图像分割
(1)普通分割:前景和后景分割。
(2)语义分割:每一类物体分割。
(3)实例分割:每一个实例分割。
却别于目标检测,图像分割师像素级别的分类。最早应用与医疗行业。
1. 应用:
(1) 医疗行业:器官图像分割…
(2) 汽车行业:自动驾驶…
2. 图像分割的结构:一般都是自编码结构
自编码结构:下采样,上采用,(又称为哑铃结构,瓶颈结构)
(1)下采样的方法:使用池化的下采样;使用较大步长的卷积下采样…
(2)上采样的方法:
①转置卷积:需要学习,参数较大,速度一般。
② 像素插值: 信息丢失较少,速度较快。
③ 像素融合:通道信息平铺,不丢失信息。
3. 图像分割的模型
(1)FCN 全卷积:第一个分割模型,效果不好;
(2)UNet;
(3)UNet++;
(4)U2Net;
(5)DeepLad:空洞卷积;
(6)MaskRCNN。
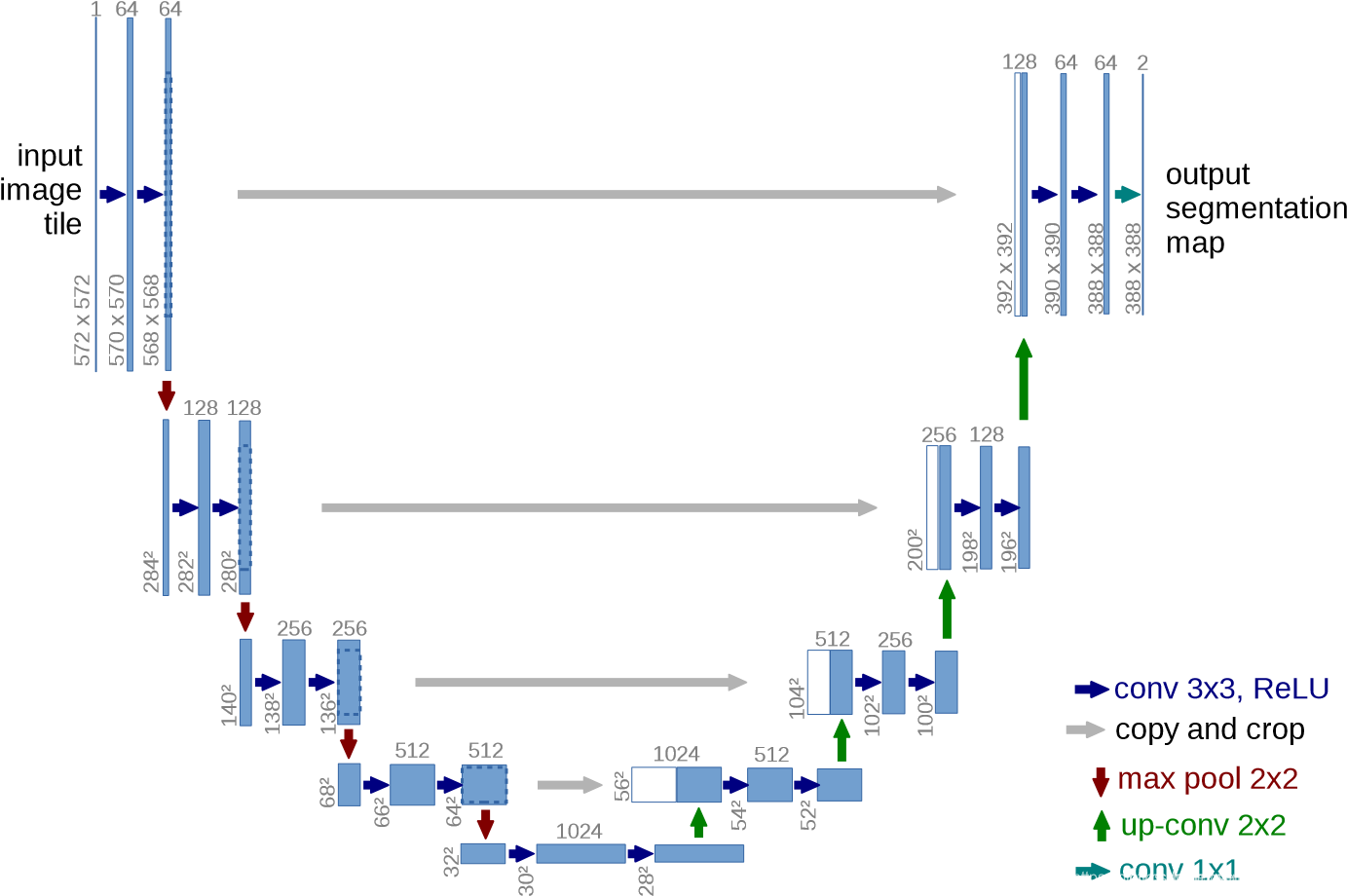
UNet
1. UNet
(1)步骤:
下采样的同时,保存当前图像/特征图。
上采样的同时,与下采样得到的特征进行拼接。(如果上下采样的尺寸不一样,采用裁剪拼接)
最后把最后一层和第一层拼接后的特征,进入输出层输出。
(2)网络结构:
主要子模块包括,卷积层、下采样层、上采样层。
class CNNLayer(torch.nn.Module):
def __init__(self, C_in, C_out):
super(CNNLayer,self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C_in,C_out, 3, 1, 1),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.3),
torch.nn.LeakyReLU(),
torch.nn.Conv2d(C_out, C_out, 3, 1, 1),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.4),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSampling(torch.nn.Module):
def __init__(self, C):
super(DownSampling, self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C, C, 3, 2, 1),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class UpSampling(torch.nn.Module):
def __init__(self, C):
super(UpSampling, self).__init__()
self.C = torch.nn.Conv2d(C, C//2, 1, 1)
def forward(self, x, r):
up = F.interpolate(x, scale_factor=2, mode='nearest')
x = self.C(up)
return torch.cat((x,r), 1)
class UNet(torch.nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.C1 = CNNLayer(3,64)
self.D1 = DownSampling(64)
self.C2 = CNNLayer(64, 128)
self.D2 = DownSampling(128)
self.C3 = CNNLayer(128, 256)
self.D3 = DownSampling(256)
self.C4 = CNNLayer(256, 512)
self.D4 = DownSampling(512)
self.C5 = CNNLayer(512, 1024)
self.U1 = UpSampling(1024)
self.C6 = CNNLayer(1024, 512)
self.U2 = UpSampling(512)
self.C7 = CNNLayer(512, 256)
self.U3 = UpSampling(256)
self.C8 = CNNLayer(256, 128)
self.U4 = UpSampling(128)
self.C9 = CNNLayer(128, 64)
self.pre = torch.nn.Conv2d(64, 3, 3, 1, 1)
self.Th = torch.nn.Sigmoid()
def forward(self, x):
R1 = self.C1(x)
R2 = self.C2(self.D1(R1))
