1、jsoup介绍
jsoup是一款java的HTML解析器,可直接解析某个URL地址、HTML文件内容。它提供了一套非常省力的API,可通过DOM、CSS以及类似Jquery的操作方法取出和操作数据。
jsoup的主要功能如下:
- 从一个URL,文件或者字符串中解析HTML。
- 使用DOM或者CSS选择器来直接查找、取出数据。
- 可操作HTML元素、属性、文本。
2、jsoup和HttpClient的姻缘
虽然使用jsoup可以替代HttpClient直接发起请求解析数据,但是往往不这样用,因为实际开发过程中,需要使用多线程、连接池、代理等等方式,而jsoup对这些的支持不是很好,所以我们一般只把jsoup仅仅作为HTML解析工具使用,可以用HttpClient获取HTML,然后交给jsoup解析。
3、创建一个类并配置pom.xml
如何创建项目请看:https://blog.csdn.net/weixin_44588495/article/details/90580722

pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.crawler</groupId>
<artifactId>Crawler-first-one</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<!-- <scope>test</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
</dependencies>
</project>
利用junit来测试
4、解析URL
@Test
//解析Url
public void testUrl()throws Exception{
//解析url地址,第一个参数是访问的url,第二个参数是访问时候的超时时间
Document doc = Jsoup.parse(new URL("http://itcast.cn"),1000);
//使用标签选择器,获取title标签中的内容
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
运行结果:

5、解析字符串
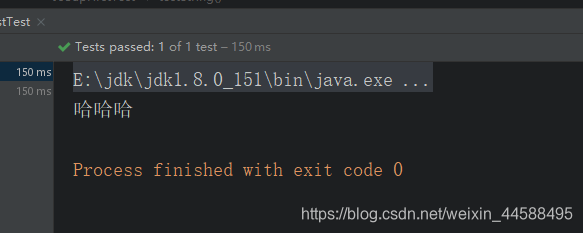
@Test
//解析字符串
public void testString()throws Exception{
//假设用httpClient读取到了html页面
String content = "<title>哈哈哈</title>";
Document doc = Jsoup.parse(content);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
运行结果:
6、解析文件
@Test
//解析文件
public void testFile()throws Exception{
Document doc = Jsoup.parse(new File("C:\\Users\\Administrator\\Desktop\\index.html"),"utf-8");
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
运行结果:

7、完整代码
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.File;
import java.net.URL;
public class JsoupFirstTest {
@Test
//解析Url
public void testUrl()throws Exception{
//解析url地址,第一个参数是访问的url,第二个参数是访问时候的超时时间
Document doc = Jsoup.parse(new URL("http://itcast.cn"),1000);
//使用标签选择器,获取title标签中的内容
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
@Test
//解析字符串
public void testString()throws Exception{
//假设用httpClient读取到了html页面
String content = "<title>document</title>";
Document doc = Jsoup.parse(content);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
@Test
//解析文件
public void testFile()throws Exception{
Document doc = Jsoup.parse(new File("C:\\Users\\Administrator\\Desktop\\index.html"),"utf-8");
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
}
}