本文是在搭建好三台虚拟机后进行的,若为做前部分准备的,可参考博客
https://blog.csdn.net/Myuhua/article/details/81215209
三.安装hadoop
创建目录,将hadoop放入路径下

将下载好的hadoop,jdk传入虚拟机新创建的目录/opt/bigdata下
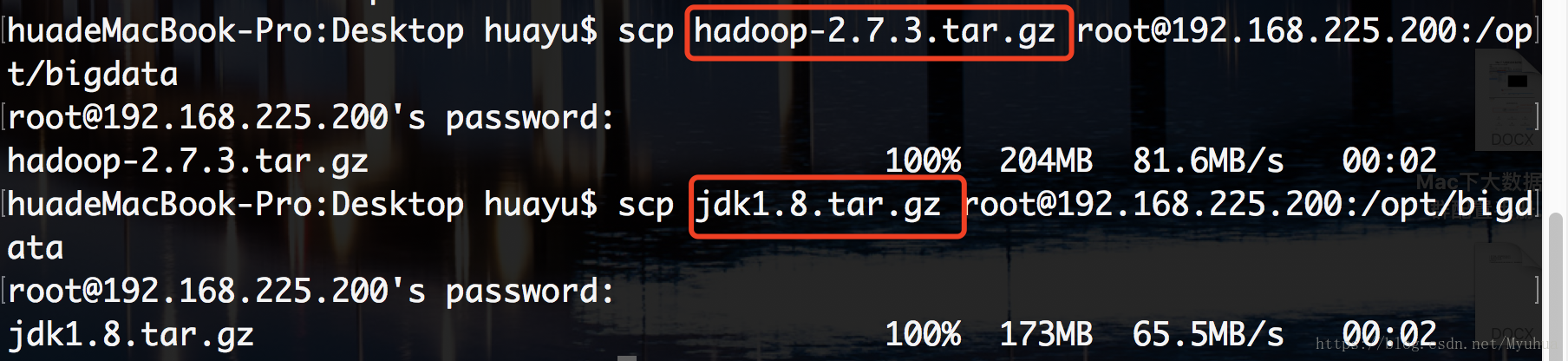
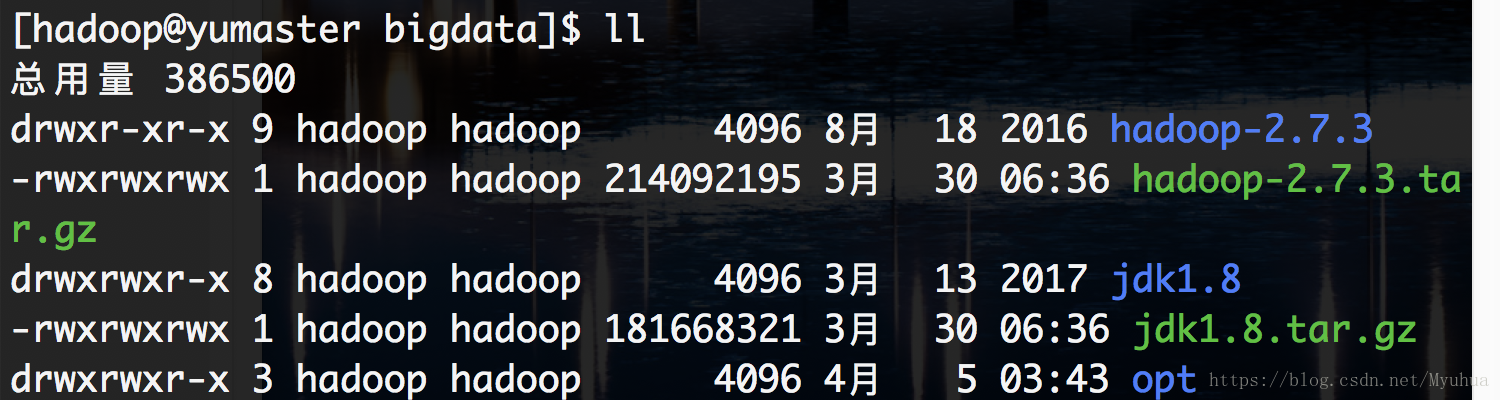
进到/opt/bigdata下看一看有没有传进去

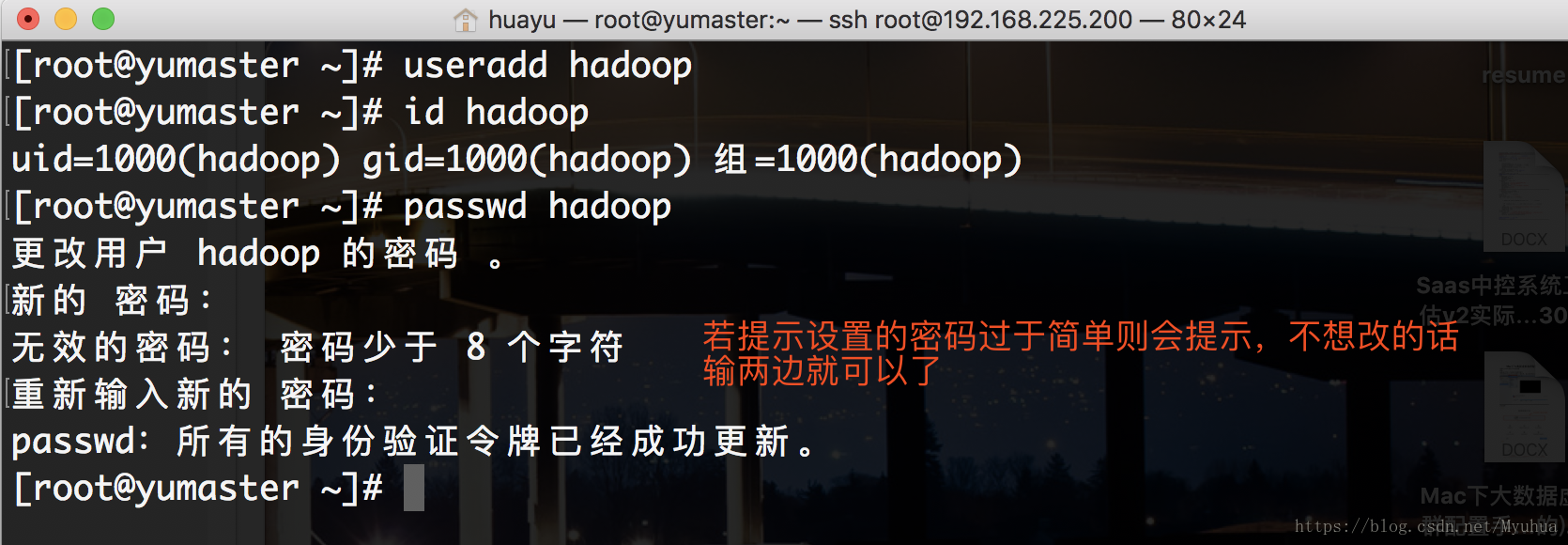
在master中创建用户hadoop
使用户成为sudoers,以root用户修改文件/etc/sudoers
[root@yumaster ~]# cd /opt/bigdata/
[root@yumaster ~]# vim /etc/sudoers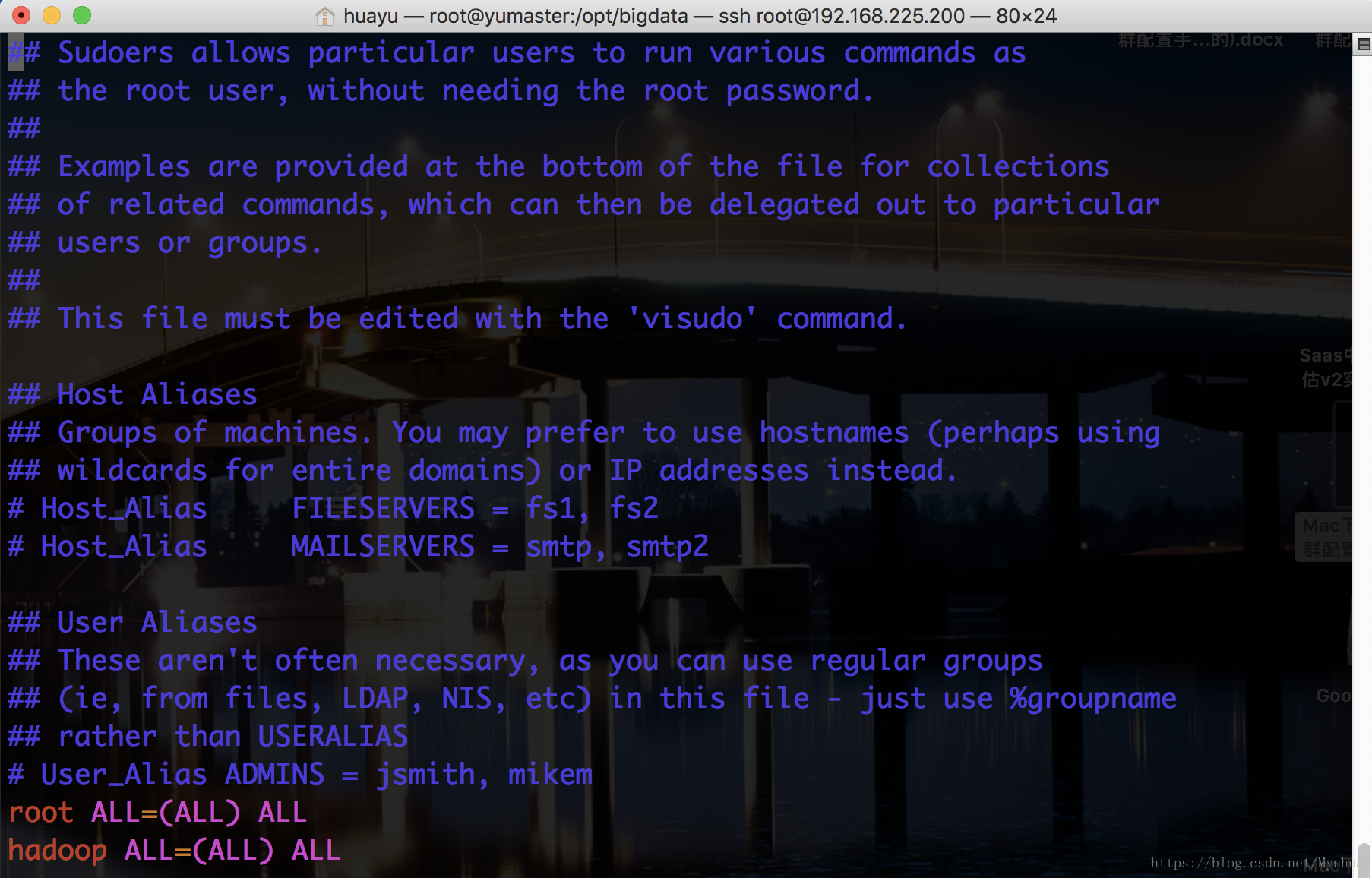
修改/opt/bigdata文件夹的权限



修改/etc/profile文件,配置java环境
sudo vim /etc/profile
#java configuration
JAVA_HOME=/opt/bigdata/jdk1.8
JAVA_BIN=/opt/bigdata/jdk1.8/bin
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export JAVA_HOME
export JAVA_BIN
export PATH
