上一篇文章记录了caffe-ssd安装过程中的坑和解决办法,https://blog.csdn.net/lukaslong/article/details/81390276
接下来分三部分,分别介绍如何用配置好的caffe-ssd训练VOC数据及自己的数据集
第一部分,训练VOC数据集
1. 预训练模型
caffe-ssd作者提供了预训练模型,下载地址https://gist.github.com/weiliu89/2ed6e13bfd5b57cf81d6
下载完成后保存在 caffe/models/VGGNet 中
2. 下载VOC2007和VOC2012数据集:
在home根目录下创建文件夹data,即/home/×××/data/
cd data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar如果终端下载速度太慢,也可以到相应网站自行下载,然后放到data/文件夹内,进行解压。
可以得到home/.../data/VOCdevkit/文件夹,包含VOC0712、VOC2007、VOC2012三个子文件夹
3. 创建lmdb文件
VOC的数据及标注是不能直接拿来训练的,先要进行格式转换,创建train和test的lmdb文件:
cd caffe
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh4. 开始训练
python examples/ssd/ssd_pascal.py该训练文件中默认使用的是4块GPU,如果只用一块GPU,则需要打开文件修改
gpus = "0,1,2,3"
修改为:
gpus = "0"第二部分:训练自己的数据集
其实存在两种方案, 第一:保持原来的文件目录结构及文件名不变, 只替换里面的数据。第二:重新新建一个与之前类似的目录结构,改成自己命名的文件夹,需要修改程序里涉及数据路径的代码,但是方法更重要,因此这里采用第二种方案。
1. 准备工作
以下没有cd到特定路径的情况下,默认路径为cd home/.../caffe/
1.1 创建文件夹
cd caffe/data/
mkdir mydataset把caffe/data/VOC0712/目录下create_list.sh 、create_data.sh、labelmap_voc.prototxt 这三个文件拷到caffe/data/mydataset/下,可手动复制也可以通过命令进行:
cd caffe/data/
cp VOC0712/create* ./mydataset
cp VOC0712/label* ./mydataset1.2 修改label类别
labelmap_voc.prototxt文件定义了检测中的label,打开进行标签的设置,label0要保留,从label1开始修改自己要检测的label名称,删除用不着的。注意这里的name一定要和xml中的标注完全相同。
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "aeroplane"
label: 1
display_name: "person"
}
...1.3 数据集准备
在/data/VOCdevkit目录下创建mydataset,然后:
cd home/.../data/VOCdevkit
mkdir mydataset
cd mydataset
mkdir Annotations
mkdir ImageSets
mkdir JPEGImages
cd ImageSets
mkdir Layout
mkdir Main
mkdir Segmentation① 将标注文件全部放入Annotations文件夹(博主用的label_image标注的xml文件)
② 将与标注文件一一对应的jpg图像文件全部放入JPEG文件夹
③ ImageSets/Main/文件夹中放入train.txt, val.txt, trainval.txt, test.txt四个文件,txt文件内容为图片的文件名(不带后缀),
train.txt——用于训练的图片文件的文件名列表;
val.txt——训练过程用来验证的图片文件的文件名列表,一般保持和train中图片数量相近;
trianval.txt——用来训练和验证的图片文件的文件名列表,数量为train和val中图片数量之和;
test.txt——用来测试已训练的模型的文件名列表,数量一般和trainval中图片数量相近。
关于如何生成以上四个文件见文章最后第三部分
④ 在/examples下创建mydataset文件夹,存放后续生成的lmdb文件
cd example/
mkdir mydataset1.4 生成lmdb文件
上述文件夹创建好后, 开始生成lmdb文件, 在创建之前需要修改相关路径:
打开create_list.sh,把“for name in VOC2007 VOC2012",修改为”for name in mydataset“
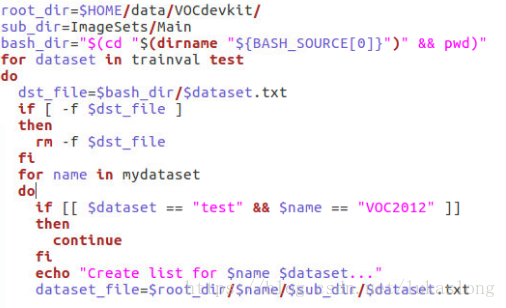
打开create_data.sh,把dataset_name的值修改为mydataset

1.5 开始训练
打开example/ssd/ssd_pascal.py进行修改:
# 82行:train_data路径; Created by data/VOC0712/create_data.sh
train_data = "examples/mydataset/mydataset_test_lmdb"
# 84行:test_data路径;Created by data/VOC0712/create_data.sh
test_data = "examples/mydataset/mydataset_trainval_lmdb"
237-246行:model_name、save_dir、snapshot_dir、job_dir、output_result_dir路径;
259-263行:name_size_file、label_map_file路径;
266行:num_classes修改为1 + 类别数,本文中为3+1=4;
344行:gpus = "0,1,2,3"根据自己需求修改,博主只有一块GPU即gpus = "0"
360行:num_test_image:测试集图片数目修改后的文件见:
修改完成后,运行
python ./examples/ssd/ssd_pascal.py第三部分 基于MATLAB生成训练和测试用的train.txt, val.txt, trainval.txt, test.txt
1. 构建函数
将样本集随机分成训练和测试两部分,其中训练又分为train和val两部分
function [test_index, trainval_index, train_index,val_index] = getdataset(imagepath)
% 如 imagepath = '/home/zyl/data/VOCdevkit/mydataset/JPEGImages';
images_name = dir(imagepath);
len = length(images_name);
for i = 3:len
name(i-2,1) = {images_name(i).name(1:end-4)};
end
image_orign = name;
len2 = len-2;
index = randperm(len2); %生成随机的下标
test_num = floor(len2/2); %测试样本数目
trainval_num = len2 - test_num;
train_num = floor(trainval_num/2);%训练样本数目
val_num = trainval_num - train_num;%验证集数目
% 将随机选取后的数列的一半给test,一半给trainval
test_index = image_orign(index(1:test_num),:);
trainval_index = image_orign(index(test_num+1:end),:);
% 将trainval的一半给train,一半给val
train_index = image_orign(index(test_num+1:test_num+train_num),:);
val_index = image_orign(index(test_num+train_num+1:end),:);2. 生成txt文件
%% 将数据集划分为四部分,分别是训练集、测试集、验证集、训练-验证集,并写入相应txt文件
[test_index, trainval_index, train_index,val_index] = getdataset('/home/zyl/data/VOCdevkit/mydataset/JPEGImages');%读取所有的数据文件
path = '/home/zyl/data/VOCdevkit/mydataset/ImageSets/Main/';%划分后的数据集保存路径
name1 = [path,'test.txt'];
name2 = [path,'trainval.txt'];
name3 = [path,'train.txt'];
name4 = [path,'val.txt'];
fid1 = fopen(name1,'w');
for i = 1:length(test_index)
fprintf(fid1,'%s\n',test_index{i});
end
fid2 = fopen(name2,'w');
for i = 1:length(trainval_index)
fprintf(fid2,'%s\n',trainval_index{i});
end
fid3 = fopen(name3,'w');
for i = 1:length(train_index)
fprintf(fid3,'%s\n',train_index{i});
end
fid4 = fopen(name4,'w');
for i = 1:length(val_index)
fprintf(fid4,'%s\n',val_index{i});
end
fclose all;