A Salt Identification Case Study
Table of Contents:
- Introduction
- Prerequisites
- What is Semantic Segmentation?
- Applications
- Business Problem
- Understanding the data
- Understanding Convolution, Max Pooling and Transposed Convolution
- UNET Architecture and Training
- Inference
- Conclusion
- References
1. Introduction
计算机视觉是一个跨学科的科学领域,涉及如何使计算机从数字图像或视频中获得高层次的理解。 从工程的角度来看,它寻求自动化人类视觉系统可以完成的任务。(维基百科)
深度学习使计算机视觉领域在过去几年中迅速发展。 在这篇文章中,我想讨论计算机视觉中称为语义分割的一个特定任务。 尽管研究人员提出了许多方法来解决这个问题,但我将讨论一个特定的架构,即** UNET **,它使用完全卷积网络模型来完成任务。
我们将使用UNET为Kaggle主办的TGS盐识别挑战构建首个解决方案。
除此之外,我撰写博客的目的还在于提供一些关于卷积网络中常用操作和术语理解的直观见解。 其中一些包括卷积,最大池,接收场,上采样,转置卷积,跳过连接等。
2. Prerequisites
我将假设读者已经熟悉机器学习和卷积网络的基本概念。 此外,您必须具备使用Python和Keras库的ConvNets的一些工作知识。
3. What is Semantic Segmentation?
计算机可以通过各种级别的粒度来了解图像。 对于这些级别中的每个级别,计算机视觉域中都存在问题。 从粗粒度到更细粒度的理解,我们将在下面描述这些问题:
a. Image classification

计算机视觉中最基本的构建块是图像分类问题,在给定图像的情况下,我们希望计算机输出离散标签,这是图像中的主要对象。 在图像分类中,我们假设图像中只有一个(而不是多个)对象。
b. Classification with Localization

在本地化以及离散标签中,我们还期望计算本地化对象在图像中的确切位置。 这种定位通常使用边界框来实现,该边界框可以通过关于图像边界的一些数值参数来识别。 即使在这种情况下,假设每个图像只有一个对象。
c. Object Detection

对象检测将本地化扩展到下一个级别,现在图像不限于只有一个对象,但可以包含多个对象。 任务是对图像中的所有对象进行分类和本地化。 这里再次使用边界框的概念完成本地化。
d. Semantic Segmentation

语义图像分割的目标是用相应的类标记图像的每个像素。 因为我们正在预测图像中的每个像素,所以此任务通常被称为密集预测。
请注意,与以前的任务不同,语义分段中的预期输出不仅仅是标签和边界框参数。 输出本身是高分辨率图像(通常与输入图像大小相同),其中每个像素被分类为特定类。 因此,它是像素级图像分类。
e. Instance segmentation

实例分割比语义分割领先一步,其中随着像素级分类,我们期望计算机分别对类的每个实例进行分类。 例如,在上图中有3个人,技术上是“人”类的3个实例。 所有3个都被分类(以不同的颜色)。 但是语义分割不区分特定类的实例。
如果您仍然对目标检测,语义分割和实例分割的差异感到困惑,下面的图像将有助于澄清这一点:
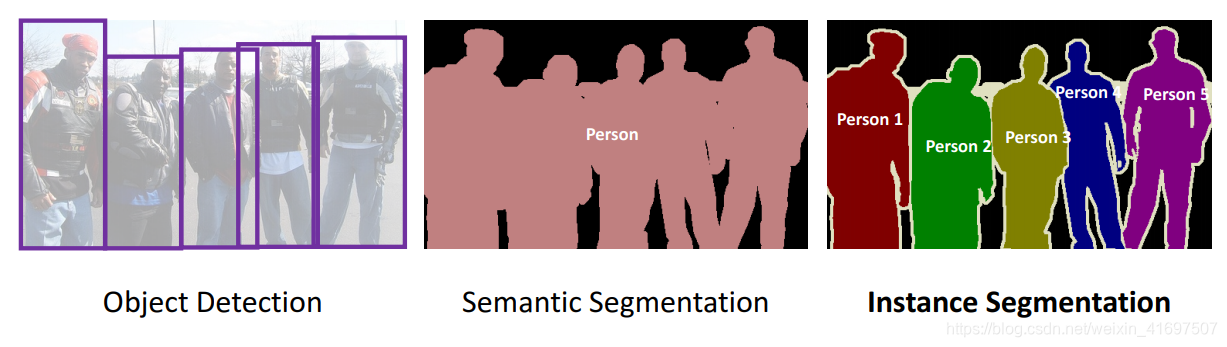
对象检测与语义分割与实例分割
在这篇文章中,我们将学习使用名为UNET的完全卷积网络(FCN)解决语义分段问题。
4. Applications
如果您想知道,语义分段是否有用,您的查询是合理的。 然而,事实证明,Vision中的许多复杂任务需要对图像进行细致的理解。 例如:
a. Autonomous vehicles
自动驾驶是一项复杂的机器人任务,需要在不断变化的环境中进行感知,规划和执行。 由于安全性至关重要,因此还需要以最高精度执行此任务。 语义分段提供有关道路上自由空间的信息,以及检测车道标记和交通标志。