export CLASSPATH(注:上图中,JAVA_HOME 为你安装的 JDK 路径)
last but not least 最后一定要source一下使文件生效

配置完成查看一卡


在hadoop目录下创建tmp目录,并将权限设定为777

以 hadoop 用户配置如下10个文件(见附件)
core-site.xml
hdfs-site.xml
masters
slaves
yarn-site.xml
hadoop-env.sh
mapred-env.sh
yarn-env.sh
yarn-slaves
Hadoop 安装与配置
Hadoop 是大数据生态圈的基石,下面首先以 Hadoop 的安装与配置开始 。
进入安装目录
[hadoop@yumaster]$ cd /opt/bigdata/hadoop-2.7.3环境配置
[hadoop@yumaster hadoop-2.7.3]$ cd etc/hadoop/
[hadoop@yumaster hadoop]$ vim yarn-env.sh
# some Java parameters
export JAVA_HOME=/opt/bigdata/jdk1.8/
[hadoop@yumaster hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/opt/bigdata/jdk1.8
[hadoop@yumaster hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/bigdata/jdk1.8/core配置core-site.xml
[hadoop@yumaster hadoop]$ vim core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://yumaster:9000</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
hdfs配置
[hadoop@yumaster hadoop]$ vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/bigdata/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.web.ugi</name>
<value>hdfs,hadoop</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>yarn配置
[hadoop@yumaster hadoop]$ vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>yumaster</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>yumaster:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>yumaster:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>yumaster:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>yumaster:54315</value>
