专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
深度学习入门笔记(十八):卷积神经网络(一)
推荐博客:大话卷积神经网络CNN(干货满满)
1、Padding填充
为了构建深度神经网络,需要学习很多东西,除了前面讲过的最基本的卷积,还需要学会使用的一个基本的卷积操作就是 padding,一起来看看它是如何工作的。
我们在 深度学习入门笔记(十六):计算机视觉之边缘检测 中讲过卷积这个例子,如果用一个3×3的过滤器卷积一个6×6的图像,那么最后会得到一个4×4的输出(也就是一个4×4矩阵)。这背后的数学解释是,如果有一个 的图像,用 的过滤器做卷积,步长是1,那么输出的维度就是 ,即 。
这样的话会有两个缺点:
- 第一个缺点是,每次卷积,图像就会缩小,从6×6缩小到4×4,再多做几次之后,比如当一个100层的深层网络,每经过一层图像都缩小,经过100层网络后,就会得到一个很小很小的图像,可能是1×1,可能是别的,但我们不想让图像在每次识别边缘或其他特征时都缩小。
- 第二个缺点是,如果是在角落边缘的像素,这个绿色阴影标记只被一个输出所触碰或者使用,因为它位于这个3×3的区域的一角;但如果是在中间的像素点,比如红色方框标记,就会有许多个3×3的区域与之重叠,所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着丢失了图像边缘位置的许多信息。

为了解决问题,在卷积操作之前可以填充这幅图像。
比如在这个案例中,可以沿着图像边缘再填充一层像素,这样6×6的图像就被填充成了8×8。如果用3×3的图像对这个8×8的图像卷积,得到的输出就不是4×4而是6×6,这样就得到了一个尺寸和原始图像相同的图像。
习惯上是用0去填充!如果 是填充的数量,在这个案例中 ,因为在原始图像周围填充了一个像素点,输出也就变成了 ,所以就变成了 ,即 ,和输入的图像一样大。这样的话,涂绿的像素点(左边矩阵)影响了输出中的这些格子(右边矩阵)。这样一来,丢失信息或者更准确来说角落或图像边缘的信息发挥的作用较小的这一缺点就被削弱了。
填充像素通常有两个选择,分别叫做 Valid 卷积和 Same 卷积:
- Valid 卷积意味着不填充,这样的话, 。
- Same 卷积意味着填充,且输出大小和输入大小是一样的。
习惯上,计算机视觉中滤波器大小 是奇数,甚至可能都是这样,比如1,3,5,为什么很少能看到偶数的过滤器,大概有两个原因:
- 第二个原因是,如果 是一个偶数,那么只能使用一些不对称填充,而只有 是奇数的情况下,Same 卷积才会有自然的填充,而不是左边填充多一点,右边填充少一点,这样不对称的填充。
- 第二个原因是,当有一个奇数维过滤器,比如3×3或者5×5的,它就有一个中心点。有时在计算机视觉里,如果有一个中心像素点会更方便,便于指出过滤器的位置。
