条件随机场模型CRF(Conditional Random Field)
CRF是一种判别式模型,判别式模型是对条件分布进行建模,生成式模型是对联合分布进行建模。判别式模型评估对象是最大化条件概率p(y|x)并直接对其建模,生成式模型评估对象是最大化联合概率p(x,y)并对其建模。
典型的生成式模型有N-Gram语言模型,隐马尔科夫模型,马尔科夫随机场,朴素贝叶斯模型,LDA和最近很火的生成对抗网络。生成式模型先经过贝叶斯转换成Y = argmax p(y|x) = argmax p(x|y)*p(y),然后分别学习p(y)和p(x|y)的概率分布,主要通过极大似然估计的方法学习参数,如NGram、HMM、Naive Bayes,变分自编码等编码器。
判别式模型直接通过解在满足训练样本分布下的最优化问题得到模型参数,主要用到拉格朗日乘算法,梯度下降算法,典型的判别式模型有最大熵模型,条件随机场模型,逻辑回归模型(LR),支持向量机(SVM),以及现在很流行的神经网络分类模型(LSTM,CNN)等。
判别式模型是监督训练,有标签,生成式模型是无监督训练,无标签。
判别式模型可以加入任何特征组合,选择特征比较灵活;
生成式模型需要将特征引入马尔科夫链中。
条件随机场模型主要用于序列标注问题,比如用CRF进行命名实体识别。
以序列标注为例,比如这句话:“Bob drank coffee at Starbucks”,给这句话的每一个单词标注词性,一个简单的办法是将序列标注
问题转换为分类问题(因为词性的数量是有限的),但是把他当成分类问题就相当于认为词性之间是相互独立的,实际上对一个序列来说,词性的出现并不是相互独立的,而是相互影响的。比如说,第二个词drank是动词,那后面紧跟的那个词是动词的可能性就很小,是名词的可能性很大,所以这是一个条件概率,不是相互独立的,把序列标注问题看成分类问题是不合理的(LSTM做序列标注就是一个分类问题,后面详细说LSTM做序列标注的优缺点)。
而CRF就可以解决这个问题,在CRF之前有HMM,最大熵模型等方法,基本上也都是基于联合概率的方法,是生成式模型。
CRF可以认为是基于统计的,以上面的句子为例,上面句子的标注方法有3^5=273种(假设只有名词,动词,介词三种词性),根据人的感觉,显然(名词,动词,名词,介词,名词)这种标注方式可能性最大,而(名词,动词,动词,动词,名词)这种标注方式的可能性很小,因为这不符合语法规则。
我们要在这么多可能的标注中找一个可能性最大的标注方式当做正确的标注方式。
怎么判断标注的可能性的大小呢(也就是标的靠不靠谱)
假设我们给上面的所有可能的标注打分,越靠谱的打分越高,越不靠谱的打分越低,也就是说我们给(名词,动词,名词,介词,名词)这种正确的标注打高分,给(名词,动词,动词,动词,名词)这种动词相连的标注打负分。
上面所说的动词相连就是一个特征函数,我们可以做一个特征函数集合,用这个特征函数集合给一个标注序列打分,并选出最靠谱的标注。也就是说,每一个特征函数都可以对这一个标注序列打分,将这些特征函数对同一个标注序列的打分综合起来,就是这个标注序列的综合评分。
如果有5个特征集合,对上面的273中标注方式进行打分,那么第一种标注方式通过特征集和得到5各大分,第二个标注方式也得到5个打分,。。。,第273个标注方式也有5个打分,那么对这句话的标注用这种方法一共得到了(5+5+5+5+…+5)=273*5个打分,选择打分最高的当成对该序列的正确词性标注结果。
如何定义CRF的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
句子S:就是我们要标注此行的句子序列
i:句子中的第i个单词
I_i:已经标好词性的标注序列第i个词的词性(表示要评分的标注序列给第i个单词标注的词性)
I_i-1:已经标号词性的标注序列的第i-1个词的词性(表示要评分的标注序列给第i-1个单词标注的词性)
特征函数的输出值是0或1,0表示要平分的标注序列不符合这个特诊函数所代表的特征,1表示要平分的标注序列符合这个特征函数所代表的特征
特征函数包括两种,转移特征和状态特征,假设每个当前词第i个词有M个特征,这M个特征由J个转移特征和L个状态特征组成,即M=J+L
转移特征针对的是词的前后之间的限定,每个当前词都有J个特征,将这J个特征得到的打分求和是这个当前词的总打分。
举个例子:
我们对“Bob drank coffee at Starbucks”这句话进行词性标注,先设定转移特征函数
假设我们的词性集合里只有三种词性(名词,动词,介词)
转移特征函数:
当前词是drank
