文章主要是总结一学期所学,基本
覆盖了所有常见的指令,足够完成arima模型的数据选择到模型预测。
时间序列应用广泛,不能仅仅局限于理论学习,代码实践更为重要。
往期文章链接:
基于 ARIMA-GARCH 模型人名币汇率分析与预测[论文完整][2020年]
文章目录
1 安装包指令
install.packages("tseries")
install.packages("forecast")
2 加载包指令
说明:载入一个包之后,就可以使用一系列新的函数和数据集了。包中往往提供了演示性的小型数据集和示例代码,能够让我们尝试这些新功能
library(tseries)
library(forecast)
3 help指令的使用
说明:使用函数help()可以查看其中任意函数或数据集的更多细节
help(package="tseries")
4 读取不同格式数据
4.1 读取csv格式的数据
data<-read.csv("路径",header=F,sep=",")
4.2 读取txt格式的数据
data<-read.table("路径",header=F,sep=",")
4.3 读取xls和xlsx格式的数据
可以统一将数据文件格式转成csv进行处理
4.4 参数使用
路径(注意反斜杠的方向)
E:/大三上课程/时间序列.csv
E:/大三上课程/时间序列.txt
heaer
这是一个逻辑值,T or F 反映文件的第一行是否包含变量名
sep
文件中的字段分隔符,例如对用制表符分割的文件使用sep="\t"
5 ts生成时间序列的对象
5.1 时间间隔为年的情况
ts(data$V1,frequency = 1,start=c(1975))
frequent=1表示以年为单位间隔 start说明了数据从1975年开始
5.2 时间间隔为月的情况
ts(data$V1,frequency = 12,start=c(1975,1))
frequent=12表示以月为单位间隔 start说明数据从1975年1月开始

5.3 时间间隔为日的情况
ts(data$V1,frequency = 365,start=c(1975,1,1))
frequent=365表示以日为单位间隔 start说明数据从1975年1月1日开始
5.4 参数使用
data
这个必须是一个矩阵,或者向量,再或者数据框frame
补充 :data$v1 表示数据源的第一排 v2表示第二排 容易遗漏
Frequency
这个是时间观测频率数,也就是每个时间单位的数据数目
Start
时间序列开始值(是一个向量),允许第一个个时间单位出现数据缺失