</property>
mapreduce 配置
[hadoop@yumaster hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@yumaster hadoop]$ vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>yumaster:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>yumaster:10020</value>
</property>slaves 配置(master、slave1 和 slave2 均作为 datanode)
vim slaves
yumaster
yuslave1
yuslave2配置系统环境 :在/etc/profile文件末尾再添加以下export两句
[hadoop@yumaster hadoop]$ sudo vim /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$PATH
[hadoop@yumaster hadoop]$ source /etc/profile //使配置生效3.克隆复制虚拟机
将虚拟机复制成 yuslave1 和 yuslave2 上。 (敲黑板:在克隆的时候一定要先给被克隆的那台关机,进入虚拟机poweroff关机,不是挂起!)

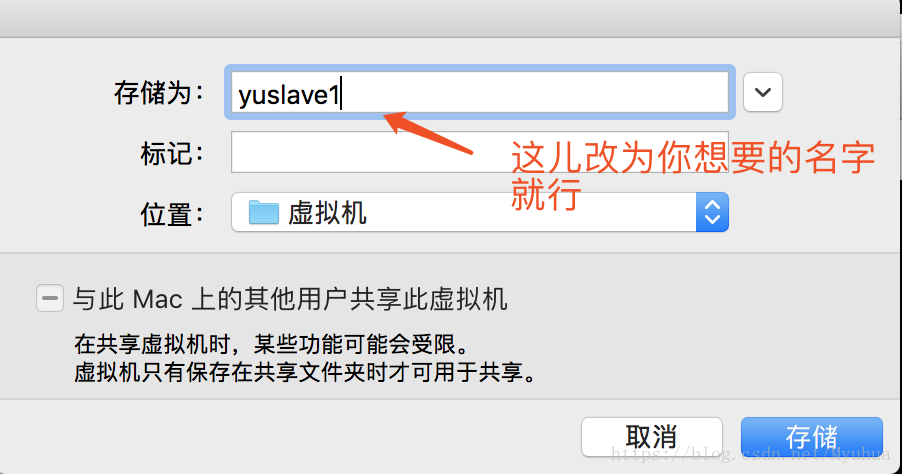
点击存储,第二台复制完成,同理,第三台虚拟机同样操作,至此虚拟机创建及复制完成
4.为新复制的yuslave1,yuslave2配置网络