T1:if(当前标注=名词 and 前一个词的标注=动词)return 1 else 0
T2:if(当前标注=动词 and 前一个标注=名词) return 1 else 0
T3:if(当前标注=介词 and 前一个标注=名词) return 1 else 0
T4:if(当前标注=名词 and 前一个标注=名词)return 1 else 0
这里设定了三个转移特征函数,转移特征函数由当前输出词性和上一个词的词性决定,当然也可以由当前词和上一个词性以及上上一个词性决定,那样转移特征函数的个数就增加了。
用这四个特征函数去套标注的序列,
比如我给上面那句话标注的是‘名词,名词,动词,介词,名词’,用上面的四个转移特征函数给这个标注序列打分,
当i=drank时,T1=0,T2=0,T3=0,T4=1 T1+T2+T3+T4=1
当i=coffe时,T1=0,T2=1,T3=0,T4=0 T1+T2+T3+T4=1
当i=at时,T1=0,T2=0,T3=0,T4=0, T1+T2+T3+T4=0
当i=Starbucks时, T1=0,T2=0,T3=0,T4=0, T1+T2+T3+T4=0
所以这个句子的这种标注方式在特征函数的约束下得到的打分为 1+1+0+0=2
再看另一种标注方式‘名词,动词,名词,介词,名词’
当i=drank时,T1=0,T2=1,T3=0 ,T4=0 T1+T2+T3+T4=1
当i=coffe时,T1=1,T2=0,T3=0 ,T4=0, T1+T2+T3+T4=1
当i=at时,T1=0,T2=0,T3=1,T4=0, T1+T2+T3+T4=1
当i=Starbucks时, T1=0,T2=0,T3=0,T4=0, T1+T2+T3+T4=0
在该转移特征函数的约束下,这种标注方式得到的打分为 1+1+1+0=3
3>2,所以第二种标注方式要比第一种标注方式合理一点,在上面我们知道这5个词共有3^5=273中标注方式,对每一种标注序列都由上面的四个特征函数来打分,取分数最高的标注序列作为正确的标注序列。当然转移特征函数是人为设计的,如果你有足够的耐心设计足够多且精准的特征函数,模型的训练效果也会变得很好。
下面介绍L个状态特征函数
状态函数表示第i个词的标记概率,每个当前词都有L个状态特征函数
所谓状态指的是需要标注的种类,在我们的例子中,有3个词性种类,也就是每个当前词有3中状态,状态函数就是计算当前词每种状态的概率
当i=drank时,
L1:P(i=名词)=0.3 通过其他算法(如分类算法)计算出来的
L2:P(i=动词)=0.6 通过其他算法(如分类算法)计算出来的
L3:P(i=介词)=0.1 通过其他算法(如分类算法)计算出来的
每个当前词有三种状态特征函数,每一个特征函数都对应着一个权重,比如L1,L2,L3分别对应
上面介绍的转移特征函数和状态特征函数可以总结成一个公式
T表示一个句子的词的个数,第一项是转移特征函数和他对应的权重,第二项是状态特征函数和他对应的权重。下面为了方便会把这两个特征函数合并成一个特征函数。
Note: 这里我们的特征函数仅仅依靠当前单词的标签和前一个单词的标签对标注序列进行判断,这样建立的CRF也叫作线性链CRF,是CRF中一种简单的情况。
从特征函数到概率
定义好一组特征函数后,我们要给每一个特征函数fj赋予一个权重lamdaj。只要有一个句子s和一个标注好的序列l(这是小写的L),就可以用上面的特征函数集合对标注序列I进行打分。
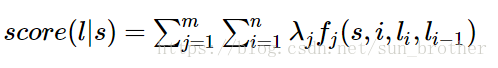
上面的公式是对已经标注的序列l的打分,(这个标注不管是不是对的),m表示特征函数集合中特征函数的个数,第一个求和行数表示每一个特征函数对这个标注序列进行打分,并把这些打分加起来作为特征函数集合对这个标注祖列的评分,如果这个标注序列符合特征函数集合中的多个函数所代表的特征,那么这个标注是正确的可能性就大,反之,如果这个标注不符合特征函数集合中所有特征函数所代表的特征,那么这个标注就很不靠谱,这个标注是错误的可能性就很大。第二个求和表示一个标注序列有n 个词,求句子的每个单词的特征值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:
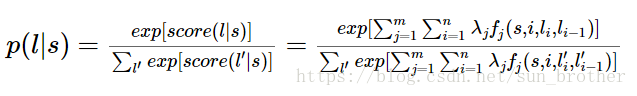
其中 l’指的是对同一个句子进行标注的所有可能的标注结果,比如上面的例子一共有273*5中标注方式,那上面的公式l’就有273*5中可能的结果,把这些可能的打分求和就是上面公式的分母。
以上面的句子为例,假设特征函数集合中一共有四个特征函数,f1,f2,f3,f4.