b. Bio Medical Image Diagnosis
机器可以增强放射科医师进行的分析,大大减少了运行诊断测试所需的时间。

c. Geo Sensing
语义分割问题也可以被认为是分类问题,其中每个像素被分类为来自一系列对象类的一个。 因此,存在用于卫星图像的土地使用映射的用例。 土地覆盖信息对于各种应用非常重要,例如监测毁林和城市化的区域。
为了识别卫星图像上每个像素的土地覆盖类型(例如,城市,农业,水等区域),土地覆盖分类可以被视为多级语义分割任务。 道路和建筑物检测也是交通管理,城市规划和道路监测的重要研究课题。
几乎没有大规模公开可用的数据集(例如:SpaceNet),数据标记始终是分段任务的瓶颈。

d. Precision Agriculture
精确农业机器人可以减少需要在田间喷洒的除草剂的数量,并且作物和杂草的语义分割可以帮助它们实时触发除草行为。 这种先进的农业图像视觉技术可以减少对农业的人工监测。
我们还将考虑一个实际的现实世界案例研究,以了解语义分割的重要性。 问题陈述和数据集在以下部分中描述。
5. Business Problem
在任何机器学习任务中,总是建议花费大量时间来恰当地理解我们要解决的业务问题。这不仅有助于有效地应用技术工具,还可以激励开发人员利用他/她的技能解决现实问题。
TGS是领先的地理科学和数据公司之一,它使用地震图像和3D渲染来了解地球表面下面含有大量石油和天然气的区域。
有趣的是,含有石油和天然气的表面也含有巨大的盐沉积物。因此,在地震技术的帮助下,他们试图预测地球表面的哪些区域含有大量的盐。
不幸的是,专业的地震成像需要专家的人类视觉才能准确识别盐体。这导致高度主观和可变的渲染。此外,如果人类预测不正确,它可能会给石油和天然气公司的钻探人员造成巨大损失。
因此,TGS举办了一场Kaggle比赛,利用机器视觉以更高的效率和准确性来解决这一任务。
To read more about the challenge, click here.
To read more about seismic technology, click here.
6. Understanding the data
从此处下载数据文件。
为简单起见,我们将仅使用包含图像及其相应掩码的train.zip文件。
在图像目录中,有4000个地震图像被人类专家用来预测该区域是否存在盐沉积物。
在掩模目录中,有4000个灰度图像,它们是相应图像的实际地面实况值,表示地震图像是否包含盐沉积,如果是,则表示在哪里。 这些将用于建立监督学习模型。
让我们可视化给定的数据以更好地理解:

左边的图像是地震图像。 绘制黑色边界只是为了理解表示哪个部分包含盐而哪个部分不包含盐。 (当然这个边界不是原始图像的一部分)
右边的图像称为掩膜,它是地面实况标签。 这就是我们的模型必须为给定的地震图像预测的。 白色区域表示盐沉积,黑色区域表示无盐。
我们来看几张图片:



请注意,如果掩模是完全黑色的,这意味着给定的地震图像中没有盐沉积物。
显然,从以上几个图像中可以推断,人类专家不容易对地震图像进行精确的掩模预测。
7. 理解卷积,最大池和转置卷积
在我们深入研究UNET模型之前,了解卷积网络中通常使用的不同操作非常重要。 请记下所使用的术语。
i. Convolution operation
卷积操作有两个输入
i)尺寸为(nin x nin x个通道)的3D体积(输入图像)
ii)一组’k’滤波器(也称为内核或特征提取器),每个滤波器的大小(f x f x通道),其中f通常为3或5。
卷积运算的输出也是尺寸(nout x nout x k)的3D体积(也称为输出图像或特征图)。
nin和nout之间的关系如下:

卷积操作可视化如下:
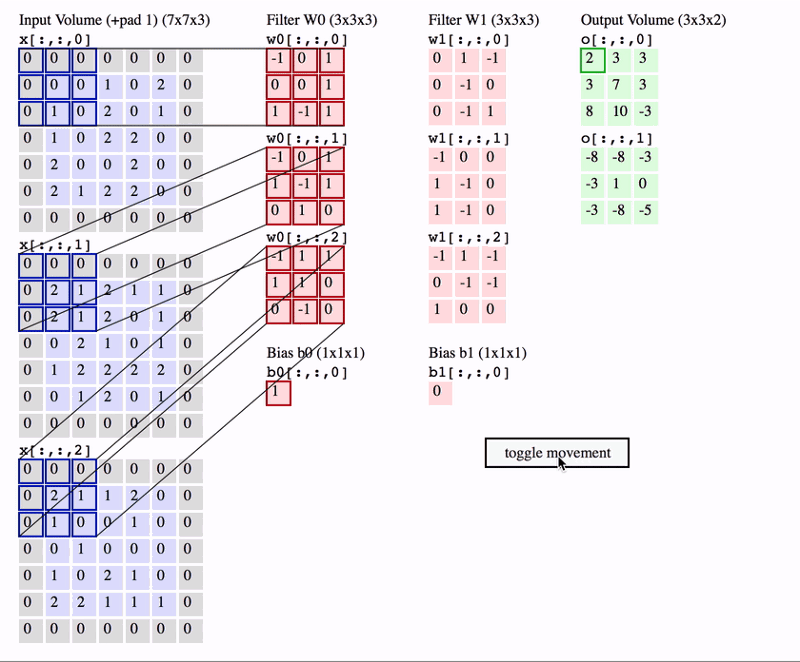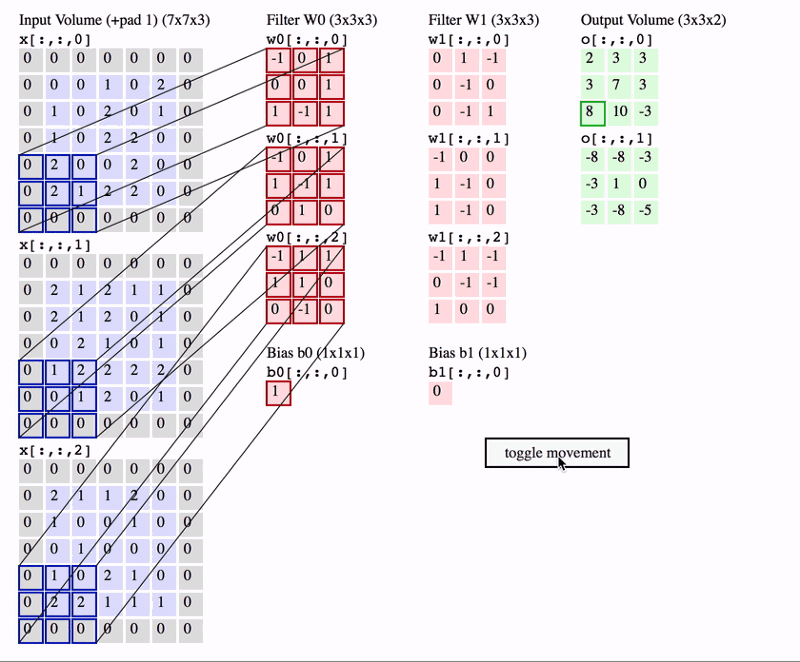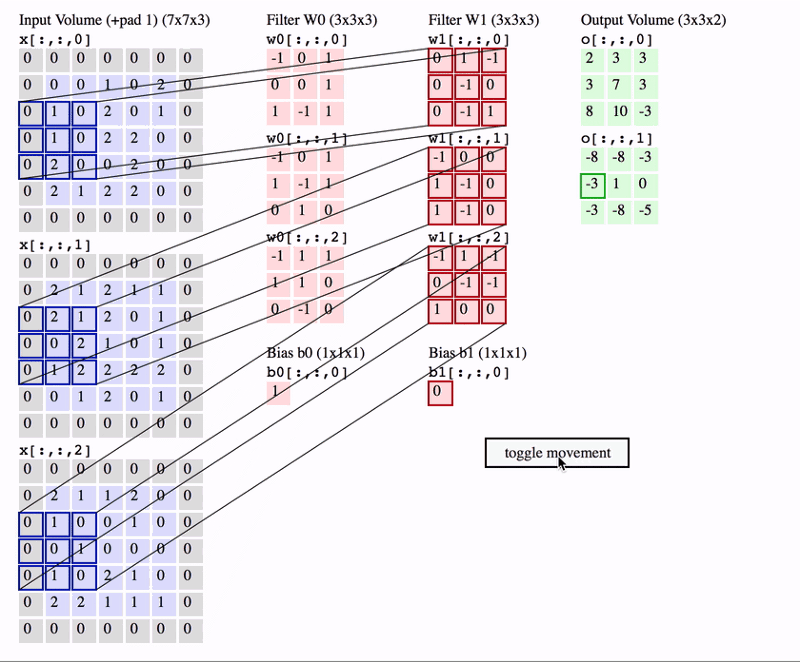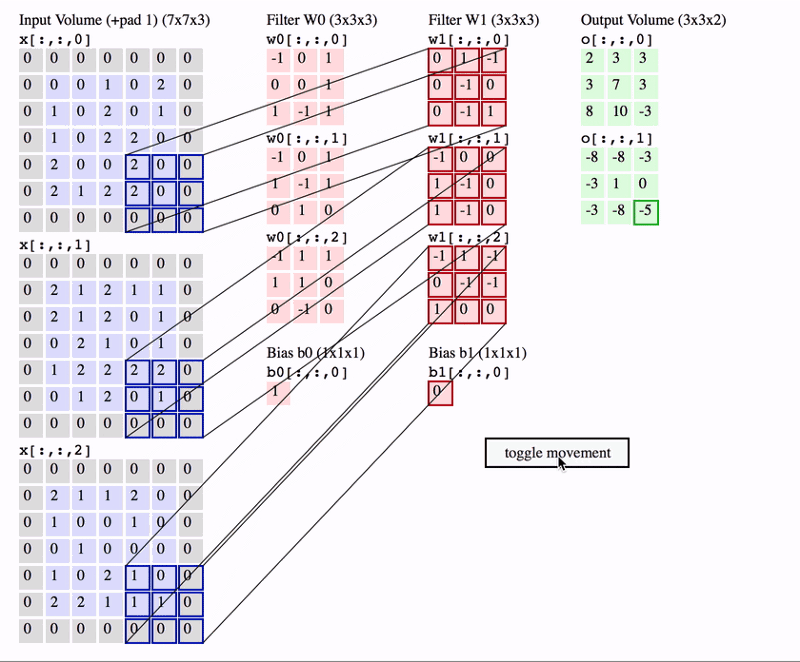
在上面的GIF中,我们有一个大小为7x7x3的输入行。 两个过滤器,每个尺寸为3x3x3。 填充= 0且Strides = 2.因此输出音量为3x3x2。 如果您对此算法不满意,那么在继续进行之前,您需要首先修改卷积网络的概念。
经常使用的一个重要术语称为Receptive提交。 这只是输入卷中特定特征提取器(过滤器)正在查看的区域。 在上面的GIF中,过滤器在任何给定实例中覆盖的输入体积中的3x3蓝色区域是感受野。 这有时也称为上下文。
换句话说,感受野(上下文)是过滤器在任何给定时间点覆盖的输入图像区域。
ii) Max pooling operation
In simple words, the function of pooling is to reduce the size of the feature map so that we have fewer parameters in the network.
For example:

基本上,从输入要素图的每个2x2块,我们选择最大像素值,从而获得池特征图。请注意,过滤器和步幅的大小是最大池操作中的两个重要超参数。
我们的想法是只保留每个区域的重要特征(最大值像素)并丢弃不重要的信息。重要的是,我的意思是最能描述图像背景的信息。
这里要注意的一个非常重要的一点是,卷积操作和特别是池化操作都会减小图像的大小。这称为下采样。在上面的示例中,池化前的图像大小为4x4,池化后的大小为2x2。事实上,下采样基本上意味着将高分辨率图像转换为低分辨率图像。
因此,在汇集之前,在汇集之后(几乎)相同信息存在于4×4图像中的信息现在存在于2×2图像中。
现在,当我们再次应用卷积运算时,下一层中的滤波器将能够看到更大的上下文,即当我们更深入到网络中时,图像的大小减小但是感知场增加。
例如,下面是LeNet 5架构:
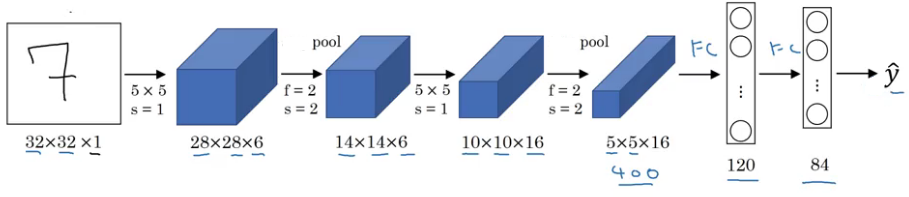
请注意,在典型的卷积网络中,图像的高度和宽度逐渐减小(下采样,因为汇集),这有助于更深层中的滤波器聚焦于更大的感知场(上下文)。 然而,通道数/深度(使用的滤波器数量)逐渐增加,这有助于从图像中提取更复杂的特征。
直观地说,我们可以得出以下汇总操作的结论。 通过下采样,模型更好地理解图像中存在“什么”,但它丢失了它所存在的“何处”的信息。
iii) Need for up sampling
如前所述,语义分段的输出不仅仅是类标签或某些边界框参数。 事实上,输出是一个完整的高分辨率图像,其中所有像素都被分类。
因此,如果我们使用具有池化层和密集层的常规卷积网络,我们将丢失“WHERE”信息并仅保留不是我们想要的“WHAT”信息。 在分割的情况下,我们需要“WHAT”和“WHERE”信息。
因此,需要对图像进行上采样,即将低分辨率图像转换为高分辨率图像以恢复“WHERE”信息。
在文献中,有许多技术可以对图像进行采样。 它们中的一些是双线性插值,三次插值,最近邻插值,解拼,转置卷积等。然而,在大多数现有技术网络中,转置卷积是用于对图像进行上采样的优选选择。
iv) Transposed Convolution
转置卷积(有时也称为反卷积或分步跨度卷积)是一种利用可学习参数执行图像采样的技术。
我不会描述转置卷积是如何工作的,因为Naoki Shibuya已经在他的博客Upample with Transposed Convolution中做了出色的工作。 我强烈建议您通过此博客(如果需要,多次)了解Transposed Convolution的过程。
然而,在高级别上,转置卷积恰好是正常卷积的相反过程,即输入音量是低分辨率图像,输出音量是高分辨率图像。
在博客中,很好地解释了正常卷积如何表示为输入图像和滤波器的矩阵乘法以产生输出图像。 通过对滤波器矩阵的转置,我们可以反转卷积过程,因此名称转置卷积。
v) Summary of this section
阅读本节后,您必须熟悉以下概念:
- 接受领域或背景
- 卷积和合并操作下采样图像,即将高分辨率图像转换为低分辨率图像
- Max Pooling操作通过增加感受野来帮助理解图像中的“WHAT”。但是它往往会丢失对象所在的“WHERE”信息。
- 在语义分割中,知道图像中存在“什么”并不重要,但知道它存在的“何处”同样重要。因此,我们需要一种方法来将图像从低分辨率提取到高分辨率,这将有助于我们恢复“WHERE”信息。
- Transposed Convolution是执行采样的最佳选择,它基本上通过反向传播来学习参数,以将低分辨率图像转换为高分辨率图像。
如果您对本节中介绍的任何术语或概念感到困惑,请随时阅读,直到您感到舒服为止。
8. UNET Architecture and Training
UNET由Olaf Ronneberger等人开发。 用于生物医学图像分割。 该体系结构包含两个路径。 第一条路径是收缩路径(也称为编码器),用于捕获图像中的上下文。 编码器只是传统的卷积和最大池化层。 第二条路径是对称扩展路径(也称为解码器),用于使用转置的卷积实现精确定位。 因此,它是一个端到端的完全卷积网络(FCN),即它只包含卷积层,并且不包含任何密集层,因为它可以接受任何大小的图像。
在原始论文中,UNET描述如下:
如果你不明白,那没关系。 我将尝试更直观地描述这种架构。 请注意,在原始纸张中,输入图像的大小为572x572x3,但是,我们将使用大小为128x128x3的输入图像。 因此,不同位置的尺寸将与原始纸张的尺寸不同,但核心部件保持不变。
以下是架构的详细说明:

Points to note:
- 2 @ Conv图层表示应用了两个连续的卷积图层
- c1,c2,… c9是Convolutional Layers的输出张量
- p1,p2,p3和p4是Max Pooling Layers的输出张量
- u6,u7,u8和u9是上采样(转置卷积)层的输出张量
- 左侧是收缩路径(编码器),我们应用常规卷积和最大池化层。
- 在编码器中,图像的大小逐渐减小,而深度逐渐增加。从128x128x3到8x8x256
- 这基本上意味着网络学习图像中的“WHAT”信息,但它丢失了“WHERE”信息
- 右侧是扩展路径(解码器),我们应用转置的卷积和常规卷积
- 在解码器中,图像的尺寸逐渐增大并且深度逐渐减小。从8x8x256开始到128x128x1
- 直观地,解码器通过逐渐应用上采样来恢复“WHERE”信息(精确定位)
- 为了获得更好的精确位置,在解码器的每一步,我们通过将转置的卷积层的输出与来自相同级别的编码器的特征映射相连接来使用跳过连接:
u6 = u6 + c4
u7 = u7 + c3
u8 = u8 + c2
u9 = u9 + c1
在每次连接之后,我们再次应用两个连续的常规卷积,以便模型可以学习组装更精确的输出 - 这就是给架构一个对称的U形,因此得名UNET
- 在较高的层面上,我们有以下关系:
输入(128x128x1)=>编码器=>(8x8x256)=>解码器=>输出(128x128x1)
下面是定义上述模型的Keras代码:
def conv2d_block(input_tensor, n_filters, kernel_size = 3, batchnorm = True):
"""Function to add 2 convolutional layers with the parameters passed to it"""
# first layer
x = Conv2D(filters = n_filters, kernel_size = (kernel_size, kernel_size),\
kernel_initializer = 'he_normal', padding = 'same')(input_tensor)
if batchnorm:
x = BatchNormalization()(x)
x = Activation('relu')(x)
# second layer
x = Conv2D(filters = n_filters, kernel_size = (kernel_size, kernel_size),\
kernel_initializer = 'he_normal', padding = 'same')(input_tensor)
if batchnorm:
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
def get_unet(input_img, n_filters = 16, dropout = 0.1, batchnorm = True):
# Contracting Path
c1 = conv2d_block(input_img, n_filters * 1, kernel_size = 3, batchnorm = batchnorm)
p1 = MaxPooling2D((2, 2))(c1)
p1 = Dropout(dropout)(p1)
c2 = conv2d_block(p1, n_filters * 2, kernel_size = 3, batchnorm = batchnorm)
p2 = MaxPooling2D((2, 2))(c2)
p2 = Dropout(dropout)(p2)
c3 = conv2d_block(p2, n_filters * 4, kernel_size = 3, batchnorm = batchnorm)
p3 = MaxPooling2D((2, 2))(c3)
p3 = Dropout(dropout)(p3)
