使用VGG16-SSD模型训练自己的数据集做识别
首先是感谢B站UP住对SSD的讲解,虽然听一遍确实不太懂,但是多听多看总会越来越懂。贴出UP主的博客和源码供大家学习。顺便说我也是在这个源码上修改训练的
源码地址:https://github.com/bubbliiiing/ssd-keras
博客地址:https://blog.csdn.net/weixin_44791964/article/details/104107271
建立自己的数据集
用lableImg对图片做标注
1、本文使用VOC格式进行训练。
2、训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。

3、训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
4、在训练前利用voc2ssd.py文件生成对应的txt。
5、再运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
你有几个类就改成几个,引号中写入对应的标签名;
6、就会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。
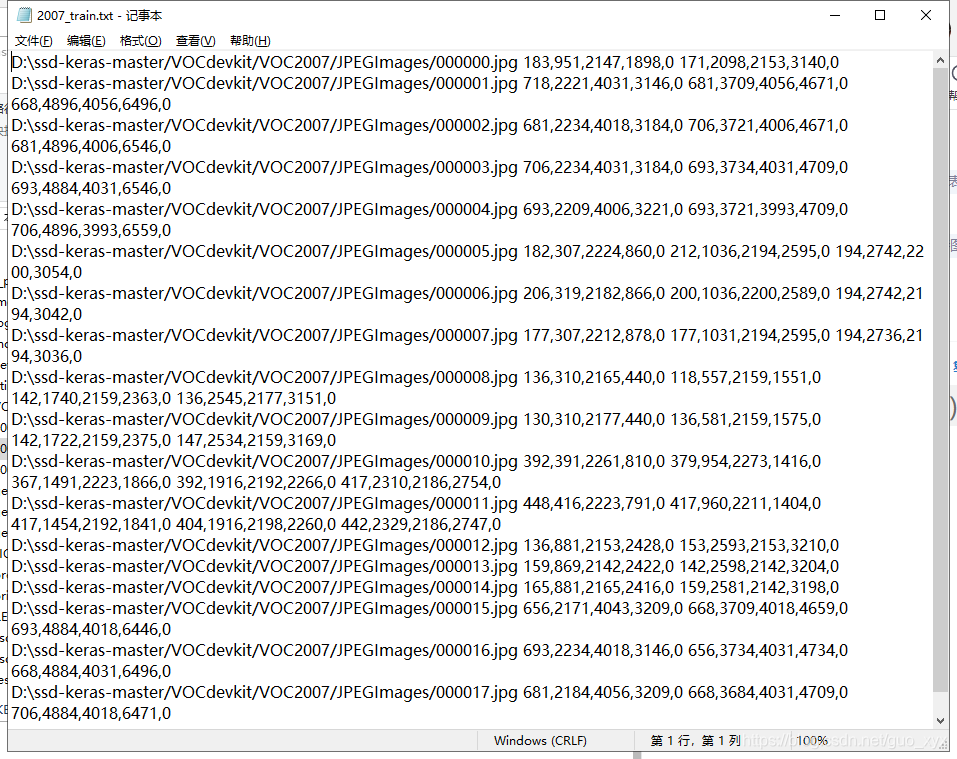
7、在训练前需要修改model_data里面的voc_classes.txt文件,需要将classes改成你自己的classes。
8、修改train.py里面的NUM_CLASSES与需要训练的种类的个数相同。运行train.py即可开始训练。
对网络进行调整和修改参数适应自己的需要
遇到的问题:
1、AttributeError: module 'scipy.misc' has no attribute 'imread'
AttributeError: module 'scipy.misc' has no attribute 'imresize'
可以有三种修改方式,可以选择单独使用或者组合使用,首先是把scipy.misc改成imageio;然后对于imresize的问题,可以选择在anaconda中把scipy的版本降低到1.2.0;再参照这篇博客:
https://blog.csdn.net/weekdawn/article/details/97777747,的改进,对自己的代码进行修改,基本上就可以解决这个问题了。
2、对于模型文件的问题,自己训练之后的模型文件在logs文件夹中
将你训练的最新的模型文件放入到model_data文件夹下,并在你的ssd.py文件中修改

3、如果你数据集的量很少,只是测试模型能否跑通,那个你还需要对train,py中的BATCH_SIZE进行修改,调成1之后,就可以正常运行了
这样你就可以运行predict去预测你啦!