梯度下降数学解释:
- 场景假设
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。怎么做呢,首先以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处;同理上山也是如此,只是这时候就变成梯度上升算法了
- 泰勒展开式
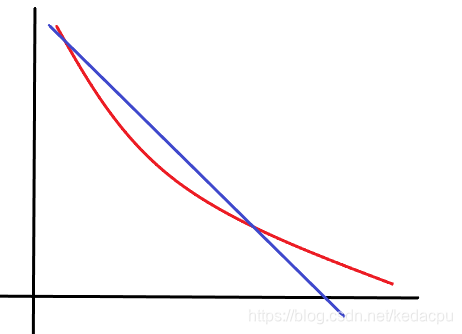
泰勒展开式的目的是拟合,将上图的曲线拟合成直线,虽然存在误差,但只要不影响实际情况,我们就可以直接在这条直线下进行讨论(更高维度也是如此)
于是我们有直线方程
f(x)-f(x₀)≈(x-x₀)•f'(x₀)
PS:场景中说的是下山,但那是在空间坐标系下讨论,这里为了方便,只在平面坐标系下做讨论,但是不管维度是多少,原理是一样的。
- 梯度下降
梯度:函数在给定点上升最快的方向,其本质就是导数(斜率)
首先,我们有一个可微分(可微<=>可导)的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值(此时导数为0),也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走(梯度的反方向),就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向
所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。
- 梯度下降公式推导
令 θ=[x] θ₀=[x0]
解释:因为这里讨论的是一维(直线需要在二维下进行讨论,不然没有意义),所以 [] 内只有一个变量;如果是三维那么 [] 里就应该有三个变量[a,b,c],以此类推,最终我们把这个集合赋值给θ,方便日后讨论。
此时我们有
f(θ)-f(θ₀)≈(θ-θ₀)•▽f(θ₀)
因为这是一个可微分方程,所以(θ-θ₀)是一个微小向量,我们知道标量*单位向量=向量,所以令:
(θ-θ₀)=ŋν(其中 ŋ是标量,ν是单位向量)
注意:(θ-θ₀)不能太大,否则线性近似就不够准确
重点,局部下降的目的是希望每次θ更新 -> f(θ)↓ ,重复这个过程,直到▽f(θ₀)=0。所以:
f(θ)-f(θ₀) ≈ (θ-θ₀)•▽f(θ₀) = ŋν•▽f(θ₀) < 0
因为ŋ是标量,且一般设定为正数,所以可以忽略,则不等式变成:
ν•▽f(θ₀) < 0 其中ν是需要我们求解的
那么,这个不等式在表达什么
我们知道▽f(θ₀)是当前位置的梯度方向,
也就是说当ν的方向是梯度的反方向时,
不等式能最大程度的小,也就保证了ν的方向是局部下降最快的方向

将这个公式跟开头的公式对比,事情到这里就结束了,我们终于获得了梯度下降的公式,有没有发现公式推导出来后,f(θ)-f(θ₀)不见了,因为只要满足梯度下降公式,f(θ)就会一直下降(前提:(θ-θ₀)不太大),而我们只需要在图像上观察f(θ)的值就好了

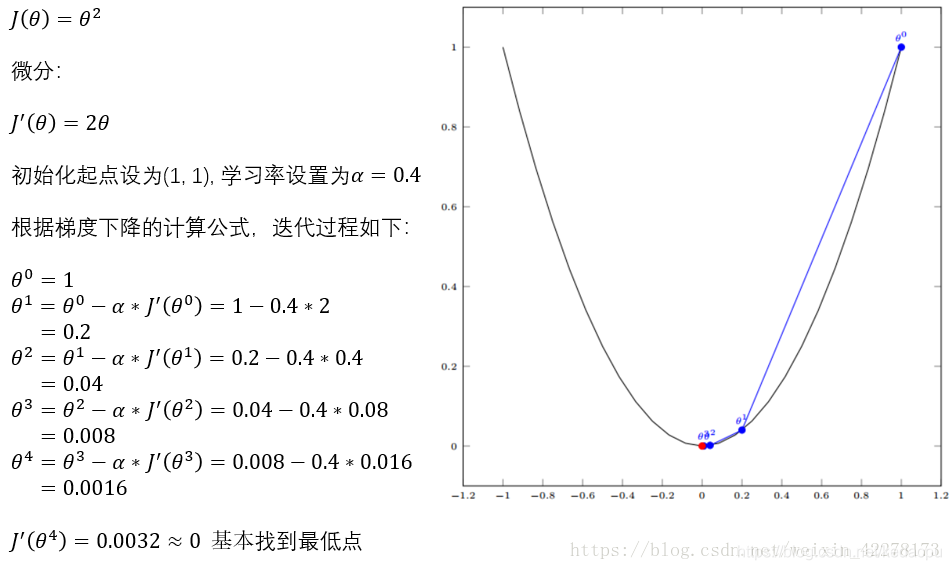
- 单变量示例
- 神经网络
梯度下降公式在神经网络中用于对(w,b)的更新,是的,你只需要将θ替换成 w 或 b ,▽J(θ) 替换成 损失函数对 w 或 b 的偏导数,其中 α 是 学习率(人为设置),最后你就可以获得局部最优模型了。
PS:后向传播算法的目的在于快速计算神经网络中各层参数的梯度,它与梯度下降算法是包含关系。
感谢启发:https://blog.csdn.net/weixin_42278173/article/details/81511646?utm_source=app
https://blog.csdn.net/qq_41800366/article/details/86583789?utm_source=app