hadoop的基本概念
伪分布式hadoop集群安装
hdfs、MapReduce演示
互联网正在从IT走向DT时代。
大数据应用分析
1、统计类的分析
2、推荐类的分析
3、机器学习(分类,聚类)
4、人工智能、预测(算法)
一、什么是hadoop
官网:http://hadoop.apache.org
hadoop是apache旗下的一套开源软件平台。
是一个可靠的、可扩展的、可分布式计算的开源软件。
apache hadoop平台是一个框架,允许使用简单的编程模型。
该平台被设计成可以从单个服务器扩展到数千台服务器,每个服务器都提供本地计算和存储。
也被设计成可检测和处理应用层的故障(即高可靠、高容错),高可用服务是基于计算机集群的,并且其中每一台计算机都有可能失效。
hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
作者:doug cutting
hadoop的核心组件:
hadoop common:hadoop工具
hadoop distributed file system(HDFS):分布式文件系统,解决海量数据的存储
hadoop YARN:运算资源调度系统,解决资源管理调度
hadoop MapReduce:分布式运算编程框架,解决海量数据的分析模型
Hadoop在2.0将资源管理从MapReduce中独立出来变成通用框架后,就从1.0的三层结构演变为了现在的四层架构:
1. 底层——存储层,文件系统HDFS
2. 中间层——资源及数据管理层,YARN以及Sentry等
3. 上层——MapReduce、Impala、Spark等计算引擎
4. 顶层——基于MapReduce、Spark等计算引擎的高级封装及工具,如Hive、Pig、Mahout等等
广义上来说,hadoop通常是指一个更广泛的概念——Hadoop生态圈
二、hadoop产生背景
1、hadoop最早起源于Nutch。
Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2、2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
分布式文件系统(GFS),可用于处理海量网页的存储;
分布式计算框架MapReduce,可用于处理海量网页的索引计算问题。
3、Nutch的开发人员完成了相应的开源实现HDFS和MapReduce,并从Nutch中剥离成为独立项目hadoop,到2008年1月,hadoop成为apache顶级项目,迎来了快速发展期。
三、hadoop在大数据、云计算中的位置和关系
1、云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助Iaas(基础设施即服务)、Paas(平台即服务)、Saas(软件即服务)等业务模式,把强大的计算能力提供给终端用户
2、现阶段,云计算的底层支撑技术为“虚拟化”和“大数据技术”
3、而hadoop则是云计算的Paas层的解决方案之一,并不等同于Paas,更不等同于云计算本身。
四、大数据处理业务应用
1、大型网站web服务器的日志分析:一个大型网站的web服务器集群 ,每5分钟收录的点击日志高达800GB左右,峰值点击每秒达到900万次,每个5分钟将数据装载到内存中,高速计算网站的热点URL,并将这些信息反馈给前端缓存服务器,以提高缓存命中率。
2、运营商流量分析:每天的流量数据在2TB~5TB左右,拷贝到HDFS上,通过交互式分析引擎框架,能运行几百个复杂的数据清洗和报表业务,总时间比类似硬件配置的小型机集群和DB2快2~3倍。
3、IPTV收视统计与点播推荐:一个实时收视率统计和点播推荐系统,可以实时收集用户的遥控器操作,提供实时的收视率榜单;并且根据内容推荐和协同过滤算法,实现了点播推荐服务。
4、城市交通卡口视频监控信息的实时分析:采用基于流式stream进行全省范围的交通卡口通过视频监控收录的信息进行实时分析、告警和统计(计算实时路况),对全省范围内未年检车辆或×××的分析延时在300毫秒左右,可以做出实时告警。