6 plot绘制时间序列的折线图
plot基本用法
plot(x=x轴数据,y=y轴数据,main="标题",sub="子标题",type="线型",xlab="x轴名称",ylab="y轴名称",xlim = c(x轴范围,x轴范围),ylim = c(y轴范围,y轴范围))
实例演示
ts_1<-ts(data$V1,frequency = 365,start=c(1975,1,1))
plot(ts_1,main="ceshi",ylab="大小",xlab="时间",ylim=(-3:3))
7 平稳性检验的三种方式
7.1 图检法
通过plot()绘制时间序列的时序图,如果序列是平稳的,那么序列应该是围绕一个均值上下随机波动。如果序列呈现递增递减则不是平稳时间序列。
如下图时序图无明显趋势,在一个值上下波动,初步判断为平稳序列。

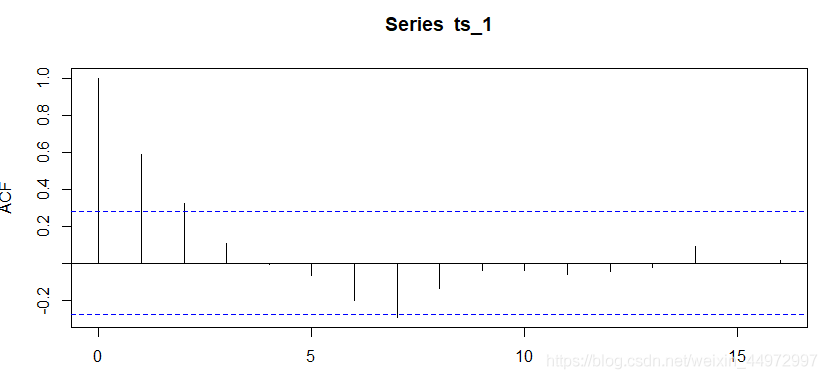
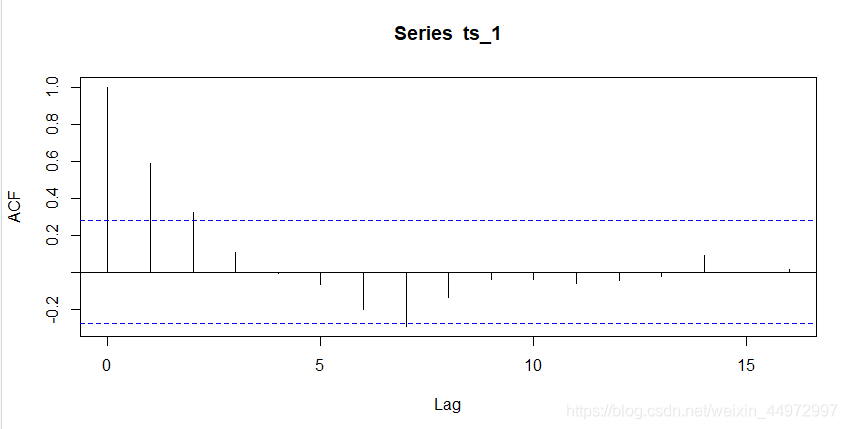
7.2 通过acf自相关系数图
对于平稳时间序列,其自相关图一般随着阶数的递增,自相关系数会迅速衰减至0附近,而非平稳时间序列则可能存在先减后增或者周期性波动等变动。如下图所示,该时间序列随着阶数的递增迅速衰减至0附近,因此,可以判断该时间序列不是平稳时间序列。
acf(ts_1)
7.3 通过adf函数p值判断(不需要主观判断)
#使用前要加载包 ts_1是通过ts生成的时间序列(不清楚看前面)
install.packages("tseries")
library(tseries)
adf.test(ts_1)
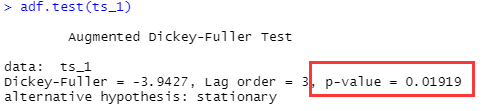
p值为0.02547小于显著性水平0.05接受备择假设,为平稳序列。若p值大于0.05则为非平稳性检验
8 白噪声(纯随机)检验的方式
#其中ts_1是通过ts做出的时序序列,for循环是为了多判断几期p值的判断。
#一般我们判断前12期的p值,期数越大越不容易小于0.05。
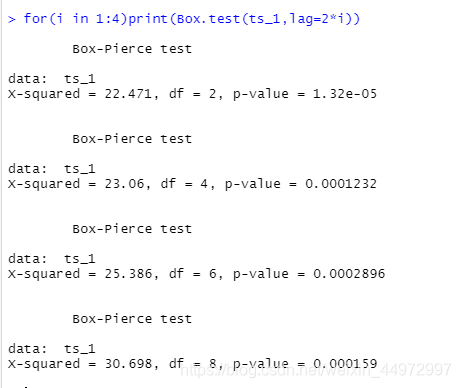
for(i in 1:4)print(Box.test(ts_1,lag=2*i))
当p值都小于0.05,我们接受备择假设,该序列为非随机序列。
当p值大于0.05,我们选择原假设,该序列为 纯随机序列。
例如下,p值都小于0.05判断为非随机序列。如果为随机序列则数据之间无关联,只能进行差分或者放弃。
9 绘制自相关系数图和偏自相关系数图
自相关系数图acf
acf(ts_1)
