KNN学习(K-Nearest Neighbor algorithm,K最邻近方法)是一种统计分类器,属于惰性学习,对包容型数据的特征变量筛选尤其有效。KNN的基本思想是:输入没有标签即未经分类的新数据,首先提取新数据的特征并与测试集中的每一个数据特征进行比较;然后从样本中提取k个最邻近(最相似)数据特征的分类标签,统计这K个最邻近数据中出现次数最多的分类,将其作为新数据的类别。
一、KNN算法
KNN按一定的规则,将相似的数据样本进行归类。首先,计算待分类数据特征与训练数据特征之间的距离并排序,取出距离最近的k个训练数据集特征;然后,根据这k个相近训练数据特征所属的类别来判定新样本的类别:如果它们都属于同一类,那么新样本也属于这一类;否则,对每个候选类别进行评分,按照某种规则确定新样本的类别。
一般采用投票规则,即少数服从多数,期望的k值是一个奇数。精确的投票方法是计算每一个测试样本与k个样本之间的距离。
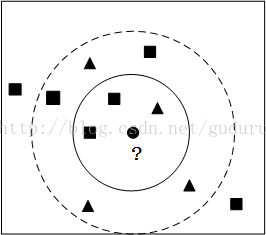
如下图小圆形要被归为哪一类,是三角形还是矩形?如果k = 3,由于矩形所占比例为2/3,小圆形将被归为矩形一类;如果k = 9, 由于三角形比例为5/9,因此小圆形被归为三角形一类。
假设数据集为:
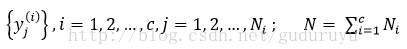
这些数据分别属于c种不同类别,其中Ni是第i个分类wi的样本个数。对于一个待测数据x,分别计算它与这N个已知类别的样本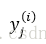
wi类的判决函数为:

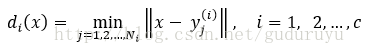
判决规则为:
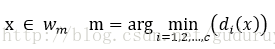
上述方法仅根据距离待识模式最近的一个样本类别决定其类别,称为最邻近法或1-邻近法。
为了克服单个样本类别的偶然性,增加分类的可靠性,可以考察待测数据的k个最邻近样本,统计这k个最邻近样本属于哪一类别的样本最多,就将x归为该类。
设k1, k2, ..., kc分别是x的k个样本属w1, w2, ..., wc的样本数,定义wi的判决函数为:
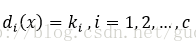
判决规则为:
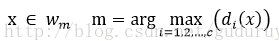
该方法称为k邻近算法,即KNN学习。
在样本数有限的情况下,KNN算法的误判概率和具体测测度有直接的关系,因此在选择最近样本数时利用适当的距离函数,能够提高分类的正确率。通常KNN可采用Euclidean,Manhattan,Mahalanobis等距离用于计算。
Euclidean距离为:

Manhattan距离为:

Mahalanobis距离为:
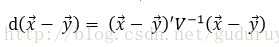
其中,n为输入特征的维数,V是x和y所在数据集的协方差函数。
二、回归
得到k个最相似训练数据后,求取这些训练数据属性的平均值,并将该平均值作为待处理数据的属性值,这一求取待处理数据属性的过程被称为KNN学习回归。
进一步地,根据每一个最相似训练数据和待处理数据的实际距离,赋予每一个最相似训练数据不同的权值,然后再进行加权平均,这样得到的回归值更为有效。
三、算法改进
KNN学习易受噪声影响,尤其是样本中孤立点对分类或回归处理的影响较大。因此通常应先对已知样本进行滤波和筛选,去除掉对分类有干扰的样本。
1、基于组合分类器的KNN改进算法
常用的组合分类器方法有投票法、非投票法、动态法和静态法等,如简单投票法中所有的基分类器对分类采用相同的权值;权值投票法中每个基分类器具有相关的动态权重,该权重可以随时间变化。
首先随机选择属性子集,构建多个k邻近分类器,然后对未分类元组进行预分类;最后把分类器的分类结果按照投票法进行组合,将得票最多的分类器结果作为最终组合邻近分类器的输出。
2、基于核映射的KNN改进算法
将原空间
首先,进行非线性映射:
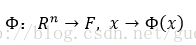
然后,在高维的核空间,待分类的样本变为
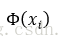

其中K(*,*)为核函数,在此基础上进行KNN分类。
3、基于预聚类的KNN改进算法
这里定义C为全体数据集合,N代表确定的临近点的集合,I为最近间隔,P为竞争点集,即可能成为临近点的集合。
首先计算聚类后指定点x到每个聚类中心的距离d,如下图所示,根据这些距离,离x最近的的聚类为C0,下一个较近的聚类为C1,一次类推。