c4 = conv2d_block(p3, n_filters * 8, kernel_size = 3, batchnorm = batchnorm)
p4 = MaxPooling2D((2, 2))(c4)
p4 = Dropout(dropout)(p4)
c5 = conv2d_block(p4, n_filters = n_filters * 16, kernel_size = 3, batchnorm = batchnorm)
# Expansive Path
u6 = Conv2DTranspose(n_filters * 8, (3, 3), strides = (2, 2), padding = 'same')(c5)
u6 = concatenate([u6, c4])
u6 = Dropout(dropout)(u6)
c6 = conv2d_block(u6, n_filters * 8, kernel_size = 3, batchnorm = batchnorm)
u7 = Conv2DTranspose(n_filters * 4, (3, 3), strides = (2, 2), padding = 'same')(c6)
u7 = concatenate([u7, c3])
u7 = Dropout(dropout)(u7)
c7 = conv2d_block(u7, n_filters * 4, kernel_size = 3, batchnorm = batchnorm)
u8 = Conv2DTranspose(n_filters * 2, (3, 3), strides = (2, 2), padding = 'same')(c7)
u8 = concatenate([u8, c2])
u8 = Dropout(dropout)(u8)
c8 = conv2d_block(u8, n_filters * 2, kernel_size = 3, batchnorm = batchnorm)
u9 = Conv2DTranspose(n_filters * 1, (3, 3), strides = (2, 2), padding = 'same')(c8)
u9 = concatenate([u9, c1])
u9 = Dropout(dropout)(u9)
c9 = conv2d_block(u9, n_filters * 1, kernel_size = 3, batchnorm = batchnorm)
outputs = Conv2D(1, (1, 1), activation='sigmoid')(c9)
model = Model(inputs=[input_img], outputs=[outputs])
return model
Training
使用Adam优化器编译模型,我们使用二元交叉熵损失函数,因为只有两个类(盐和无盐)。
我们使用Keras回调来实现:
- 如果5个连续时期的验证损失没有改善,则学习率会下降。
- 如果10个连续时期的验证损失没有改善,则提前停止。
- 仅在验证损失有所改善时保存权重。
我们使用批量大小为32。
请注意,调整这些超参数可能会有很大的余地,并进一步提高模型性能。
该模型在P4000 GPU上训练,训练时间不到20分钟。
9. Inference
请注意,对于每个像素,我们得到一个介于0到1之间的值。
0表示无盐,1表示盐。
我们将0.5作为阈值来决定是否将像素分类为0或1。
然而,确定阈值是棘手的并且可以被视为另一个超参数。
让我们看一下训练集和验证集的一些结果:
Results on training set




Results on Validation Set





训练集上的结果相对优于验证集上的结果,这意味着模型会过度拟合。 一个明显的原因可能是用于训练模型的少量图像。
10. Conclusion
感谢您对博客的兴趣。 如果您有任何意见,请留下评论,反馈和建议。
我的GitHub仓库这里上的完整代码。