f1=1 如果当l_i是“副词”并且第i个单词以“ly”结尾;其他情况f1=0;不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列
f2=1 如果i=1,l_i=动词,并且句子s是以“?”结尾;其他情况f2=0;同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
f3=1 如果当l_i-1是介词,l_i是名词时;其他情况f3=0;λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。
f4=1 如果l_i和l_i-1都是介词;其他情况f4=0;同时f4对应的权重是负值,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列
好了,一个条件随机场就这样建立起来了,让我们总结一下:
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予
一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
CRF的训练过程:
以中文为例,给定一句话,首先将其中的人名,地名,机构名等给以特殊符号标记,比如(B-PER,M-PER,E-PER,S-PER)表示人名的开头字,中
间字,结尾字,单个字,以此类推。将训练预料中的所以实体都标记好,接下来是确定模板,也就是特征函数,就是上面提到的1,f2,f3,f4。训练完成后,就
确定了各个特征函数的权重,再输入一个句子就会根据权重将这些句子标记。
总之,分三步走:
step1:先确定特征函数
step2:在给定的数据集上确定要学习的参数(权重)
step3:用学习好的模型对新数据进行序列标注或序列求概率问题
BiLSTM+CRF
我们知道,LSTM对序列问题处理的很好,也有方法用LSTM左词性标注,当然这种方法是把序列标注问题看成一个分类问题,采用的是LSTM+softmax架构。
有人说,LSTM的输出不仅和当前的输入有关,还和上一时刻的隐藏层输出有关,这个性质不是刚好符合序列标注问题的序列性的特点吗:当前的词的标注和前面的词的标注相关。
在这里解释一下这个问题,LSTM当前时刻的输出由当前时刻的输入和上一时刻隐藏层的输出决定,仍是以词性标注为例,用LSTM来做词性标注,输入的是词向量,输出的是当前词的词性,这个词性由当前时刻输入的词向量和上一时刻的隐藏层输出决定,但是,当前时刻的输出和上一时刻的输出没有任何关系!! 也就是说,不管上一时刻的词性是什么,都不影响当前时刻的标注的判断!分类问题的类别之间肯定是相互独立的。有人会说,LSTM不是有记忆性嘛,上一时刻的隐藏层的信息已经传递给当前时刻了,当前时刻包含了上一时刻的信息,怎么能说当前时刻的输出和上一时刻没有关系呢?答:上一时刻的信息是由上一时刻的词向量产生的信息,而不是由上一时刻的词性产生的信息,当然,上一时刻的信息对当前的词性的判断确实会产生一定影响,但是上一时刻由词向量产生的信息对当前时刻的词性的判断的约束力是很弱的,上一时刻的词向量对这一时刻的词性的约束力要远远小于上一时刻的词性对这一时刻的词性的约束力,比如说,对“Bob drank coffee at Starbucks”这句话进行词性标注,当前时刻是’coffee ‘,用LSTM来做可能会保证这个句子整体的打分比较高,但是无法保证句子内部词性与词性之间的关联,比如LSTM可能会产生‘动词,动词’这样的标注方式,但是CRF就不可能产生这样的错误。也就是说,LSTM对序列问题的处理有强大的拟合能力,但是照顾不到内部的每个个体,无法对每个时刻的输出结果进行约束,这就是用LSTM+softmax架构做序列标注问题的弱点,及我们需要在LSTM后加CRF层的原因。
总之:用LSTM+softmax做序列标注问题是把序列标注为看成分类问题,而分类问题的类别之间是相互独立的,但是对序列标注来说,每个当前词的标注都是和上一时刻的标注结果有关的,这就是把序列标注问题看成分类问题的先天劣势,为了克服这一问题同时要用上LSTM强大的数据拟合能力,就有人提出了LSTM+CRF的架构。
