PCA , principal component analysis, 即主成分分析算法, 是机器学习中一种常用的对训练样本进行降维的算法。具体推导过程这里不再赘述。简而言之,它是根据训练样本的特征(feature)分布特性,找到特征方差最大的特征向量组k,来替代原有的特征数n作为训练样本的表征(基),来重新描述训练样本,从而达到减少特征(即降低维度)目的。
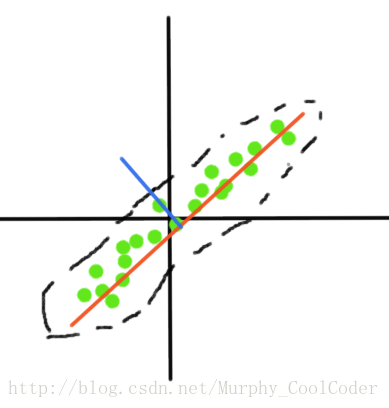
如上图所示,一组二维训练样本,其边界范围近似一个椭圆,该数据在椭圆长轴方向分布离散程度较大,即有较大的方差,而在短轴方向上分布离散程度较小,方差较小,可以理解为该组数据在长轴方向变化明显二短轴方向变化不明显,影响数据分布的主要因素是长轴方向分量,因此可以选择长轴方向的特征向量作为其新的基,将该数据投影到上面,即将原有的二维数据降低为一维数据。
PCA算法过程:
(1) Training set:
(2) 数据预处理,(feature scaling and mean normalization)
feature scaling :其中特征规模归一化不是必须项,如果训练样本不同特征之间差异较大,则有归一化的必要。如波士顿房价数据,特征”房间数目”和特征”房屋价格”差异较大,不利于后续的数据处理。因此可以用对应特征max-min value做为该特征归一化条件。若数据不同特征之间在数值意义上来说差异较小,则可以略过次步骤。
mean normalization: 这一操作必不可少,因为在后面的求协方差矩阵中均利用到了输入数据是零均值的这一特性。
(3)计算协方差矩阵 Sigma
其中
(4)奇异值分解
[U,S,V] = SVD(sigma)
其中,U即是我们所需要的特征向量组
(5)原始数据投影在
提示,由于这里的算法都是用矩阵运算,而且过程较多, 因此在程序的调试过程中很容易混乱,因此建议调试的时候遇到问题可以利用矩阵的角标分析,例如协方差矩阵是n*m 维的矩阵与m*n维的矩阵相乘,结果应为n*n维,
(二) 数据恢复
由以上算法我们可以得到,
根据线性代数知识,
(三)多说一点
有时候面对某一数据集,我们在调参时并不知道主成分k值的选取多少合适,吴恩达教授给出了一个方法,通常来说,我们选取K的原则是应该满足
[U,S,V] = SVD(sigma)
其中S是一个对角矩阵,主对角元素
利用得到的S计算这一指标。
源代码如下
测试用例有两个,其中一个是人脸图像数据,每张人脸大小32*32。数据地址https://pan.baidu.com/s/1kVpGkWv#list/path=%2F另外一个测试用例是python sklearn库自带的鸢尾花数据集。在程序末尾我注释掉了,如果想要调试的话拿掉即可。
需要注意的一点是,如果用自己的数据集特别是图像数据,在求SVD的时候,有的计算机由于内存问题计算出的特征向量U 结果均为0, sklearn库中也有人脸数据集,大小是64*64,我使用的电脑在面对计算4096*4096矩阵奇异值分解时,得到的特征向量U均为0,费了半天的功夫才发现是内存问题。因此在求特征向量时,面对维度较大的协方差矩阵可以使用用特征值分解函数。这里不再赘述。
import numpy as np
import matplotlib.pyplot as plt
from numpy import linalg as la
import scipy.io as sio
from sklearn.datasets import load_iris
class PCA:
def __init__(self,data,dim):
mean_data = np.mean(data, axis=0)
max_data = data.max(0)
min_data = data.min(0)
self.data = (data -mean_data)/(max_data -min_data)