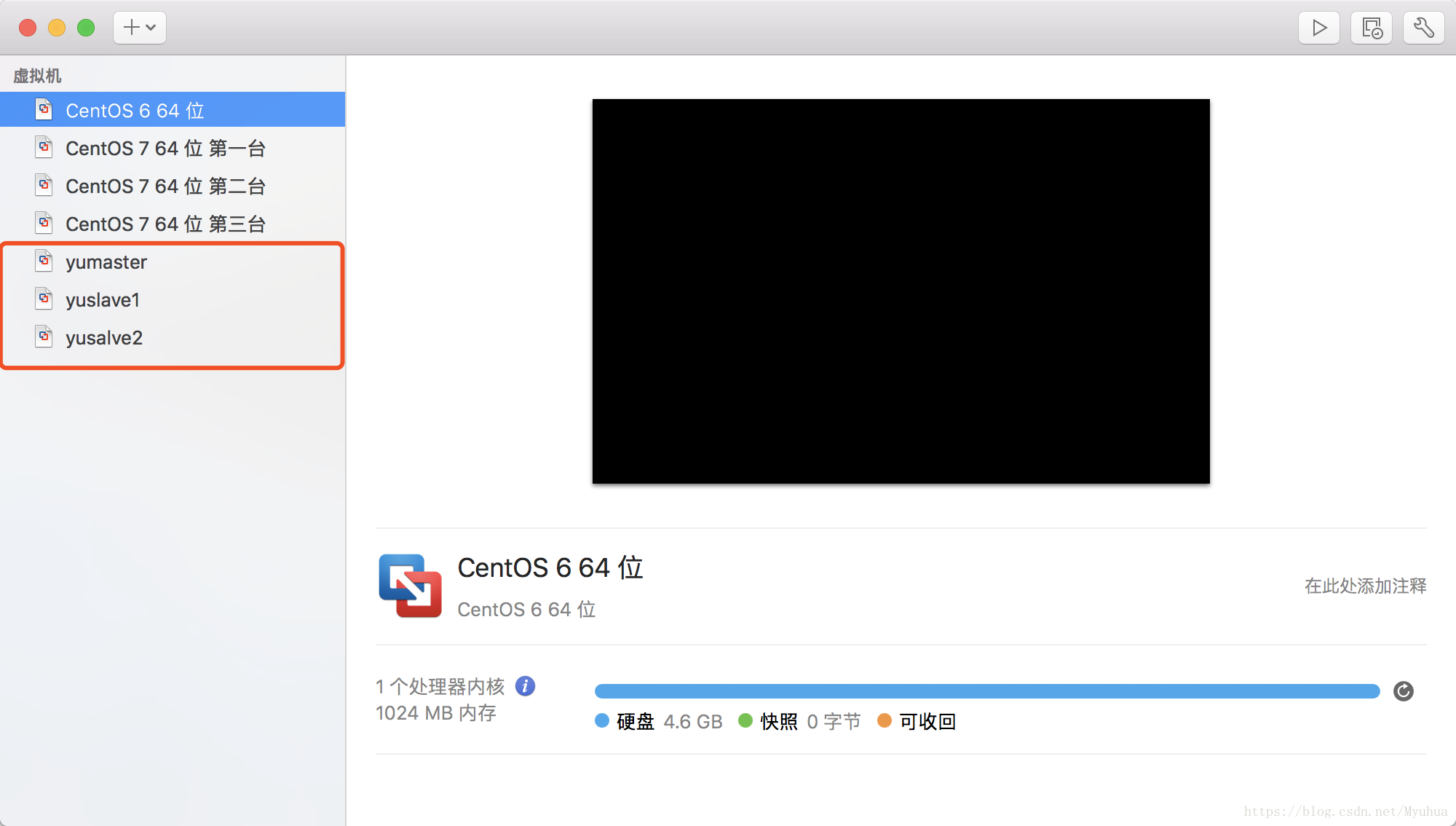


编辑ifcfg-eno16777736配置文件
[root@yumaster ~]# vim /etc/sysconfig/network-scripts/ifcfg-eno16777736
HWADDR=00:50:56:39:65:B2 //将刚生成的mac地址加入配置文件中
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=004fa506-6b5f-4772-b554-e1b6328ad157
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.225.201 //这儿改为yusalve1的ip192.168.225.201
NETMASK=255.255.255.0
GATEWAY=192.168.225.2
DNS1=114.114.114.114
DNS2=114.114.114.115
[root@yumaster ~]# systemctl restart network.service//重启网络然后修改主机名
[root@yumaster ~]# hostnamectl set-hostname yuslave1
[root@yumaster ~]# hostname yuslave1
[root@yumaster ~]# exit重新登陆
ping一下是否设置成功
[root@yuslave1 ~]# ping yuslave1
PING yuslave1 (192.168.225.201) 56(84) bytes of data.
