更新内容(2018-12-2):
已开源在GIthub上:
地址:https://github.com/shillyshallysxy/Learning_NLP
前言
中文分词在中文信息处理中是最为基础的一步,无论机器翻译还是信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。
中文分词是自然语言处理的分支,是指用计算机对中文进行处理。和大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字串的形式出现。因此对中文进行处理的第一步就是进行自动分词,即将字串转变成词串。
中文的分词方法有很多,比如1983年开始的最大匹配法(论文:Word identification for Mandarin Chinese sentences)、2002年开始的基于字标注的分词法(论文:Combining Classifiers for Chinese Word Segmentation)以及近几年的深度学习方法。
本文的思想来源于《Neural Architectures for Named Entity Recognition》一文,该文中提出了一种深度学习模型(如图,源自于原论文),通过Bi-LSTM(Bi-directional LSTM),输出层接CRF使模型能够同时考虑过去的特征和未来的特征(Bi-LSTM)并学习到状态转移矩阵使输出标签(tag)时的抉择前后相互关联(CRF)
使用的时候通过维特比算法(动态规划的思想)快速对Bi-LSTM的输出和CRF学习到的状态转移矩阵解码,获得输出的标签(tag)序列。

中文标注数据集
本次实验采用PFR人民日报标注语料库进行,共有60万条句子,2604万个字。
PFR人民日报标注语料库是在得到人民日报社新闻信息中心许可的条件下,以1998年和2014人民日报语料为对象,由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库。为了促进中文信息处理研究的发展,他们三方计划公开PFR语料库。作为公开的前期工作,从4月3日起,在他们三方的主页上免费公开PFR语料库1月份的语料。PFR语料库的制作规范按照《现代汉语语料库加工――词语切分与词性标注规范》。
首先对语料库进行预处理,这次的分词仅需要词语切分部分的信息,并不需要词性标注信息,因此对原语料库的分词信息进行读取并进行标注,将每个中文字标注为4种类型,分别为S(0)、B(1)、M(2)、E(3),其中S(Single)代表单个字,B(Begin)代表词的第一个字(词的开始),M(Middle)代表词的中间部分字,E(End)代表词的最后一个字(词的结束)(如图)。同时将语料库进行随即划分,将90%作为训练集,10%作为验证集以评估模型。

其次,语料库直接全部载入内存,每次训练全部载入的过程缓慢,耗时长,而且必然会造成内存巨大的开销,16G的内存全部被占用之后还不够,因此考虑构建一个队列,每次从外部磁盘读取部分数据,shuffle打乱后存放到内存中的队列中,此时内存只需要维护队列大小的空间,并且一次只需要载入部分数据,载入速度快了数十倍,同时训练过程中从内存中读取数据,训练过程的速度未收到影响。

| 代码1 划分语料库 |

| 代码2 将处理过的数据写入磁盘 |

| 代码3 将数据批次批量读取到内存中 |

| 续代码3 将数据批次批量读取到内存中 |
基于Bi-LSTM-CRF的中文分词模型
前向LSTM和后向LSTM的隐含层维度设置为100,词嵌入的维度为100,优化算法采用Adam Optimizer。
其中trans为CRF中的转移矩阵,logits为Bi-LSTM的最终输出,max steps为每个句子的长度,初始化方法使用xavier Initialization,以使网络中的信息更好地流动,网络各层激活值及状态梯度的方差应尽量保持不变。

| 代码4 模型中一些参数的设置 |
首先对词进行词嵌入获得词向量,然后建立Bi-LSTM层,以词向量序列作为输入,双向LSTM通过两个LSTM,一个正向输入序列一个反向输入序列,使模型能够同时考虑过去的特征(通过前向过程提取)和未来的特征(通过后向过程提取),将输出拼接(concatenate)为2个LSTM隐含层变量大小。

| 代码5 Bi-LSTM层 |
上层的输出经过一个隐含层输出到CRF ,这一层后直接接上softmax模型就变为了没有结合CRF的深度学习方法,但Bi-LSTM虽然学习到了上下文的信息,但在预测过程中输出序列之间并没有互相的影响,仅仅是挑出每一个字最大概率的label,通过引入CRF加入了对label之间顺序性的考虑,因此效果更好。

| 代码6 Project层 |
CRF则将LSTM在每个t时刻在第i 个tag上的输出作为特征函数中的点函数,使原本的CRF中引入了非线性。整体模型还是以CRF为主体的大框架,使LSTM中的信息得到充分的再利用,最终能够得到全局最优的输出序列。

| 代码7 Loss层 |

| 代码8 训练部分 |

| 代码9 验证部分以及保存部分 |
在使用时,对LSTM的输出矩阵利用维特比算法求取最优标记序列,即取y* :
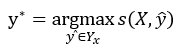

| 代码10 维特比算法获得最优标注序列 |
实验结果及分析
训练过程(每十个迭代输出一次,一共1800个迭代)