self.row,self.col = [i for i in self.data.shape]
self.dim = dim
def dimReducation(self):
X = self.data
covMatrix = np.dot(X.transpose(),X)/self.row
U,S,V = la.svd(covMatrix)
U_reduce = U[:,:self.dim]
return U_reduce
def reConstruct(self,U_reduce,Z):
data_approx = np.dot(U_reduce,Z)
return data_approx.T
if __name__=='__main__':
#人脸数据测试用例
face = sio.loadmat('ex7faces.mat')
data = face['X']
plt.figure(1)
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(data[i, :].reshape(32, 32).T, cmap="gray")
test = PCA(data,100)
featureVector= test.dimReducation()
plt.figure(2)
for i in range(36):
plt.subplot(6, 6, i + 1)
plt.imshow(featureVector[:,i].reshape(32, 32).T, cmap="gray")
data_reduce = np.dot(featureVector.T,data.T).T
z = np.dot(featureVector.T,data.T)
rebuildFace = test.reConstruct(featureVector,z)
plt.figure(3)
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(rebuildFace[i, :].reshape(32, 32).T, cmap="gray")
plt.show()
#鸢尾花测试用例
'''data = load_iris()
yLabel = data.target
X = data.data
test = PCA(X, 2)
U_reduce = test.dimReducation()
X_reduce = np.dot(U_reduce.T,X.T).T
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
for i in range(len(X_reduce)):
if yLabel[i] == 0:
red_x.append(X_reduce[i][0])
red_y.append(X_reduce[i][1])
elif yLabel[i] == 1:
blue_x.append(X_reduce[i][0])
blue_y.append(X_reduce[i][1])
else:
green_x.append(X_reduce[i][0])
green_y.append(X_reduce[i][1])
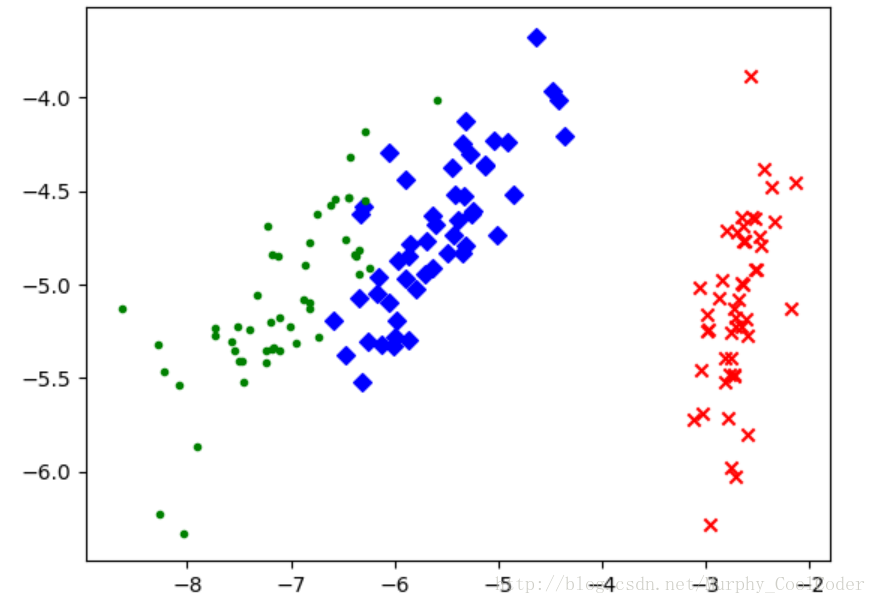
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()'''人脸数据调试结果,
1.原始数据
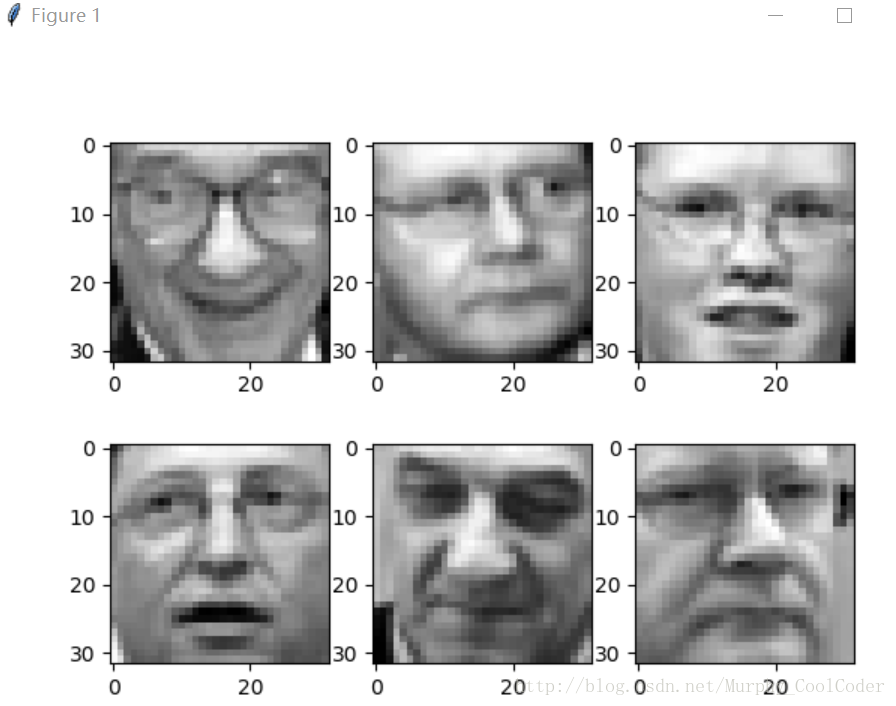
人脸数据集的主成分,程序中选取了前36个主成分进行展示, ,即

复原后的图像

鸢尾花数据调试结果:将原本4维的数据集,无法展示,利用PCA降至二维空间,以便数据展示。这也是PCA用途之一,即数据可视化。可以看出,降维之后的数据分布以并没有改变