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就hadoop而言,通常都需要具备以下技能或知识:
1、hadoop分布式集群的平台搭建
2、hadoop分布式文件系统HDFS的原理理解及使用
3、hadoop分布式运算框架MapReduce的原理理解及编程
4、hive数据仓库工具的熟练应用
5、flume、sqoop、oozie等辅助工具的熟练使用
6、shell、python等脚本语言的开发能力
hadoop对海量数据处理的解决思路:
HDFS的架构:
主从结构:
主节点:namenode
从节点:有很多个datanode
namenode负责:
接受用户操作请求
存储文件的元数据以及每个文件的块列表和块所在的datanode等
维护文件系统的目录结构
管理文件与block之间的关系,block与datanode之间关系
datanode负责:
存储文件
在本地文件系统存储文件块数据,以及块数据的校验和
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
secondary namenode(2nn):用于监控HDFS状态的辅助后台程序,每隔一段时间获取和hdfs元数据的快照。
YARN架构:
1)ResourceManager(RM)主要作用如下:
(1)处理客户端请求
(2)监控NodeManager
(3)启动或监控ApplicationMaster
2)NodeManager(nm)主要作用如下:
(1)管理单个节点上的资源
(2)处理来自ResourceManager的命令
(3)处理来自ApplicationMaster的命令
3)ApplicationMaster(AM)作用:
(1)辅助数据的切分
(2)为应用程序申请资源并分配给内部的任务
(3)任务的监控与容错
4)Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
问题:怎么解决海量数据的计算
Mapreduce架构:
两个程序:
Map:局部并行处理输入数据
reduce:汇总局部处理的结果,再统计全局
hadoop1.x和hadoop2.x版本的区别:
安装部署,运维、开发、测试
HDFS三大核心:HDFS、MapReduce、YARN
四个模块:
hadoop common:为其他hadoop模块提供基础设施
hadoop dfs:一个高可靠、高吞吐量的分布式文件系统
hadoop mapreduce:一个分布式的离线并行计算框架
hadoop yarn:一个新的mapreduce框架,任务调度和资源管理
hadoop安装:
Hadoop三种安装模式
1.Hadoop单机模式
单机模式是Hadoop默认的安装模式,这种安装模式主要就是并不配置更多的配置文件,只是保守的去设置默认的几个配置文件中的初始化参数,它并不与其他节点进行交互,并且也不使用HDFS文件系统,它主要就是为了调试MapReduce程序而生。
2.Hadoop伪分布式安装模式
Hadoop伪分布式安装,需要配置5个常规的配置文件(XML),并且这里涉及到了NameNode和DataNode节点交互问题,而且NameNode和DataNode在同一个节点上,还需要配置互信。其实从严格意义上来讲,伪分布式集群,就已经可以称之为真正意义上的集群了,而且这里也包含了hdfs和MapReduce所有组件,只不过就是所有组件在同一个节点上而已。
3.Hadoop完全分布式安装模式
Hadoop完全分布式集群主要分为:常规Hadoop完全分布式集群和Hadoop HA集群(这里主要针对的是NameNode个数和NameNode的高可用保障机制而言)。由此可知较伪分布式集群而言,完全分布式集群,所有处理节点并不在同一个节点上,而是在多个节点上。
搭建一个伪分布式集群
一、环境搭建
1、系统环境
平台:VMware Workstation 14
系统:centos 7.4
IP地址如下图:
2、修改主机名:
hostnamectl set-hostname hadoop
useradd hadoop
passwd hadoop