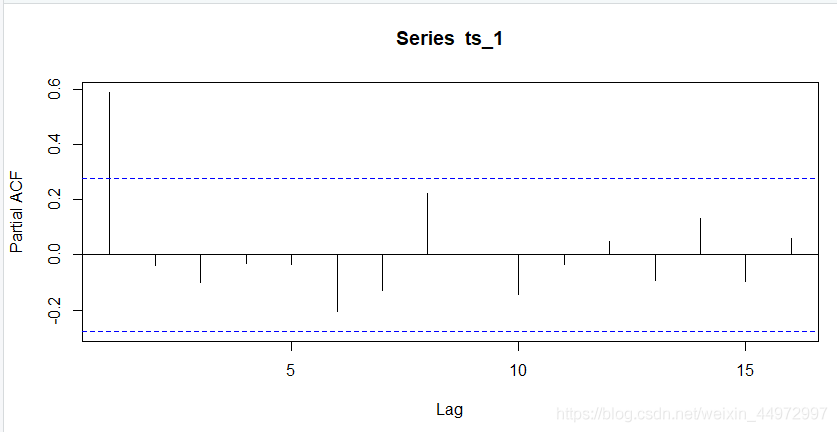
偏自相关系数pacf
pacf(ts_1)
补充
下面指令可以将直接做出时序图,acf,pacf
tsdisplay(ts_1)
10模型选择及其定阶
10.1通过acf图和pacf图
-
若PACF序列满足在p步截尾,且ACF序列被负指数函数控制收敛到0,则Yn为AR§序列。
-
若ACF序列满足在q步截尾,且PACF序列被负指数函数控制收敛到0,则Yn为MA(q)序列
。 -
若ACF序列和PACF序列满足皆不截尾,但都被负指数函数控制收敛到0,则Yn为ARMA序列。
当我们选择好模型可以通过如下指令进行构建模型
#其中p表示AR的阶数 d表示差分的次数 q表示MA的阶数
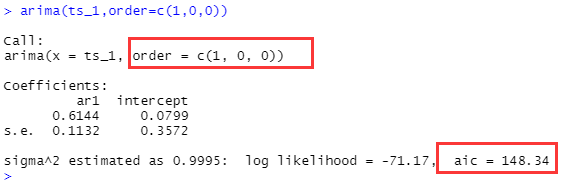
all<-arima(ts_1,order=c(p,d,q))
all
10.2通过auto.arima()自动选择
# 无特殊要求使用默认参数即可
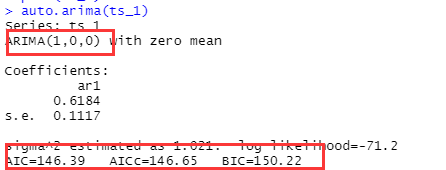
auto.arima(ts_1)
如下函数为我们选择的是AR(1) ,aic aicc bic都是用来判断模型的好坏的准则,后面具体说明。
11AIC,BIC准则判断模型好坏
AIC
AIC = -2In(L) + 2k
其中L指对应的最大似然函数,k指对应的模型的变量的个数。
BIC
BIC = -2In(L) + In(n)*k
n指对应的数据数量,L和k同上所述。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
AIC,BIC越小越好
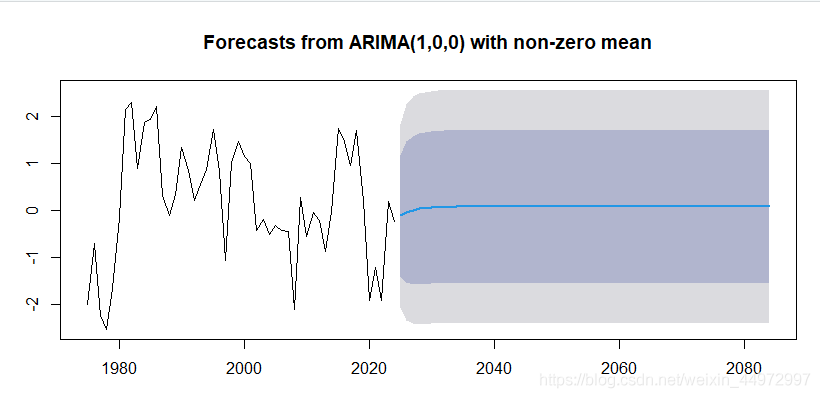
12 foreca进行模型预测
# all表示模型 all<-arima(ts_1,order=c(1,0,0))
# 60表示预测接下来的60个值
library(forecast)
plot(forecast(all,60))#绘制图形
forecast(all,60) #显示所有预测值
13 差分命令
#s1 表示差分后新的序列
#data$v1表示数据源的第一列,也就是要进行操作的数据
#1表示差分一次
s1<-diff(data$v1,1)
14 差分命令
15 完整操作流程图

总结
最后希望给文章
点个赞,整理不易!!!
最后希望给文章点个赞,整理不易!!!
最后希望给文章点个赞,整理不易!!!
如果有错误可以评论私信。
如有需要完整论文及代码数据便于参考学习可评论、私信。