R3 = self.C3(self.D2(R2))
R4 = self.C4(self.D3(R3))
Y1 = self.C5(self.D4(R4))
O1 = self.C6(self.U1(Y1, R4))
O2 = self.C7(self.U2(O1, R3))
O3 = self.C8(self.U3(O2, R2))
O4 = self.C9(self.U4(O3, R1))
return self.Th(self.pre(O4))
(3)dataset:将图片标签和数据缩放至256 * 256(统一大小)
from torchvision.utils import save_image
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
])
class makeData(Dataset):
def __init__(self, path):
self.path = path
self.name = os.listdir(os.path.join(path,'SegmentationClass'))
def __len__(self):
return len(self.name)
def __getitem__(self, index):
black_jpg = torchvision.transforms.ToPILImage()(torch.zeros(3,256,256))
black_png = torchvision.transforms.ToPILImage()(torch.zeros(3,256,256))
namepng = self.name[index]
namejpg = namepng[:-3] + 'jpg'
img_jpg_path = os.path.join(self.path,'JPEGImages')
img_png_path = os.path.join(self.path,'SegmentationClass')
img_jpg = Image.open(os.path.join(img_jpg_path, namejpg))
img_png = Image.open(os.path.join(img_png_path, namepng))
img_size = torch.Tensor(img_jpg.size)
l_max_index = img_size.argmax()
ratio = 256/img_size[l_max_index.item()]
img_re2size = img_size * ratio
img_jpg_use = img_jpg.resize(img_re2size)
img_png_use = img_png.resize(img_re2size)
w,h = img_re2size.tolist()
black_jpg.paste(img_jpg_use, (0, 0, int(w), int(h)))
black_png.paste(img_png_use, (0, 0, int(w), int(h)))
return transform(black_jpg), transform(black_png)
(4)训练
import os
from UNet import UNet
from gen_data import makeData
from torchvision.utils import save_image
path = r"D:/AIstudyCode/data/VOCtrainval_11-May-2012/VOCdevkit/VOC2012"
module = r"D:/AIstudyCode/data/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/train/module.pth"
img_save_path = r"D:/AIstudyCode/data/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/train/train_save_img"
epoch = 1
net = UNet().cuda()
optimizer = torch.optim.Adam(net.parameters())
loss_func = nn.BCELoss()
dataloader = DataLoader(makeData(path), batch_size=3, shuffle=True)
if os.path.exists(module):
net.load_state_dict(torch.load(module))
else:
print("NO Params!")