不同于LSTM+softmax的分类架构,LSTM+CRF的架构的核心仍然是CRF模型,依赖的仍然是两类特征函数,LSTM在这里的作用就是用来求状态特征函数,LSTM的输出作为CRF模型中的状态特征函数那一项(每个词在n个标注上的概率分布),而转移特征函数那一项仍是认为设计的特征函数。
BiLSTM+CRF中的CRF与传统的CRF之间的区别
通过查看相关代码,我们知道BiLSTM+CRF模型是不需要设计任何特征的,那不用设计特征怎么体现CRF转移函数的约束能力呢?在BiLSTM+CRF模型中,CRF部分的转移函数体现在一个转移矩阵上,这个转移矩阵最初的值是随机初始化产生的,他是一个[class,class]大小的矩阵,不用认为设计特征也就不是0,1值这样的特征,他的值完全是由网络学习出来的,实际上这个转移矩阵是传统CRF公式中转移函数对应的权重和转移特征函数的结合。那这个转移矩阵是如何做到对相邻词性的约束的呢?这就要看BiLSTM中CRF的输入,这里CRF输入的是LSTM的输出,也就是每个词的词性标注的概率分布,根据真实标签在概率分布矩阵中找出真实标签位置对应的预测标签,将预测标签路径和真实标签路径比较,产生整个句子的误差和,根据这个误差和进行反向传播训练网络。
转移矩阵:类别和类别之间的转移矩阵,p(i,j)就是第i个标签后面接第j个标签的概率,通过学习会得到这样的规律,这个词性后面出现某个词性的概率很大,某个词性后面出现某个词性的概率非常小。
CRF的求解
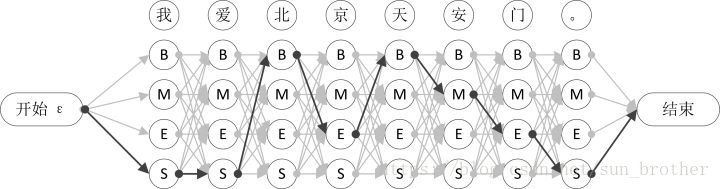
在上面的分析中我们要计算一句话的打分的最大值,只能将每个词的每一种标注结果一一连接起来,如上图所示,所有的路径的打分都要一一计算,可以想象这个计算量非常庞大,如何减少计算量并找到最优路径,这是维特比算法研究的问题。这个找最优路径的过程就是CRF解码的过程,也就是说在训练好模型后在已知权重下仍然需要在所有可能的路径里选择一条最优的路径,这个解码过程不在训练过程中,在测试过程中。
维特比算法寻找最优路径(Viterbi)
维特比算法的思想是利用动态规划来减少需要计算的路径量,避免重复计算
维特比算法的每一步选择都保存了之前所有步骤到当前步骤的最小总代价或最大价值以及当前代价情况下前继步骤的选择。依次完成所有步骤后,通过回溯的方法选择最优路径。
简单来说,先计算从开始到第一个词的最大概率,得到最大概率对应的位置,将当前得到的最大概率和第一个词到第二个词所有可能概率相加,选概率和最大的位置作为第二个词的词性,在看第二个词到第三个词的概率,将现在得到的概率和第二个词到第三个词的所有概率依次相加,选概率和最大的位置作为第三个词的词性,直到这句话结束。
HMM
隐马尔可夫模型是一种概率图模型,概率图模型一般用来处理序列数据(如文本,语音,时序序列等),是生成式模型,对联合概率进行建模,从给定数据中学习数据的分布,获得的信息比判别式模型(对条件概率进行建模的模型)要多,对数据要求高,你的训练数据要反应数据的全貌,学习起来速度慢。
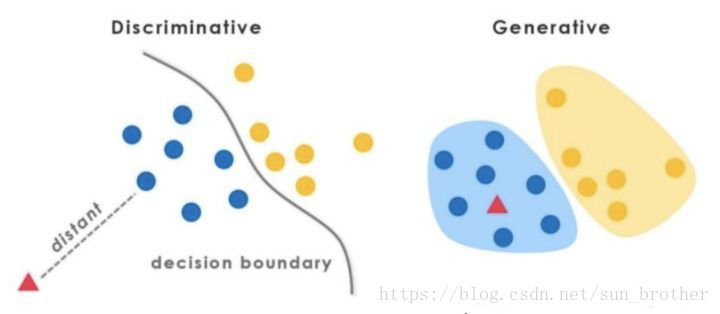
这个图反映了生成式模型和判别式模型的差别,判别式模型学习到一条分别线,生成式模型学习到的是整个数据的分布情况,不仅仅是一条分界线,还会有方差,均值之类的信息(完全反应数据分布)。
隐马尔可夫模型处理的数据坑定要符合马尔科夫性:当前时刻的输出只和当前时刻的输入和前一时刻的输入有关,和t-2时刻及之前的时刻的输入无关。
HMM五要素:
隐藏状态集:Y={y1,y2,…yn},比如词性标注中要标注的词性,n表示词性的个数
观测状态集:O={o1,o2,…,ot},比如一个句子,这个句子有t个词
状态转移矩阵:比如从y1这个词性到y8这个词性概率,就是y1后面的词标记为y8的概率
观测矩阵:就是一个句子中的每个词所有可能的标记,每个标记(词性)对应的概率
初始概率分布:开始训练时状态转移矩阵的初始化得到的概率。
HMM与CRF的区别
由于马尔科夫假设的制约,HMM只能有转移矩阵这一种特征无法加入其它特征,而词性标注等序列问题除了和上一时刻的状态有关,还和上下文,语义信息等其它特征有关,这种情况HMM就没办法解决,CRF就没有这个问题,他可以很容易的特征融合,CRF不仅有转移函数这种特征,还可以融合新特征,新的特征可以加在状态特征函数那一项。