visodu
hadoop ALL=(ALL) ALL
注:改完主机名后,需要exit退出,重新启动。
3、修改/etc/hosts域名解析配置文件
vi /etc/hosts
192.168.80.100 hadoop
4、关闭防火墙和selinux
systemctl disable firewalld
systemctl stop firewalld
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
5、安装时间同步
yum -y install ntpdate
ntpdate time1.aliyun.com
6、安装Java环境
1)解压Java压缩包
tar -xf jdk-8u11-linux-x64.tar.gz -C /opt
cp -rf jdk1.8.0_11/ /usr/local/java
2)配置Java环境变量
vi /etc/profile
末尾新增:
export JAVA_HOME=/usr/local/java
export JRE_HOME=/usr/local/java/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
3)生效环境变量
source /etc/profile
4)验证
java -version
出现以下提示,代表java环境部署成功:
java version "1.8.0_11"
Java(TM) SE Runtime Environment (build 1.8.0_11-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.11-b03, mixed mode)
二、hadoop正式部署安装
官方文档:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation
下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-3.1.0/hadoop-3.1.0.tar.gz
1、解压hadoop软件包
tar xf hadoop-3.1.0.tar.gz
2、重命名
mv hadoop-3.1.0/ /home/hadoop/hadoop
3、配置环境变量
vi /etc/profile
export HADOOP_HOME=/home/hadoop/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_COMMON_LIB_NATIVE_DIR=/home/hadoop/hadoop/lib/native
export HADOOP_OPTS="-Djava.library.path=/home/hadoop/hadoop/lib"
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
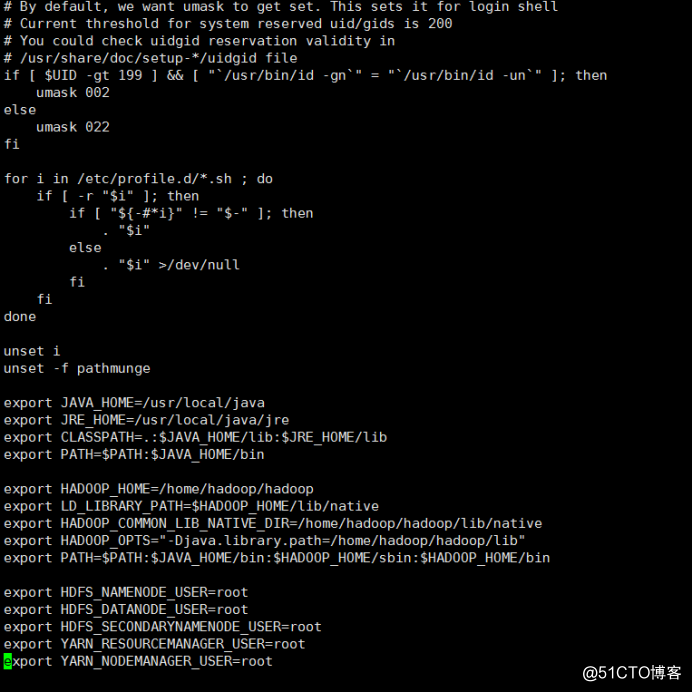
#hadoop-3.1.0必须添加如下5个变量否则启动报错,hadoop-2.x貌似不需要
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4、生效环境变量
source /etc/profile
5、测试是否配置成功
hadoop version
出现以下信息,代表配置成功:
Hadoop 3.1.0
Source code repository https://github.com/apache/hadoop -r 16b70619a24cdcf5d3b0fcf4b58ca77238ccbe6d
Compiled by centos on 2018-03-30T00:00Z
Compiled with protoc 2.5.0
From source with checksum 14182d20c972b3e2105580a1ad6990
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.0.jar

