加载R包和数据集
上述症状数据集包含在R-package 中,并在加载时自动可用。 加载包后,我们将此数据集中包含的12个心情变量进行子集化:
对象mood_data是一个1476×12矩阵,测量了12个心情变量:
![]()

![]()

time_data包含有关每次测量的时间戳的信息。 下一节中的数据预处理需要此信息。
![]()

该数据集中的一些变量是高度偏斜的,这可能导致不可靠的参数估计。 在这里,我们通过计算自举置信区间(KS方法)和可信区间(GAM方法)来处理这个问题,以判断估计的可靠性。 由于本教程的重点是估计时变VAR模型,因此我们不会详细研究变量的偏度。 然而,在实践中,应该在拟合(时变)VAR模型之前始终检查边际分布。
估计时变VAR模型
通过参数lags = 1,我们指定拟合滞后1 VAR模型,并通过lambdaSel =“CV”选择具有交叉验证的阴茎参数λ。 最后,使用参数scale = TRUE,我们指定在模型拟合之前,所有变量都应缩放为零和标准差1。 当使用“1正则化”时,建议这样做,因为否则参数惩罚的强度取决于预测变量的方差。 由于交叉验证方案使用随机抽取来定义折叠,因此我们设置种子以确保重现性。
在查看结果之前,我们检查了1476个时间点中有多少用于估算,这在调用控制台中的输出对象时打印的摘要中显示
![]()

估计的VAR系数的绝对值存储在对象tvvar_obj $ wadj中,该对象是维度p×p×滞后×estpoints的数组。 例如,条目tvvar_obj $ wadj [1,3,1,9]在时间点9返回变量3的变量3的交叉滞后效应和第一个指定的滞后大小(此处为1)。由于大量的 估计参数,我们在这里没有显示这个对象,而是在图11中可视化它的一些方面。所有参数的符号分别存储在tvvar_obj $符号中,因为在存在分类变量时可能无法定义符号(这不是 这里的情况)。 拦截存储在tvvar_obj $ intercepts中。
参数估计的可靠性
![]()

res_obj $ bootParameters包含每个参数的经验采样分布。 例如,数组条目res_obj $ bootParameters [1,3,1,9,]包含变量3在时间点9的第一个指定滞后大小(此处为1)的变量1的交叉滞后效应的采样分布。 由于它的大小,我们在这里没有显示这个对象,但显示了图11中三个时变参数的经验采样分布的5%和95%分位数。重要的是要记住这些自举采样的分位数 分布不是真实参数周围的置信区间。 原因是“1 - 惩罚”使所有估计偏差,因此整个采样分布趋于零,这意味着后者不以真实参数值为中心。
计算时变预测误差
函数predict()计算给定mgm模型对象的预测和预测误差。 我们首先提供模型对象object = tvvar_obj和数据data = mood_data。 然后我们指定所需的预测类型,这里R2代表解释变量的比例,RMSE代表均方根误差。 tvMethod =“weighted”指定如何组合所有时变模型以在整个时间序列中为每个变量得出单个预测(有关详细信息,请参阅“预测”)。 最后,我们提供consec = time_data $ beepno,原因与上述相同。
![]()

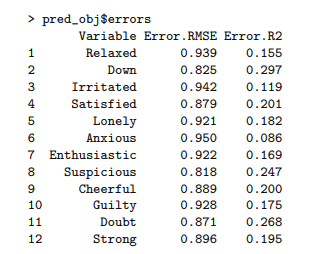
预测存储在pred_obj $预测中,并且所有时变模型的预测误差组合在pred_obj $错误中:
![]()
可视化时变VAR模型


图 显示了上面估计的时变VAR参数的一部分。 顶行显示估计点8,15和18的VAR参数的可视化。蓝色实线箭头表示正关系,红色虚线箭头表示负关系。 箭头的宽度与相应参数的绝对值成比例
还有问题吗?联系我们!
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() QQ:3025393450
QQ:3025393450


![]()
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务
![]()
