CSDN有一个排名的功能,这个排名的标准就是你的博客积分,积分可以通过发原创文章、提高阅读量等方式来增加,具体内容可以去CSDN查看。排名信息一天一更,但是没有往期记录,如果想要保留下自己博客的每一天的排名信息,只能通过手动的方式来实现。
今天我要做的就是通过Python爬虫程序,全自动获取个人博客的排名,评论数、点赞数量等信息。程序很简单,主要在于思路。
1.获取链接
想要获取你的排名信息的页面非常简单,只要点击博客主页左上角个人信息中的博客名称就可以了。

点击之后就可以看到自己的访问量、当前排名、点赞数、转发数等信息,此页面的链接就是我们要爬取的目标。

2.页面分析
Chrome中右键点击“检查”,可以查看到此页面的源代码,选中我们所要获取信息的区域,分析它的HTML代码结构:
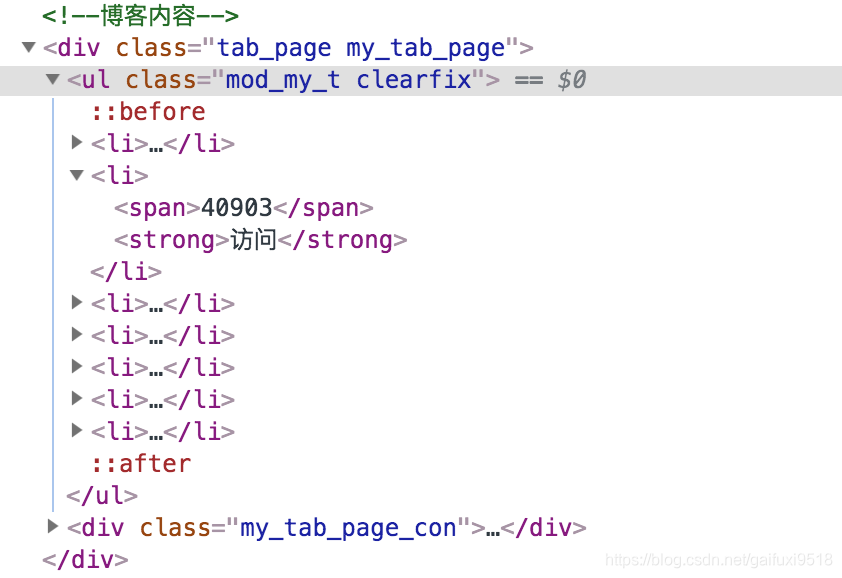
通过观察我们发现,我们想要的那些信息都在一个class属性为mod_my_t的ul标签中,至此我们就可以开始写代码啦!
3.导入相关库
判断文件是否存在所需的os库,获取时间需要time库、请求页面需要requests库、解析页面需要bs4库、将信息保存至Excel需要xlrd库和xlutils库、随机获取User-Agent需要fake_useragent库。
import os
import time
import xlwt
import requests
from xlutils.copy import copy
from bs4 import BeautifulSoup
from xlrd import open_workbook
from fake_useragent import UserAgent
4.页面抓取
这一步没什么好说了,通用的套路,该函数的返回值是HTML页面。
def get_html(csdn_url):
ua = UserAgent()
headers = {'User-Agent': ua.random}
html = requests.get(csdn_url,headers=headers).text
return html
5.页面解析
这个函数的作用是返回一个数组,该数组的元素就是我们想要的排名,点赞数等信息。
# 解析页面
def parse_html(html):
results = []
soup = BeautifulSoup(html,'html.parser')
content = soup.find(class_="mod_my_t").find_all(name='li')
results.append(time.strftime("%Y/%m/%d",time.localtime()))
for i in range(1,len(content)):
results.append(int(content[i].find(name='span').text))
return results
6.保存数据
这个函数无返回值。但会将我所需要的数据保存到Excel文件中,以方便对数据进行排名、筛选等操作。这里我加了一个判断,用于检查Excel文件是否存在,若存在直接保存数据,若不存在先生成Excel文件,再进行数据存储。
# 保存数据
def save_to_excel(results):
# 根据文件是否存在,进行不同的操作
if(os.path.exists('csdn.xls')):
open_excel = open_workbook("csdn.xls") # 读取Excel
rows = open_excel.sheets()[0].nrows # 获取现有行数
workbook = copy(open_excel) # 将xlrd对象转为xlwt对象
table = workbook.get_sheet(0) # 用xlwt对象获取要操作的sheet
print("Excel文件已存在,正在保存数据......")
else:
workbook = xlwt.Workbook(encoding='utf-8')
table = workbook.add_sheet('Sheet')
head = ['日期','访问','原创','转发','排名','评论','点赞']
# 生成表头
for i,head_item in enumerate(head):
table.write(0,i,head_item)
rows = 1
print('程序初次运行,已为您生成Excel文件,正在保存数据......')
# 存入数据
for i,result in enumerate(results):
table.write(rows,i,result)
workbook.save("csdn.xls")
print('恭喜,今日数据已成功保存!')
7.查看结果
至此,这个小小的功能就实现啦,但是程序还可以扩展更多功能,比如在保存数据之前判断今日数据是否已经存在,比如对Excel表格进行样式上的调整,比如在服务器设置定时自动运行脚本,以实现真正的全自动…

欢迎关注我公众号【程序员向东】,此公众号专注分享Python、爬虫学习资料和干货,关注后回复【PYTHON】,无套路免费送你一个学习大礼包,包括爬虫视频和电子书~

8.全部源代码
import os
import time
import xlwt
import requests
from xlutils.copy import copy
from bs4 import BeautifulSoup
from xlrd import open_workbook
from fake_useragent import UserAgent
csdn_url = "https://me.csdn.net/gaifuxi9518"
# 获取页面
def get_html(csdn_url):
ua = UserAgent()
headers = {'User-Agent': ua.random}
html = requests.get(csdn_url,headers=headers).text
return html
# 解析页面
def parse_html(html):
results = []
soup = BeautifulSoup(html,'html.parser')
content = soup.find(class_="mod_my_t").find_all(name='li')
results.append(time.strftime("%Y/%m/%d",time.localtime()))
for i in range(1,len(content)):
results.append(int(content[i].find(name='span').text))
return results
# 保存数据
def save_to_excel(results):
# 根据文件是否存在,进行不同的操作
if(os.path.exists('csdn.xls')):
open_excel = open_workbook("csdn.xls") # 读取Excel
rows = open_excel.sheets()[0].nrows # 获取现有行数
workbook = copy(open_excel) # 将xlrd对象转为xlwt对象
table = workbook.get_sheet(0) # 用xlwt对象获取要操作的sheet
print("Excel文件已存在,正在保存数据......")
else:
workbook = xlwt.Workbook(encoding='utf-8')
table = workbook.add_sheet('Sheet')
head = ['日期','访问','原创','转发','排名','评论','点赞']
# 生成表头
for i,head_item in enumerate(head):
table.write(0,i,head_item)
rows = 1
print('程序初次运行,已为您生成Excel文件,正在保存数据......')
# 存入数据
for i,result in enumerate(results):
table.write(rows,i,result)
workbook.save("csdn.xls")
print('恭喜,今日数据已成功保存!')
if __name__ == "__main__":
html = get_html(csdn_url)
results = parse_html(html)
save_to_excel(results)