7、hadoop目录认识
修改配置文件之前,先看一下hadoop下的目录:
bin:hadoop最基本的管理脚本和使用脚本所在目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop
etc:配置文件存放的目录,包括core-site.xml,hdfs-site.xml,mapred-site.xml等从hadoop1.x继承而来的配置文件和yarn-site.xml等hadoop2.x新增的配置文件
include:对外提供的编程库头文件(具体动态库和静态库在lib目录中,这些头文件军事用c++定义的,通常用于c++程序访问hdfs或者编写mapreduce程序)
Lib:该目录包含了hadoop对外提供的才变成动态库和静态库,与include目录中的头文件结合使用
libexec:各个服务对应的shell配置文件所在目录,可用于配置日志输出目录、启动参数等信息
sbin:hadoop管理脚本所在目录,主要包含hdfs和yarn中各类服务的启动、关闭脚本
share:hadoop各个模块编译后的jar包所在目录。
cd /home/hadoop/hadoop/etc/hadoop #此目录是存放配置文件的
vi hadoop-env.sh #hadoop的变量设置脚本
#hadoop-3.1.0是第54行,hadoop-2.7.7是第25行
export JAVA_HOME=/usr/local/java
测试:
mkdir /home/input
hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar wordcount /home/input /home/output
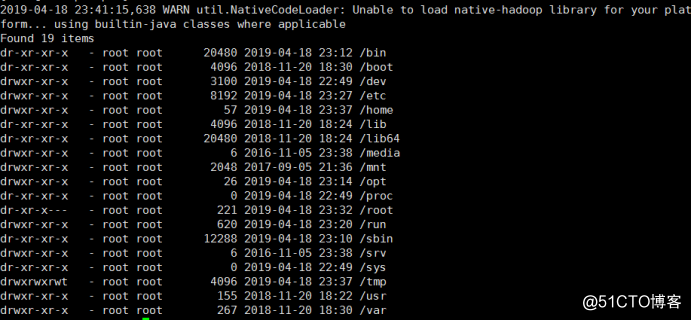
hdfs dfs -ls /
cd /home/hadoop/hadoop/etc/hadoop/
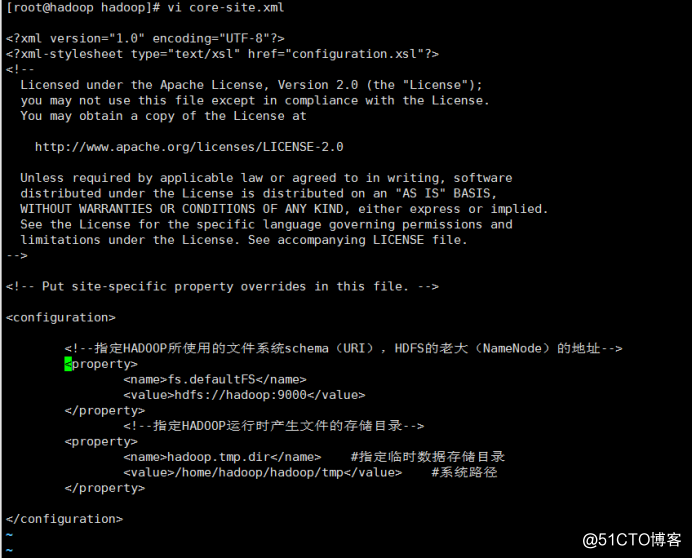
vi core-site.xml #hadoopg公共文件,全局配置文件
添加以下几行:
<configuration>
<!--指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!--指定HADOOP运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name> #指定临时数据存储目录
<value>/home/hadoop/hadoop/tmp</value> #系统路径
</property>
</configuration>
注意:在hadoop安装目录的文档中有所有配置文件的默认参数表,用户可以查看后,根据实际情况进行修改。
uri是使用自己的协议以及自己的地址端口
/usr/local/hadoop/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.html文档中可以看到:
hadoop.tmp.dir的默认值是/tmp/hadoop-${user.name}。/tmp/是Linux系统的临时目录,如果我们不重新指定的话,默认Hadoop工作目录在Linux的临时目录,一旦Linux系统重启,所有文件将会清空,包括元数据等信息都丢失了,需要重新进行格式化,非常麻烦。
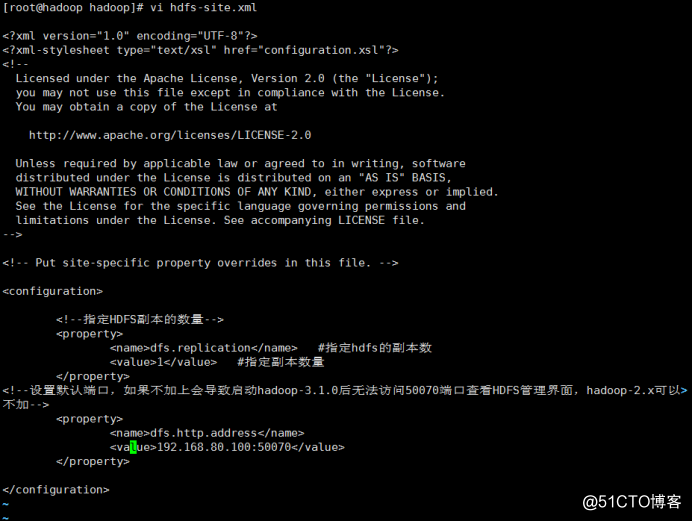
vi hdfs-site.xml #hdfs站点配置文件
添加以下几行:
<configuration>
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name> #指定hdfs的副本数
<value>1</value> #指定副本数量
</property>
<!--设置默认端口,如果不加上会导致启动hadoop-3.1.0后无法访问50070端口查看HDFS管理界面,hadoop-2.x可以不加-->
<property>
