监督学习:借助于外在的一些东西进行学习的方法,例如,带标签的训练数据。
无监督学习:将数据划分到相似的类别中。例如,将一些猫和狗的照片输入到系统中,并没有告诉系统哪些是猫的照片或者狗的照片,让系统根据照片之间的相似性将照片划分成两类。
训练数据是机器学习的基础,系统就是在训练数据中获取经验信息的。
我们将阐述以下问题:
1.回归和分类的区别
2.训练数据、验证数据、测试数据的必要性
3.准确度的衡量标准。
回归与分类
假设,我们有一个预测某区域中可口可乐的销量问题。这个数量在1百万-1.2百万之间(每周)。回归是预测连续性变量的一种经典方法。
分类,预测的事件只有几种不同可能的输出,例如,预测某天是晴天或者雨天。
线性回归是一种经典的回归算法。
逻辑回归是一种经典的分类算法。
训练数据与测试数据
在回归问题上,我们需要解决泛化能力及过拟合问题。
当模型过于复杂,完美地拟合所有的数据点,达到最小误差,过拟合就出现了。
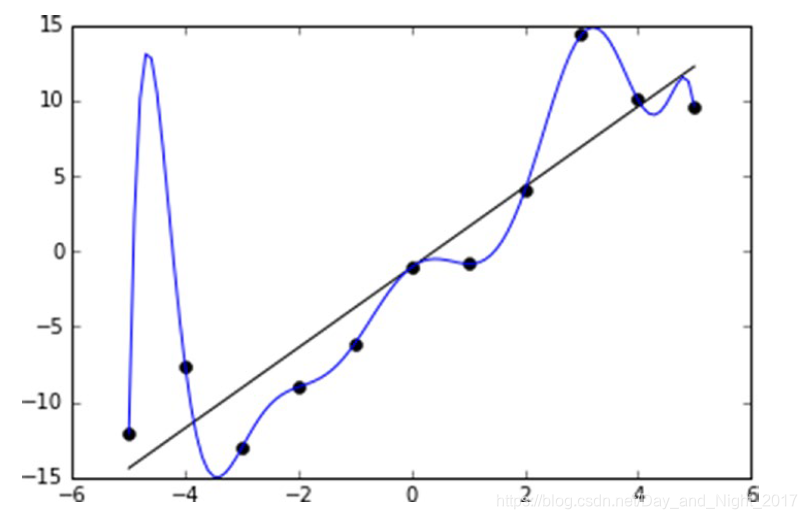
从图中可以看出,直线并没有完全拟合所有的数据点,蓝色曲线经过了所有的数据点,达到了训练数据集上的最小误差。但是,在新的数据集上,直线所在的模型可能会比蓝色曲线具有更好的泛化能力。实际上,回归或者分类问题是在模型泛化能力与模型复杂度之间的较量。
泛化能力越差,在新的数据集上的误差就会越大。

如图所示,随着模型复杂度升高,模型在新数据集上的表现是先降低,到达某个位置后逐渐升高(红色线)。
而在训练数据集上,误差在不断地降低。
这种新数据集用于测试模型的泛化能力,所以称为测试集。
验证集
如果只有一个固定的训练集,一个固定的测试集,可能存在一个很大的问题:模型在将来的新数据集上有可能表现不佳,因为这个固定的训练集和测试集实在是太单一了。
有的时候,自己的模型性能不错,遇到新的数据后变化很大,这个时候我们就需要一种叫做交叉验证的方法去解决问题。
如果仅仅有训练集和测试集的话,假设测试集是模型无法接触到的数据,我们就没法去处理超参数。
验证集就是这样一个数据集,让我们调整超参数的时候,我们可以看到模型的准确度。
经典做法是,将数据集的60%作为训练集,20%作为测试集,20%作为验证集。
准确度的衡量
准确度的衡量往往在测试数据集上进行,因为在训练数据集上衡量准确度是没有意义的,我们的模型肯定是在训练集上学习经验,在新的数据集上使用。如果仅仅在训练数据集上进行准确度的衡量,就无法达到泛化的目的。
绝对值误差
绝对值误差指的是预测值与真实值之间的绝对值差异。

如果只考虑总体上的误差之和的话,总误差是0.这是片面的看法。
根均方误差(RMSE)
另外一种消除抵消的方法是求平方。

根均方误差是(800 / 2)^(1 / 2) = 20
混淆矩阵
对于回归问题我们可以使用上述的绝对值误差或者根均方误差计算准确度,但是对于分类问题,我们需要其他的方法。

敏感度(真正率、召回率):true positive / total positive = TP / (TP+FN)
真负率:true negetive / total negetive = TN / (TN+FP)
准确度:TP / ( TP + FP)
召回率:TP / ( TP + FN)
Accuracy: (TP+TN)/ (TP + FN + FP + TN)
F1: 2TP / (2TP+FP+FN)
AUC值与ROC曲线
假如,你有这样的任务:人工检查一些金融交易是否存在诈骗
代价是,你需要花费人力去挨个检查这些交易信息。
收益是,通过人工检查交易信息可以避免欺诈风险。
我们可以建立这样一个模型:对每笔交易进行打分,这个分数表示这份交易存在欺诈的可能性。我们对于欺诈可能性非常小的交易不再进行人工核对。这样,经过这样一个模型,我们就减少了人工核对的工作量了。但是存在一定的代价,有些交易并没有核对,就存在着欺诈的风险,尽管他们存在欺诈的可能性较小。
1. 将交易信息输入到模型,对每一笔交易进行评分
2. 将交易信息按照可能性降序排列。
经过上述步骤,在列表的前部分很少有非诈骗交易,在列表的后部分很少有诈骗交易。
AUC值会因为出现类似的异常值(列表前部分的非诈骗交易、列表后部分的诈骗交易)而受惩罚。
假设有100万个交易需要核查,基于经验,大约1%的交易是欺诈性的。
ROC曲线的x轴是考虑到的交易数量,y轴是欺诈交易数量。

如果没有这个模型,那么会呈现以下情形:

我们将两种情形做对比:

AUC(曲线下的部分)>0.5,AUC越大,预测模型的效果越好。