if not os.path.exists(img_save_path):
os.mkdir(img_save_path)
while True:
for i, (xs_jpg,ys_png) in enumerate(dataloader):
xs_jpg = xs_jpg.cuda()
ys_png = ys_png.cuda()
_xs_jpg = net(xs_jpg)
loss = loss_func(_xs_jpg, ys_png)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%50 == 0:
print('epoch:{},count:{},loss:{}'.format(epoch, i, loss))
x = xs_jpg[0]
_x = _xs_jpg[0]
y = ys_png[0]
img = torch.stack([x, _x, y], 0)
# print(img.shape)
torch.save(net.state_dict(), module)
print('module is saved !')
save_image(img.cpu(), os.path.join(img_save_path, '{}.png'.format(i)))
print("saved successfully!")
epoch += 1
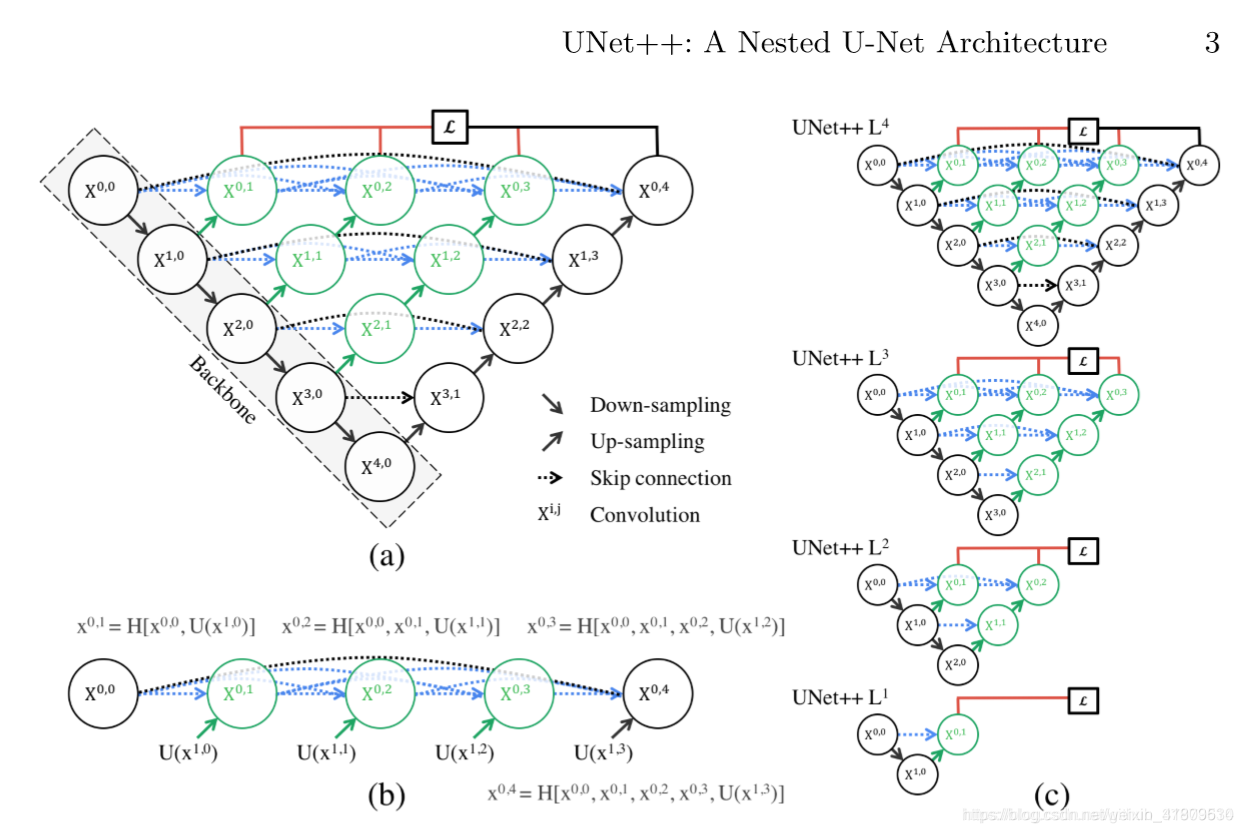
2. UNet++
(1)相对与UNet改变了每一层的连接结构。
(2)每一层相互监督学习。(有多个损失,每层一个损失)
(3)多个损失相互促进。
(4)可以被剪枝:假如某一层的结果已经达到目标要求,则可以舍弃后面的层。
3. U2Net(U平方Net)
每一个子单元都是一个UNet。