<name>dfs.http.address</name>
<value>192.168.80.100:50070</value>
</property>
</configuration>
注:
hdfs-default.xml文档中可以看到:
dfs.replication的默认值是3,由于HDFS的副本数不能大于DataNode数,而我们此时安装的hadoop中只有一个DataNode,所以将dfs.replication值改为1。
dfs.namenode.http-address在hadoop-3.1.0版本上的默认值是?0.0.0.0:9870 ,在hadoop-2.7.7版本上的默认值是0.0.0.0:50070,所以不同版本可以通过不同端口访问NameNode。
cp mapred-site.xml.templete mapred-site.xml #重命名,hadoop-3.1.0系统中就是mapred-site.xml不需要改名,hadoop-2.x需要改名
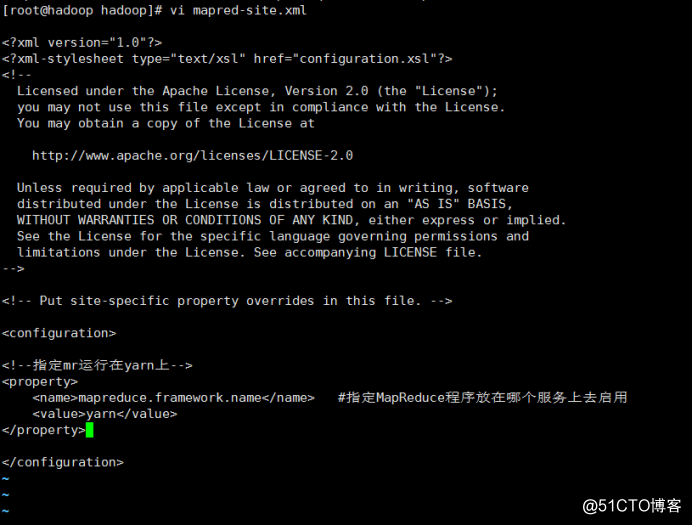
vi mapred-site.xml #添加如下几行,指定hadoop运行在哪种计算框架上,这里指定yarn框架。
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name> #指定MapReduce程序放在哪个服务上去启用
<value>yarn</value>
</property>
vi yarn-env.xml #2.x版本需要更改jdk路径
export JAVA_HOME =
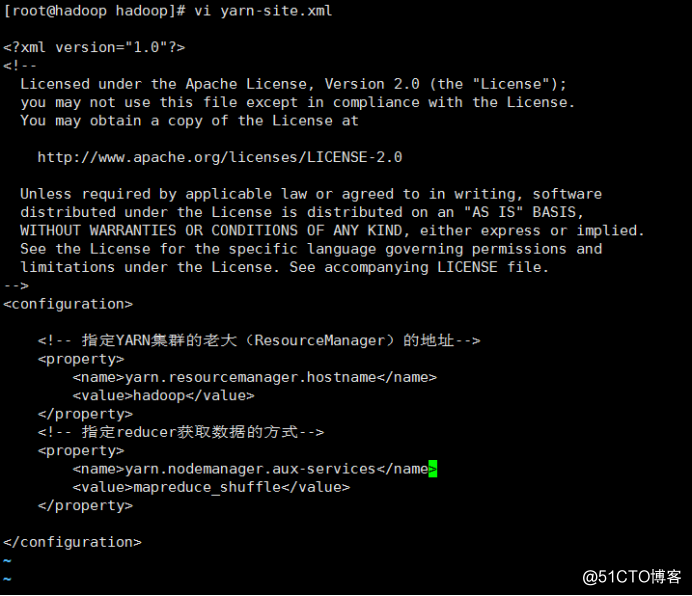
vi yarn-site.xml #添加如下几行
<configuration>
<!-- 指定YARN集群的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name> #
<value>mapreduce_shuffle</value>
</property>
</configuration>
8、免密码交互
ssh-keygen -t rsa #生成ssh密钥对
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): #直接回车
Enter passphrase (empty for no passphrase): #直接回车
Enter same passphrase again: #直接回车
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:9NevFFklAS5HaUGJtVrfAlbYk82bStTwPvHIWY7as38 root@hadoop
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| |
| . |
| . o S = |
| ..O * = |
| =X.%.E . . |
| *+=%oBo+.o |
| o=B+o++o.oo. |
+----[SHA256]-----+
cd /root/.ssh/
ls
id_rsa id_rsa.pub known_hosts
注:
#id_rsa为私钥,id_rsa.pub为公钥
因为搭建的是hadoop伪分布式,所以namenode与datanode都在一个节点上。
cp id_rsa.pub authorized_keys #使主机之间可以免密码登录
ssh hadoop date #查看(不需要输入密码,直接输出结果,说明免密成功)
9、启动hadoop集群
1)首先格式化NameNode
注意:如果格式化NameNode之后运行过hadoop,然后又想再格式化一次NameNode,那么需要先删除第一次运行Hadoop后产生的VERSION文件,否则会出错,详情见第四部分问题4。
cd
[root@hadoop ~]# hdfs namenode -format #中间没有报错并且最后显示如下信息表示格式化成功
...