看起来,也许这些都不是为什么 通常是奇数的充分原因,但如果看了卷积的文献,你就会经常会看到3×3的过滤器,也可能会看到一些5×5,7×7的过滤器,甚至有些时候会是1×1的,后面会谈到它以及什么时候它是有意义的。
2、卷积步长
卷积中的步幅是另一个构建卷积神经网络的基本操作,来看一个例子。
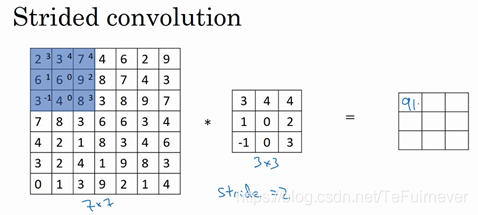
如果也想用3×3的过滤器卷积这个7×7的图像,和之前不同的是,现在步幅设置成了2。第一个位置还是和之前一样取左上方的3×3区域的元素的乘积,再加起来,最后结果为91,然后向右移动两个空格,以此类推。
所以这个例子中是用3×3的矩阵卷积一个7×7的矩阵,得到一个3×3的输出,计算公式还是和之前一样,过程如下:
如果用一个
的过滤器卷积一个
的图像,padding 为
,步幅为
,在这个例子中
,那么输出变为
,其实之前的例子也是一样,只不过
,而在现在这个例子里
,
,
,
,
,即3×3的输出。
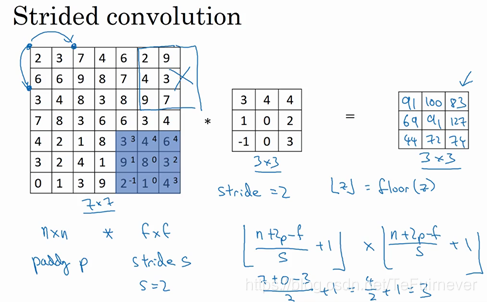
现在只剩下最后的一个细节了,如果商不是一个整数怎么办?在这种情况下是会向下取整的,
就是向下取整的符号,也叫做对
进行地板除(floor),这意味着
向下取整到最近的整数。这个原则具体实现的方式是,只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算;如果有任意一个蓝框移动到了外面,那就不要进行相乘操作,这是一个惯例。
3、三维卷积
卷积不仅仅可以发生在二维图像上,也可以发生在三维立体上。
来看一个例子,假如说不仅想检测灰度图像的特征,也想检测 RGB 彩色图像的特征。如果彩色图像是6×6×3,这里的3指的是三个颜色通道,可以想象成3个6×6图像的堆叠,为了检测图像的边缘或者其他的特征,不是把它跟原来的3×3的过滤器做卷积,而是跟一个三维的3×3×3的过滤器卷积,这样这个过滤器也有三层,对应红绿、蓝三个通道。
给这些起个名字(原图像),这里的第一个6代表图像高度,第二个6代表宽度,这个3代表通道的数目。同样地,过滤器也有一个高,宽和通道数,并且图像的通道数必须和过滤器的通道数匹配,所以这两个数(紫色方框标记的两个数,3)必须相等。
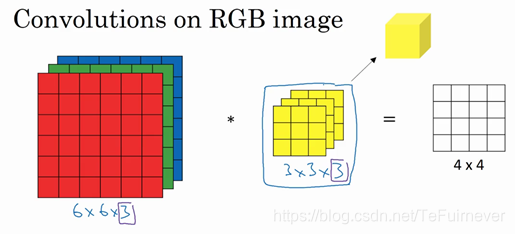
还是卷积的过程,最后一个数字通道数必须和过滤器中的通道数相匹配。
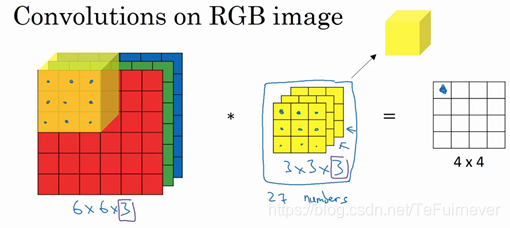
把过滤器先放到最左上角的位置,这个3×3×3的过滤器有27个数,27个参数就是3的立方,依次取这27个数,然后乘以相应的红绿蓝通道中的数字:
- 先取红色通道的前9个数字,
- 然后是绿色通道,
- 然后再是蓝色通道,
- 乘以左边黄色立方体覆盖的对应的27个数,
- 然后把这些数都加起来,就得到了输出的第一个数字。
如果要计算下一个输出,就把这个立方体滑动一个单位,执行上面的操作,以此类推。
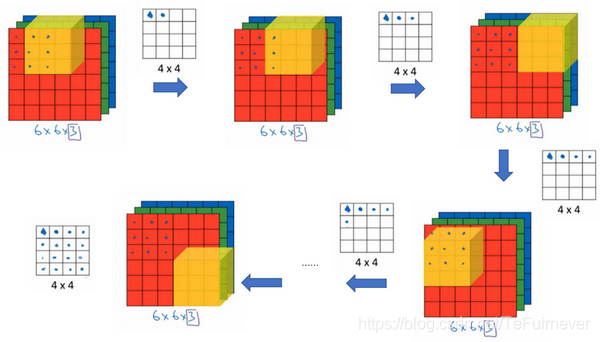
那么,这个能干什么呢?