然后,将聚类C0中的所有点加入到P中,计算P中所有点与x的距离,将满足条件的点转移到集合N中,这样临近点的搜索区域就可以被大致定位了。
4、基于超球搜索的KNN改进算法
通过对特征空间的预组织,使分类在以待分样本为中心的超球内进行,超球半径由0开始,逐渐增大至超球内包含K个以上模式样本为止。超球搜索分为两个阶段:第一阶段为组织阶段,将模式空间进行有效的划分和编码;第二阶段为搜索判决阶段,找出待识样本的K邻近。
首先将n维模式空间划分成若干个体积相等的超立方体(基元超立方体),并依次编码;然后在以待分样本为中心的超球体内(由若干个基元超立方体覆盖)进行搜索,逐渐扩大超球半径直至超球内包含K个样本为止;然后该超球内的KNN即为整个空间内的K邻近。
附KNN算法C语言实现示例:
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#define M 4000
#define N 100
//定义一个字符的结构体
struct letter
{
char c;
int array[16];
float distance;
};
//定义训练字符结构体数组,共有M个训练样本
letter letters[M];
//识别字符类数组,共有N个对比样本
letter nletters[N];
float t;
//定义读取训练文件函数,将训练样本从磁盘文件letter.txt读入letters[M]数组中
void Get_from_letters()
{
FILE *fp;
int i,j;
fp=fopen("letter.txt","r");
for(i=0; i<M; i++)
{
fscanf(fp,"%c ",&letters[i].c);
for(j=0; j<16; j++)
fscanf(fp,"%d ",&letters[i].array[j]);
}
fclose(fp);
}
//定义读取测试文件,将测试样本从磁盘文件素描sum1.txt读入到nletters中
void Get_from_nletters()
{
int i,j;
FILE *fp;
fp=fopen("sum.txt","r");
for(i=0; i<N; i++)
{
fscanf(fp,"%c ",&nletters[i].c);
for(j=0; j<16; j++)
fscanf(fp,"%d ",&nletters[i].array[j]);
}
fclose(fp);
}
//定义欧式距离函数,计算一个测试样本与各个训练样本之间的距离
void Distance(letter *p)
{
int i,j;
float s=0.0;
for(i=0; i<M; i++)
{
for(j=0; j<16; j++)
{
s+=((letters[i].array[j]-(*p).array[j])*(letters[i].array[j]-(*p).array[j]));
}
letters[i].distance=sqrt(s);
//恢复到原始值
s=0.0;
}
}
//排序函数将letters距离按由小到大排列
void Sort()
{
int i,j;
letter t;
for(i=0; i<M-1; i++)
{
for(j=i+1; j<M; j++)
{
if(letters[i].distance>letters[j].distance)
{
t=letters[i];
letters[i]=letters[j];
letters[j]=t;
}
}
}
}
//根据用户输入的k值,确定分类
char Knn(int q)
{
int i,j,max;
int array[26];
for(i=0; i<26; i++)
{
array[i]=0;
}
for(i=0; i<q; i++)
{
switch(letters[i].c)
{
case'A':
array[0]++;
break;
case'B':
array[1]++;
break;
case'C':
array[2]++;
break;
case'D':
array[3]++;
break;
case'E':
array[4]++;
break;
case'F':
array[5]++;
break;
case'G':
array[6]++;
break;
case'H':
array[7]++;
break;
case'I':
array[8]++;
break;
case'J':
array[9]++;
break;
case'K':
array[10]++;
break;
case'L':
array[11]++;
break;
case'M':
array[12]++;
break;
case'N':
array[13]++;
break;
case'O':
array[14]++;
break;
case'P':
array[15]++;
break;
case'Q':
array[16]++;
break;
case'R':
array[17]++;
break;
case'S':
array[18]++;
break;
case'T':
array[19]++;
break;
case'U':
array[20]++;
break;
case'V':
array[21]++;
break;
case'W':
array[22]++;
break;
case'X':
array[23]++;
break;
case'Y':
array[24]++;
break;
case'Z':
array[25]++;
break;
}
}
max=array[0];
j=0;
for(i=0; i<26; i++)
{
if(array[i]>max)
{
max=array[i];
j=i;
}
}
return (char)(j+65);
}
//主函数
int main()
{
int i,j,k=0;
int m=0,n=0;
letter * p;
char c;
printf("训练样本为%d\n",M);
Get_from_letters();
printf("测试样本为%d\n",N);
Get_from_nletters();
printf("请输入K值:\n");
scanf("%d",&k);
for(i=0; i<N; i++)
{
p=&nletters[i];
Distance(p);
Sort();
c=Knn(k);
if(nletters[i].c==c)
{
printf("该字符属于%c类,识别正确\n",nletters[i].c);
m++;
}
else
{
printf("该字符属于%c类,识别错误\n",nletters[i].c);
n++;
}
printf("%f",letters[0].distance);
}
printf("正确个数为%d",m);
printf("错误个数为%d",n);
printf("正确率为%f",(float)(m)/N);
scanf("%d",&i);
return 0;
}2017.11.20