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/192.168.80.100
************************************************************/
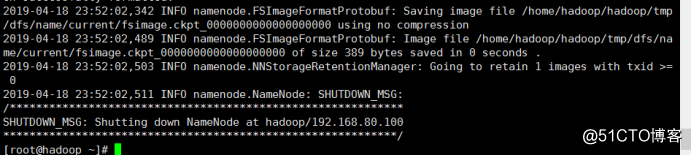
格式化完成后,系统会在dfs.data.dir目录下生成元数据信息。
name/current
data/current
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
或者:
start-dfs.sh
start-yarn.sh
2)输入 start-all.sh 启动
start-all.sh
Starting namenodes on [hadoop]
上一次登录:四 4月 18 23:06:27 CST 2019从 192.168.80.1pts/1 上
Starting datanodes
上一次登录:四 4月 18 23:53:44 CST 2019pts/1 上
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting secondary namenodes [hadoop]
上一次登录:四 4月 18 23:53:46 CST 2019pts/1 上
2019-04-18 23:54:08,969 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
上一次登录:四 4月 18 23:54:03 CST 2019pts/1 上
Starting nodemanagers
上一次登录:四 4月 18 23:54:10 CST 2019pts/1 上
3)执行 jps 验证集群是否启动成功
jps #显示以下几个进程说明启动成功
96662 Jps
95273 DataNode #可有可无
95465 SecondaryNameNode #重要
95144 NameNode #重要
95900 NodeManager #可有可无
95775 ResourceManager #非常重要
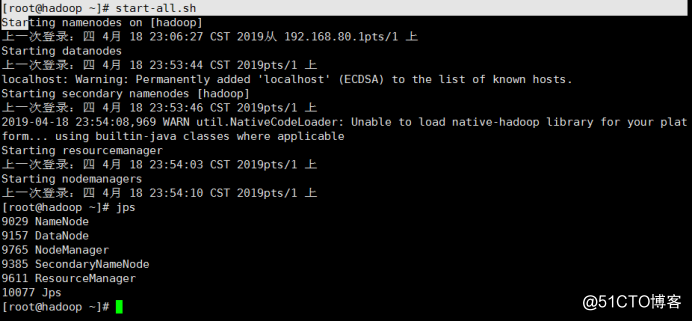
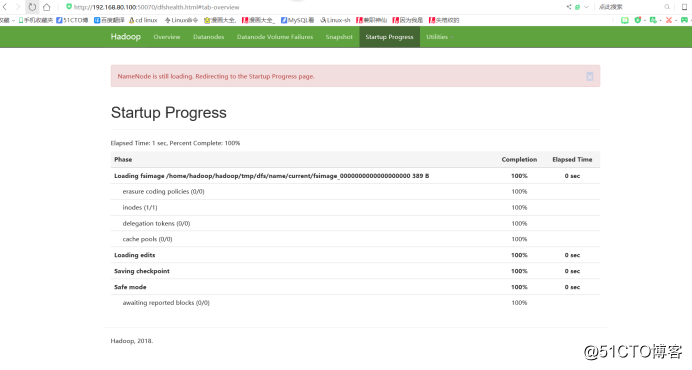
4)登录HDFS管理界面(NameNode):http://ip:50070
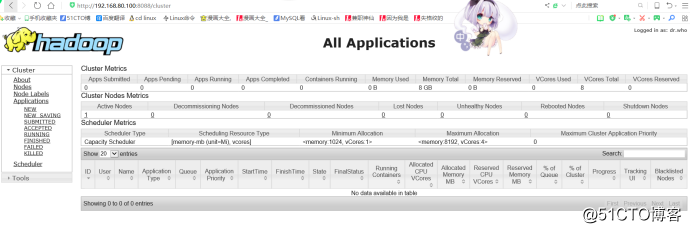
5)登录MR管理界面: http://ip:8088
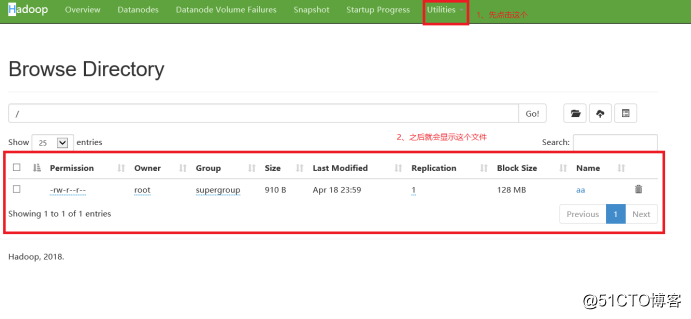
使用:
上传文件到hdfs中:
hadoop fs -put aa hdfs://192.168.80.100:9000/
注:aa是要上传的文件名

简写:
hadoop fs -put aa /
从hdfs中下载文件:
hadoop fs -get hdfs://192.168.80.100:9000/aa

在hdfs中创建目录:
hadoop fs -mkdir hdfs://192.168.80.100:9000/word
也可以简写:
hadoop fs -mkdir /word

调用MapReduce程序:
hadoop jar hadoop-mapreduce-examples~ pi 5 5
注:
pi:主类,计算圆周率
5:参数,map的任务数量
5:每个map的取样数
hadoop jar hadoop-mapreduce-example~ word /word/input /word/output
