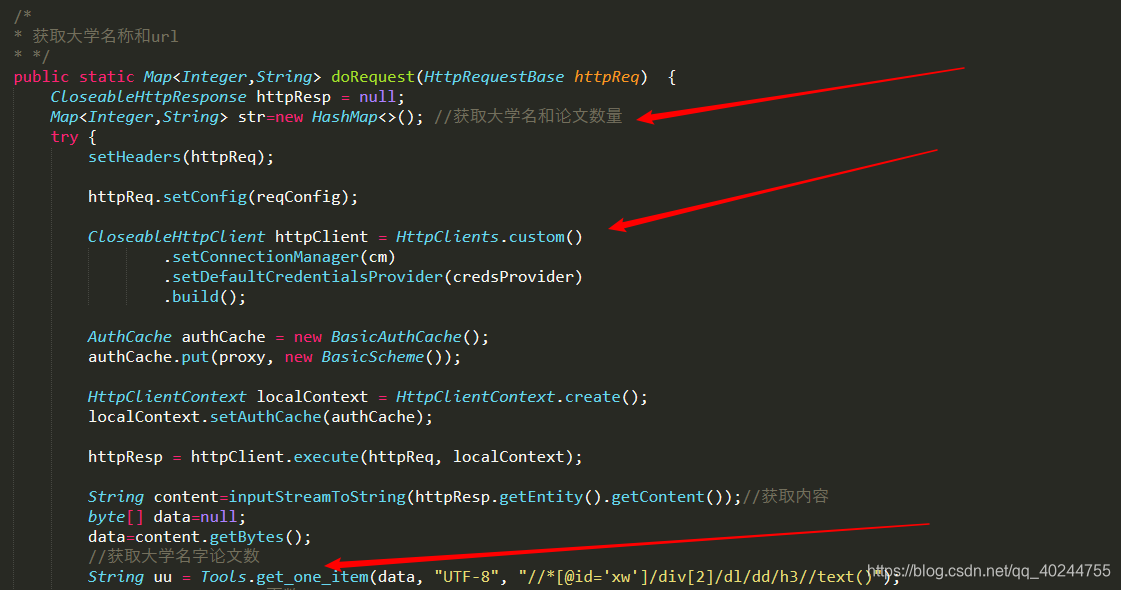
一段常规的HttpClient下载网页写法,用户获取大学名及其数量,其中Tools正是我在上文中提及,删掉改用其他解析类。
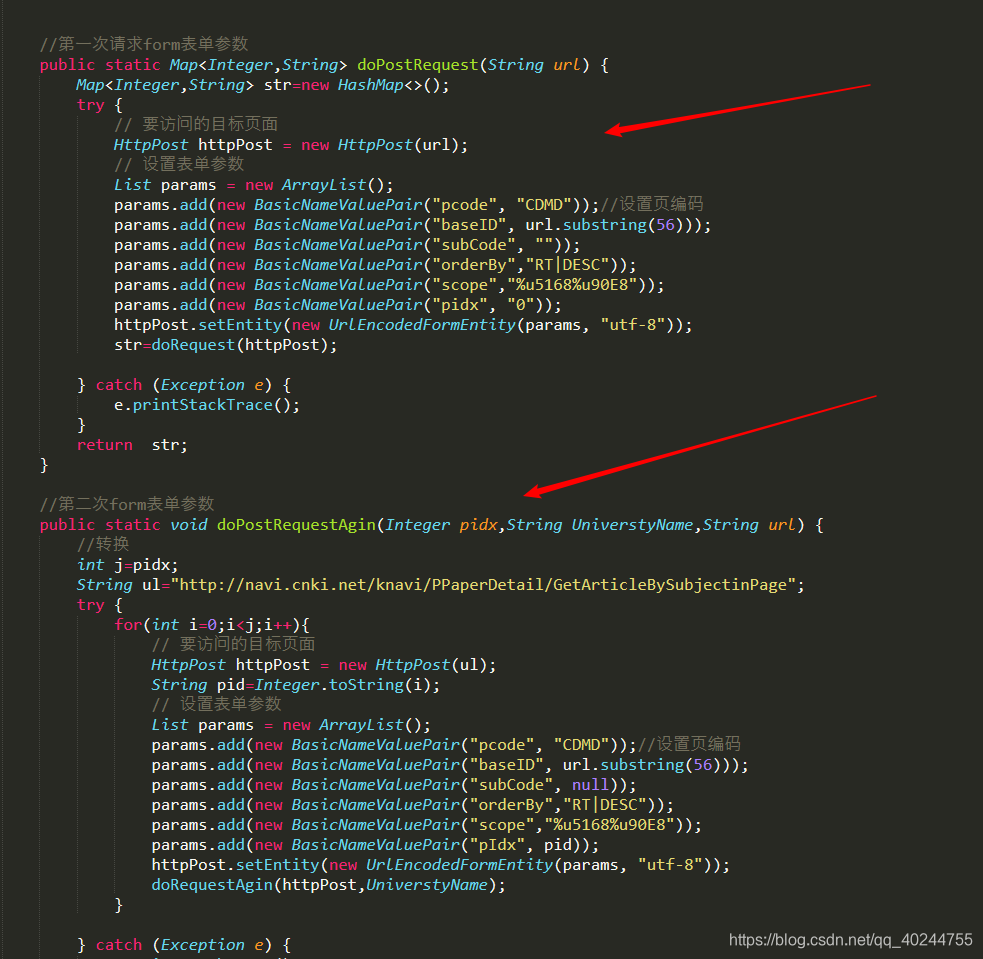
时过境迁,不知道知网是否修改了表单提交参数,在这里提及是想告诉各位,可以先看知网post参数,再审视代码里的参数,看是否有要修改的地方。
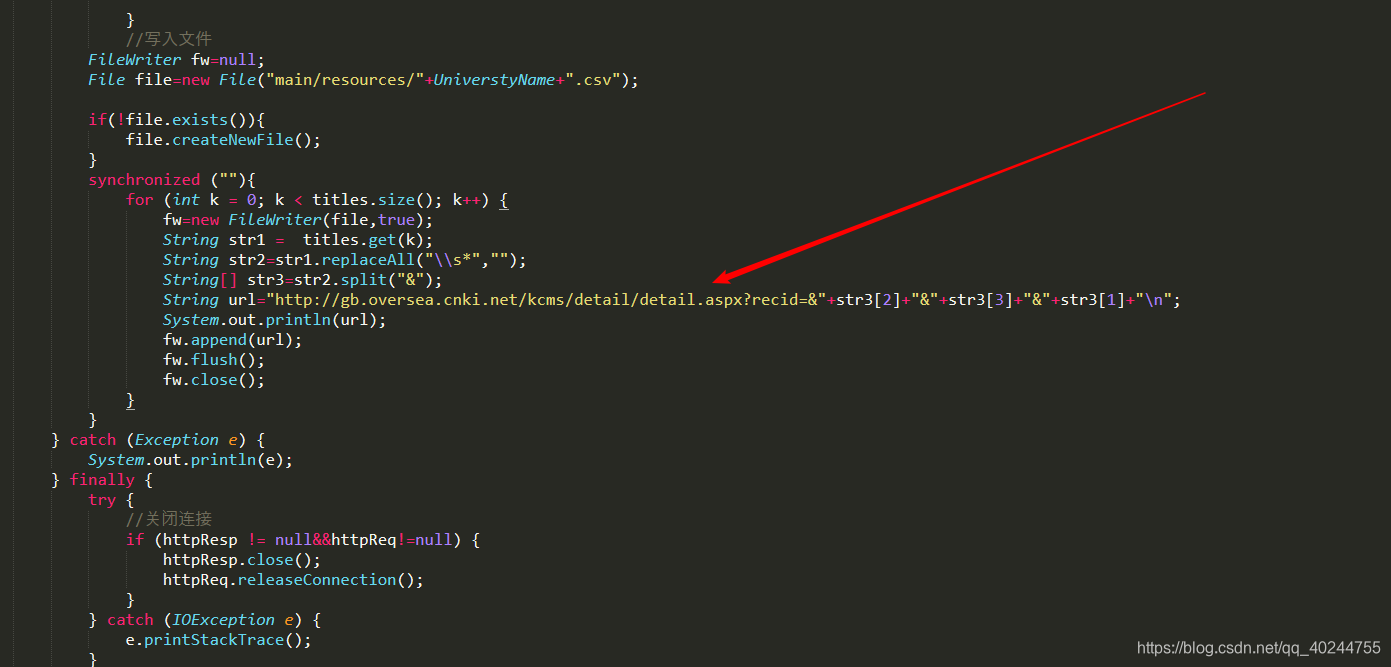
这段代码或者这个网址时是否获得专业的关键,因为正常知网到详情页是没有的,只有在这个网站上才有,你能看到这里,说明你是个幸运儿,因为为了得到专业,我想过很多方法,最后只有这个被我采用。
DealOneEssay
处理单篇论文的
获得论文标题、作者、作者导师、专业、学校、年份、学位

此处可以设置再次请求的次数,因为有时候超时很多次也请求不到,但是要接受这个结果。
最后所有的信息都会写入到csv文件中,或者你可以把它存储到数据库中。
因为这是我很久以前写的,所以有些我自己都有些不记得了,其中注释还是比较清楚的,当时也就我一个人写,也没人指导我具体该怎么写,技术总监只说个大概,剩下的就是我自己完成,回想往事,也许人的成长就是这样,一步一步,才能走得踏实圆满。代码是我刚入行写的,有不佳之处,实属正常,但我已经不想改了,只能读者自己改了。下面就是爬虫的github地址,老规矩觉得好,请给我一颗小星星,谢啦。
如果想要联系我:[email protected]
github地址:https://github.com/madpudding/RelationshipCrawler