更多R语言信息欢迎关注我的新浪微博:Jenny爱学习
微信公众号:R语言数据分析与实践
分析数据时,经常遇到分类变量。例如,假设你有一系列关于人群特征的数据,其中一个指标是瞳孔颜色。这时候,可以用字符型数组来表示瞳孔颜色:
> eye.colors <- c("brown","blue","blue","green","brown","brown","brown")
这是一种具有易读性的信息表示方法,然而,当处理大量的观测值与名称时,这种字符读取的方法就变得十分低效。R提供了一个表示信息分类的方法,即通过factor因子型变量表示分类信息。
1 分组因子
factor是一种特殊类型的向量,被用来给数据分组,例如male/female,它只可以取某些特定的值,这些值可能包含一些分级/等级排序。因子型变量(factor)通常是一个有序项目的几何,因子型变量可以取得的所有值被称为因子水平。
order有序factor:将分级/有等级的数据用有序factor表示,这些数据并非数值型。例如在大学中,有助教、研究员、副研究员、副教授、教授。这些都属于分类,并且是有序的。

假设存在一个整型向量为factor,并且向量中每个数值都带有一个label标签。例如在评级中,将向量数值设置为1,2,3,其中1代表最高等级,2代表中等,3代表最差。由此可以得到一组变量:高、中、低。在R中,以1,2,3表现。
factor之所以重要是因为factor被用在在很多建模函数中,如lm( ), glm( )等这些函数常被用于统计线性模型中。
带有label等factor通常由于简单的整型数值向量数组,因为具有易读性。例如一组变量,有male和female两组比普通数值型向量:1,2,更容易理解。在很多数据集中,你会发现一些变量,被标注为1,2,对于研究人员来说,并不容易了解这些数值是一个真实的数字还是仅仅代表一类。如果使用factor变量,那么为代label标签编码就是所有的。factor是一种构建变量的方法,并且具有易读性。
factor可以使用factor( )函数创建:
factor( )函数:
- is.factor( ):判断数据是否为factor模式,并返回一个逻辑值TRUE或FALSE
- is.ordered( ):判断数据是否是有序的,并返回一个逻辑值TRUE或FALSE。
- as.factor( ):将参数强制转换为factor类型,是factor( )的缩写形式。
- as.ordered( ):按顺序返回x
将瞳孔颜色重编码成因子:
> eye.colors <- factor(c("brown","blue","blue","green","brown","brown","browm"))
> levels(eye.colors) #levels函数可以展示一个factor的所有水平
[1] "blue" "browm" "brown" "green"
factor( )的输入是一组char类型向量。
例如:呼叫中心一个数据分析包含BATCH、online、client三类分工,每个小组包含若干人员,同时记录中包括美人的技术水平,以及在本项目中的工作时间等信息。
Mac中使用>read.csv( )命令导入.csv(以逗号分隔符等形式保存数据的文件格式),获取相关的数据信息,
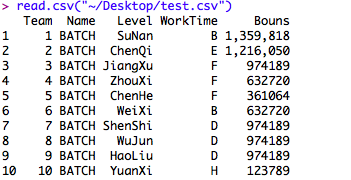
将读取的信息赋值给x
> x<-read.csv("~/Desktop/test.csv")