hadoop fs -ls /word/output
hadoop fs -cat /word/output/part~
HDFS的实现思想:
1、hdfs是通过分布式集群来存储文件
2、文件存储到hdfs集群中去的时候是被切分成block的
3、文件的block存放在若干台datanode节点上
4、hdfs文件系统中的文件与真实的block之间有映射关系,由namenode管理
5、每一个block在集群中会存储多个副本,好处是可以提高数据的可靠性,还可以提高访问的吞吐量
我们可以看到不管是启动还是关闭hadoop集群,系统都会报如下错误:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方式:先看看我们安装的hadoop是否是64位的
[root@hadoop hadoop]# file /usr/local/hadoop/lib/native/libhadoop.so.1.0.0 #出现以下信息表示我们的hadoop是64位的
/usr/local/hadoop/lib/native/libhadoop.so.1.0.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=8d84d1f56b8c218d2a33512179fabffbf237816a, not stripped
永久解决方式:
vi /usr/local/hadoop/etc/hadoop/log4j.properties #在文件末尾添加如下一句,保存退出
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=Error
配置说明
JDK :Hadoop和Spark 依赖的配置,官方建议JDK版本在1.7以上!!!
Scala:Spark依赖的配置,建议版本不低于spark的版本。
Hadoop: 是一个分布式系统基础架构。
Spark: 分布式存储的大数据进行处理的工具。
zookeeper:分布式应用程序协调服务,HBase集群需要。
HBase: 一个结构化数据的分布式存储系统。
Hive: 基于Hadoop的一个数据仓库工具,目前的默认元数据库是mysql。
配置历史服务器
vi mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
<property>
启动历史服务器:
sbin/mr-jobhistory-daemon.sh start historyserver
查看历史服务器是否启动
jps
查看jobhistory:
192.168.80.100:19888
配置日志聚集
日志聚集:应用运行完成以后,将程序运行日志信息上传到HDFS系统上
好处:可以方便的查看到程序运行详情,方便开发调试
注:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryManager
步骤:
关闭所有
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/yarn-daemon.sh stop nodemanager
sbin/yarn-daemon.sh stop resourcemanager
jps
vi yarn-site.xml
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<property>
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
测试:
hadoop jar hadoop-mapreduce-examples~ pi 5 5