举个例子,这个过滤器是3×3×3的,如果想检测图像红色通道的边缘,那么可以将第一个过滤器设为
,和之前一样,而绿色通道全为0(
),蓝色也全为0。这样的三个矩阵堆叠在一起形成一个3×3×3的过滤器就是一个检测垂直边界的过滤器,且只对红色通道有用。
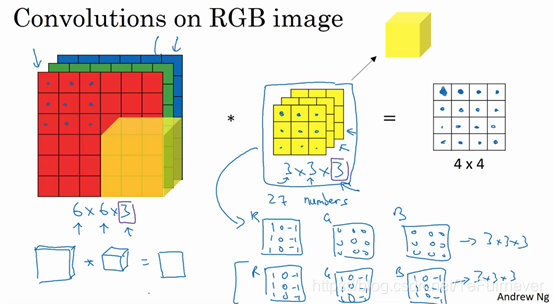
或者如果你不关心垂直边界在哪个颜色通道里,那么可以用一个这样的过滤器,
,
,
,三个通道都是这样的。按照计算机视觉的惯例,过滤器可以有不同的高,不同的宽,但是必须一样的通道数。
现在我们已经了解了如何对立方体卷积,还有最后一个概念就是,如果不仅仅想要检测垂直边缘怎么办?如果同时检测垂直边缘和水平边缘,还有45°倾斜的边缘,还有70°倾斜的边缘怎么做?换句话说,如果想同时用多个过滤器怎么办?
一个6×6×3的图像和这个3×3×3的过滤器卷积,得到4×4的输出:
- 第一个过滤器可能是一个垂直边界检测器或者是学习检测其他的特征;
- 第二个过滤器可以是一个水平边缘检测器。
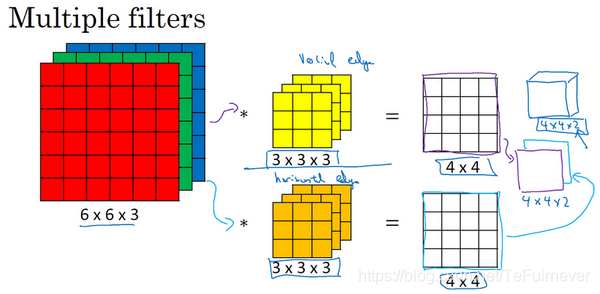
所以和第一个过滤器卷积,可以得到第一个4×4的输出,然后卷积第二个过滤器,得到另一个不同的4×4的输出,待做完卷积之后把这两个4×4的输出,把两个输出堆叠在一起得到了一个4×4×2的输出立方体。
小结一下 维度问题,如果有一个 的输入图像,在上面是6×6×3, 是通道(或者深度)数目,然后卷积上一个 ,在上面是3×3×3,按照惯例,这个(前一个 )和这个(后一个 )必须数值相同,然后就得到了 ,这里 其实就是下一层的通道数,就是用的过滤器的个数,在上面就是4×4×2。这对立方体卷积的概念真的很有用!用它的一小部分直接在三个通道的 RGB 图像上进行操作,更重要的是,可以检测两个特征,比如垂直和水平边缘或者10个或者128个或者几百个不同的特征,并且输出的通道数会等于准备要检测的特征数。
4、单层卷积网络
做了这么多准备之后,终于可以开始构建卷积神经网络的卷积层,下面来看个例子。
通过两个过滤器卷积处理一个三维图像,并输出两个不同的矩阵:
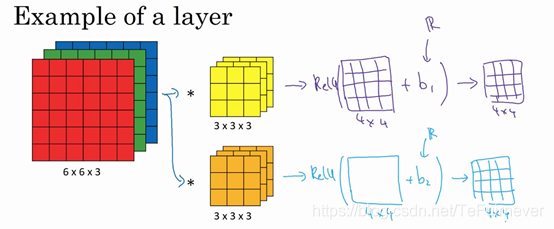
最终各自形成一个卷积神经网络层,然后增加偏差(实数),通过 Python 的广播机制给这16个元素都加上同一偏差,然后应用非线性激活函数 ReLU,输出结果是一个4×4矩阵。对于第二个4×4矩阵,是加上了不同的偏差(实数),然后应用非线性函数,最终得到另一个4×4矩阵。然后重复之前的步骤,把这两个矩阵堆叠起来,得到一个4×4×2的矩阵。
广播机制看这里:深度学习入门笔记(五):神经网络的编程基础
通过计算,从6×6×3的输入推导出一个4×4×2矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
注意,前向传播中一个操作就是
,其中
,执行非线性函数得到
,即
,输入是
,也就是
,过滤器用变量
表示。在整个卷积过程中,对这3×3×3=27个数进行操作,其实是27×2(因为用了两个过滤器),取这些数做乘法,实际执行了一个线性函数,得到一个4×4的矩阵,卷积操作的输出结果是一个4×4的矩阵,它的作用类似于
