复制链接
本文参考CSDN大神的博文,并在讲述中引入自己的理解,纯粹理清思路,并将代码改为了Python版本。(在更改的过程中,一方面理清自己对GMM的理解,一方面学习了numpy的应用,不过也许是Python粉指数超标才觉得有必要改(⊙o⊙))
一、GMM模型
事实上,GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来(所以 GMM 除了用在 clustering 上之外,还经常被用于 density estimation ),简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。
得出一个概率有很多好处,因为它的信息量比简单的一个结果要多,比如,我可以把这个概率转换为一个score,表示算法对自己得出的这个结果的把握,参考pluskid大神博文。
- 也许我可以对同一个任务,用多个方法得到结果,最后选取“把握”最大的那个结果;
- 另一个很常见的方法是在诸如疾病诊断之类的场所,机器对于那些很容易分辨的情况(患病或者不患病的概率很高)可以自动区分,而对于那种很难分辨的情况,比如,49% 的概率患病,51% 的概率正常,如果仅仅简单地使用 50% 的阈值将患者诊断为“正常”的话,风险是非常大的,因此,在机器对自己的结果把握很小的情况下,会“拒绝发表评论”,而把这个任务留给有经验的医生去解决。
每个GMM由K个Gaussian分布组成,每个Gaussian称为一个“Component”,这些Component线性加成在一起就组成了GMM的概率密度函数:

根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。
那么如何用 GMM 来做 clustering 呢?其实很简单,现在我们有了数据,假定它们是由 GMM 生成出来的,那么我们只要根据数据推出 GMM 的概率分布来就可以了,然后 GMM 的 K 个 Component 实际上就对应了 K 个 cluster 了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。
二、参数与似然函数
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x)),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于 ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和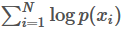
,得到log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
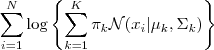
由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,我们采取之前从 GMM 中随机选点的办法:分成两步,实际上也就类似于K-means 的两步。
三、算法流程
1、估计数据由每个 Component 生成的概率(并不是每个 Component 被选中的概率):对于每个数据 xi 来说,它由第 k 个 Component 生成的概率为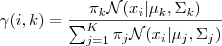
其中N(xi|μk,Σk)就是后验概率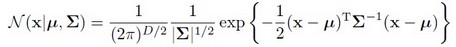
2、通过极大似然估计可以通过求到令参数=0得到参数pMiu,pSigma的值。
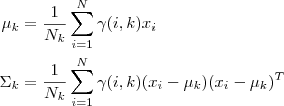
其中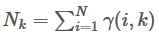 并且
也顺理成章地可以估计为
(这里的顺理成章要考证起来有很多要说)
并且
也顺理成章地可以估计为
(这里的顺理成章要考证起来有很多要说)
3、重复迭代前面两步,直到似然函数的值收敛为止。
声明:这里完全可以对照EM算法的两步走,对应关系如下:
- 均值和方差对应θ
- Component 生成的概率为隐藏变量
- 最大似然函数L(θ)=

四、GMM聚类代码
在这里插入代码片