64 bytes from yuslave1 (192.168.225.201): icmp_seq=1 ttl=64 time=0.016 ms
64 bytes from yuslave1 (192.168.225.201): icmp_seq=2 ttl=64 time=0.035 ms同理按照以上方法,配置好yuslave2
5.下面在hadoop用户下进行master和slave之间的免密
Master给自己和slave1,slave2发证书
[hadoop@yumaster ~]$ ssh-keygen
[hadoop@yumaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@yuslave1
[hadoop@yumaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@yuslave2
[hadoop@yumaster ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@yumaster下面用ssh localhost 登陆本机,若设置成功则无需输入密码了。
然后slave1给master发证书
[hadoop@yuslave1 ~]$ ssh-keygen
[hadoop@yuslave1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@yumaster然后slave2给master发证书
[hadoop@yuslave2 ~]$ ssh-keygen
[hadoop@yuslave2 ~]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@yumaster6.启动
首次启动之前格式化hdfs:
[hadoop@yumaster ~]$ hdfs namenode -format启动各组件
[hadoop@yumaster ~]$ cd /opt/bigdata/hadoop-2.7.3/sbin/方法一:全部启动
[hadoop@yumaster sbin]$ ./start-all.sh 验证
[hadoop@yumaster sbin]$ jps
2736 NameNode
3300 NodeManager
3399 Jps
2890 DataNode
3052 SecondaryNameNode
2079 ResourceManager
[hadoop@yuslave1 ~]$ jps
1621 DataNode
1848 Jps
1725 NodeManager
[hadoop@yuslave2 ~]$ jps
1760 NodeManager
1656 DataNode
1883 Jps方法二:分别启动
HDFS启动
[hadoop@yumaster sbin]$ ./start-dfs.sh 查看是否启动HDFS
(1)在浏览器里输入http://192.168.225.200:50070/
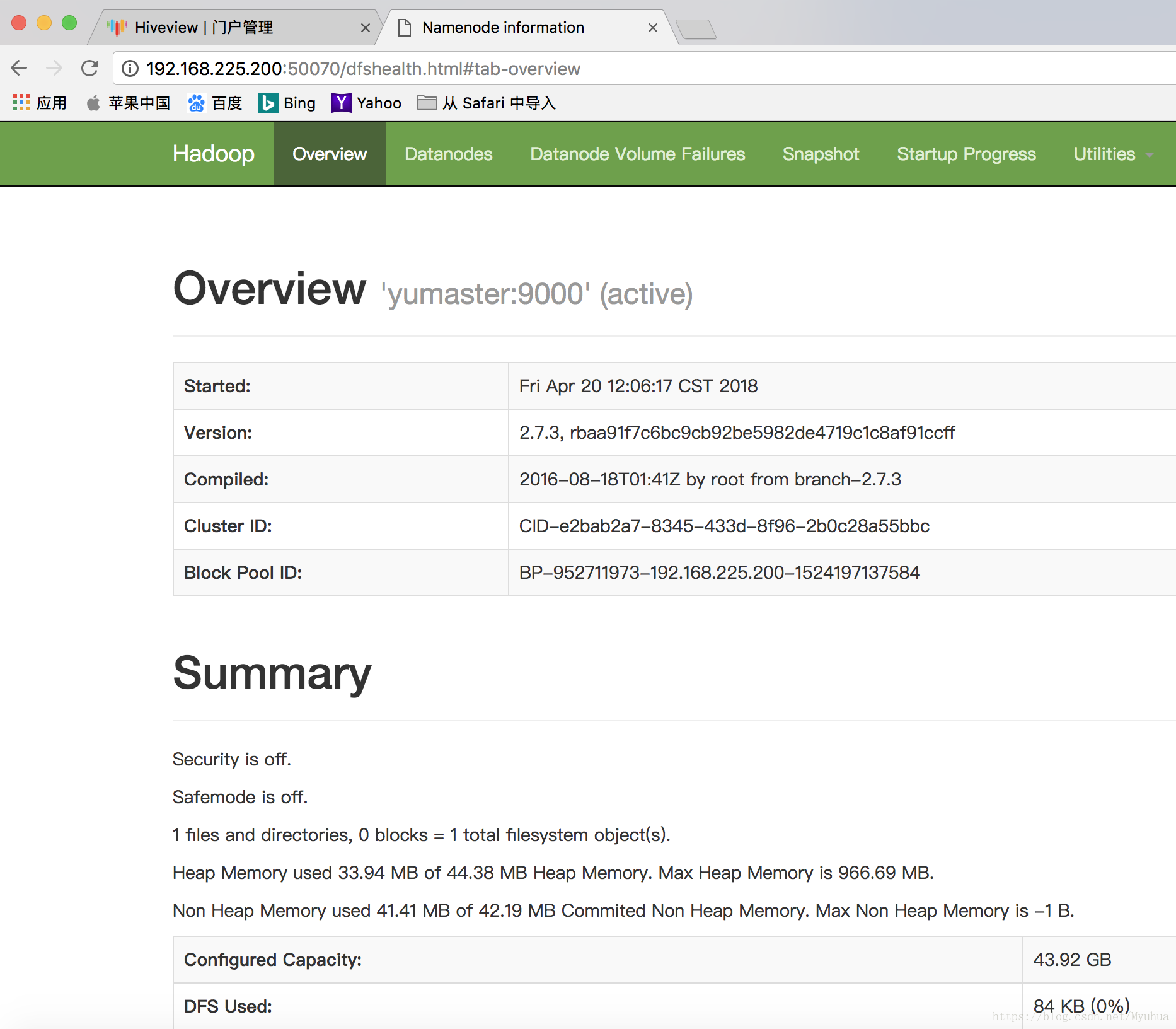
(2)jps查看
YARN启动
[hadoop@yumaster sbin]$ ./start-yarn.sh 查看YARN启动
[hadoop@yumaster sbin]$ ./start-yarn.sh (1)在浏览器中输入
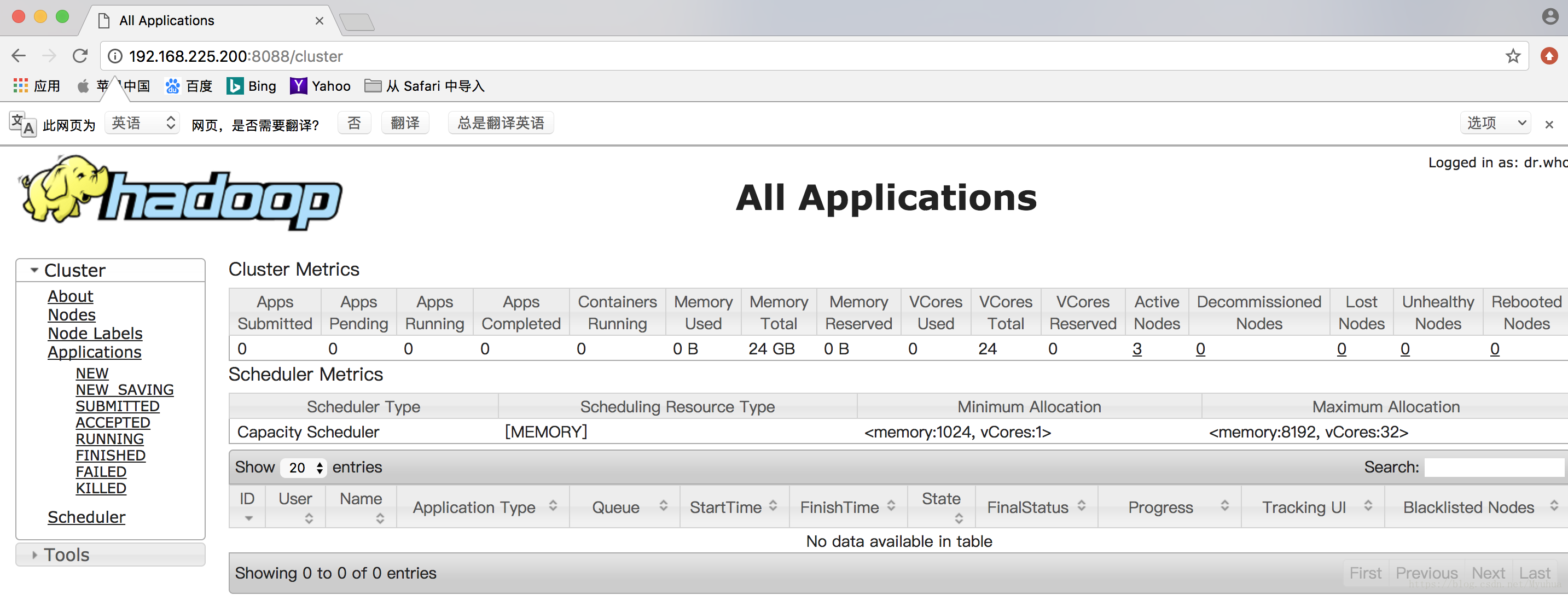
(2)jps查看
方法一:全部停止
[hadoop@yumaster sbin]$ ./stop-all.sh 方法二:分别停止
[hadoop@yumaster sbin]$ ./stop-yarn.sh
[hadoop@yumaster sbin]$ ./stop-dfs.sh 四.测试实验
[hadoop@yumaster ~]$ hadoop fs -mkdir /yu
[hadoop@yumaster ~]$ cd /opt/bigdata/hadoop-2.7.3
[hadoop@yumaster hadoop-2.7.3]$ hadoop fs -put LICENSE.txt /yu
[hadoop@yumaster ~]$ hadoop fs -ls /yu进行wordcount程序(可选)。一个统计文本单词个数的程序,它会统计放入文件夹内的文本的总共单词的出现个数
[hadoop@yumaster hadoop-2.7.3]$ hadoop fs -ls /yu //查看
Found 1 items
-rw-r--r-- 3 hadoop supergroup 84854 2018-04-20 12:49 /yu/LICENSE.txt
[hadoop@yumaster hadoop-2.7.3]$ cd /opt/bigdata/hadoop-2.7.3/share/hadoop/mapreduce/
[hadoop@yumaster mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /yu/output //执行程序
[hadoop@yumaster mapreduce]$ hadoop fs -ls /output //查看程序运行的输出文件
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-04-20 12:53 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 22002 2018-04-20 12:53 /output/part-r-00000
[hadoop@yumaster mapreduce]$ hadoop fs -cat /output/part-r-00000若有问题欢迎大家与我互动交流,可评论,可留言,希望我们大家能一起学习,共同进步。