,也就是这两个4×4矩阵的输出结果,然后加上偏差。
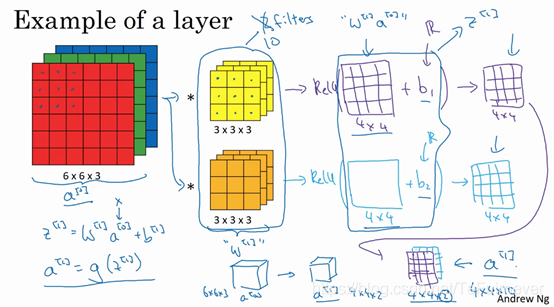
这一部分(图中蓝色边框标记的部分)就是应用激活函数 ReLU 之前的值,它的作用类似于
,最后应用非线性函数,得到的这个4×4×2矩阵,成为神经网络的下一层,也就是激活层,这就是
到
的演变过程。
示例中有两个过滤器,也就是有两个特征,因此最终才得到一个4×4×2的输出,但如果用了10个过滤器,而不是2个,最后会得到一个4×4×10维度的输出图像,因为我们选取了其中10个特征映射(而不仅仅是2个)将它们堆叠在一起,形成一个4×4×10的输出图像,也就是 。
为了加深理解,来做一个练习。
假设现在有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢???
来一起计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数,然后加上一个偏差,用参数 表示,现在参数增加到28个,有10个过滤器,即28×10,也就是280个参数。不过,请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个,即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作 避免过拟合。
避免过拟合的方式看这里:深度学习入门笔记(十):正则化。
5、总结
最后总结一下用于描述卷积神经网络中的一层(以 层为例),也就是卷积层的各种标记:
这一层是卷积层,用 表示过滤器大小,上标 用来标记 层,上标 表示 层中过滤器大小为 ;用 来标记 padding 的数量,valid 卷积,即无 padding,same 卷积,即选定 padding;用 标记步幅。
这一层的输入会是某个维度的数据,表示为 , 表示某层上的颜色通道数。只要稍作修改,增加上标 ,即 ,就变成了上一层的激活值。
使用图片的高度和宽度可以都一样,但也有可能不同,所以分别用上下标 和 来标记,即 , 层的输入就是上一层的输出,因此上标是 ,这一层中会有输出(图像),其大小为 。计算方式前面提到过,至少给出了高度和宽度, (注意: 直接用这个运算结果,也可以向下取整)。
那么通道数量又是什么?这些数字从哪儿来的?
输出图像也具有深度,等于该层中过滤器的数量,就是输入通道数量,所以过滤器维度等于 。应用偏差和非线性函数之后,这一层的输出等于它的激活值 (三维体),即 。当执行批量梯度下降或小批量梯度下降时,如果有 个例子,就是有 个激活值的集合,那么输出 。
该如何确定权重参数,即参数W呢?
过滤器的维度已知,为 ,这只是一个过滤器的维度,如果是多个, 是过滤器的数量,权重也就是所有过滤器的集合再乘以过滤器的总数量,即 。
最后看看偏差参数,每个过滤器都有一个偏差参数(实数),它是某维度上的一个向量,为了方便,在代码中常常表示为一个1×1×1× 的四维向量或四维张量。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程