想了一些句子,并选取了一些容易产生歧义的句子(比如上课时举到的一些例子)以及去网络上查找了一些比较有歧义的用于测试中文分词开放引擎的句子,对模型实际使用时的性能进行测试,并下载了最新的Jieba 0.39版本分词进行比较。
表1 本文模型与Jieba分词的对比实验
| 测试用句 |
Bi-LSTM-CRF 应用于中文分词 |
Jieba (最新版0.39) |
| 这个仅仅是一个小测试 |
这个/仅仅/是/一个/小/测试 |
这个/仅仅/是/一个/小/测试 |
| 这仅仅是一个小测试 |
这/仅仅/是/一个/小/测试 |
这/仅仅/是/一个/小/测试 |
| 李小福是创新办主任也是云计算方面的专家 |
李小福/是/创新/办/主任/也/是/云/计算/方面/的/专家 |
李小福/是/创新/办/主任/也/是/云/计算/方面/的/专家 |
| 实现祖国的完全统一是海内外全体中国人的共同心愿 |
实现/祖国/的/完全/统一/是/海内外/全体/中国人/的/共同/心愿 |
实现/祖国/的/完全/统一/是/海内外/全体/中国/人/的/共同/心愿 |
| 南京市长江大桥 |
南京市/长江/大桥 |
南京市/长江大桥 |
| 中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。 |
中文/分词/在/中文/信息/处理/中/是/最/最/基础/的/,/无论机器/翻译/亦/或/信息检索/还是/其他/相关/应用/,/如果/涉及/中文/,/都/离/不/开/中文分词/,/因此/中文分词/具有/极高/的/地位/。 |
中文/分词/在/中文信息处理/中是/最最/基础/的/,/无论/机器翻译/亦/或/信息检索/还是/其他/相关/应用/,/如果/涉及/中文/,/都/离不开/中文/分词/,/因此/中文/分词/具有/极高/的/地位/。 |
| 蔡英文/和/特朗/普通话 |
蔡/英文/和/特朗普/通话 |
|
| 研究生命的起源 |
研究/生命/的/起源 |
研究/生命/的/起源 |
| 他从马上下来 |
他/从/马上/下来 |
他/从/马上/下来 |
续表1 本文模型与Jieba分词的对比实验
| 老人家身体不错 |
老人家/身体/不错 |
老人家/身体/不错 |
| 老人家中很干净 |
老人家/中/很/干净 |
老人家/中/很/干净 |
| 这的确定不下来 |
这/的/确定/不/下来 |
这/的/确定/不/下来 |
| 乒乓球拍卖完了 |
乒乓球/拍卖/完/了 |
乒乓球/拍卖/完/了 |
| 香港中文大学将来合肥一中进行招生宣传今年在皖招8人万家热线安徽第一门户 |
香港/中文大学/将/来/合肥/一中/进行/招生/宣传/今年/在/皖招/8/人/万家/热线/安徽/第一/门户 |
香港中文大学/将来/合肥/一中/进行/招生/宣传/今年/在/皖/招/8/人/万家/热线/安徽/第一/门户 |
| 在伦敦奥运会上将可能有一位沙特阿拉伯的女子 |
在/伦敦/奥运会/上/将/可能/有/一位/沙特/阿拉伯/的/女子 |
在/伦敦/奥运会/上将/可能/有/一位/沙特阿拉伯/的/女子 |
| 美军/中/将/竟/公然/说 |
美军/中将/竟/公然/说 |
|
| 北京大学生喝进口红酒 |
北京/大学生/喝/进口/红酒 |
北京/大学生/喝/进口/红酒 |
| 在北京大学生活区喝进口红酒 |
在/北京/大学/生活区/喝/进口/红酒 |
在/北京大学/生活区/喝/进口/红酒 |
| 将信息技术应用于教学实践 |
将/信息/技术/应用/于/教学/实践 |
将/信息技术/应用/于/教学/实践 |
| 天真的你 |
天真/的/你 |
天/真的/你 |
| 我们中出了一个叛徒 |
我们/中/出/了/一个/叛徒/ |
我们/中出/了/一个/叛徒 |
总结
可以看到Bi-LSTM-CRF模型在解决分词这个标注问题上表现比较优秀,在比较小的语料库上能够达到这样一个勉强能用的效果,甚至在个别句子上优于Jieba,但缺点也很明显,首先需要大量的标注好的分词训练数据集,更多的数据量基本意味着更好的分词效果,其次本模型对于新词没有很好的适应能力,对于新词汇的分词会出现困难,并且没有对专有名词进行收录,对于生僻的人名也没有办法很好的处理。
参考文献
- 梁南元, 书面汉语的自动分词与另一个自动分词系统CDWS, 中国汉字信息处理系统学术会议, 桂林, 1983
- Nianwen Xue and Susan P. Converse. Combining Classifiers for Chinese Word Segmentation, First SIGHAN Workshop attached with the 19th COLING, Taipei, 2002
- Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360. 2016