遗传算法是一种受自然选择生物过程启发的优化方法。 它基于变异,交叉和选择等术语,在生物课上已经遇到过这些术语。 关于遗传算法的基本用法有很多文章和博客文章,但是遗传算法如何用于机器学习的例子并不多。
在这篇文章中,您将学习如何使用遗传算法进行特征选择。 Python代码是从头开始编写的,因此您可以遵循算法背后的逻辑。 玩得开心!
Dataset
Feel free to use full code hosted on GitHub.
我们将直接深入研究Python示例,并根据代码片段解释遗传算法。
首先,我们导入所需的所有对象。
import random
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
SEED = 2018
random.seed(SEED)
np.random.seed(SEED)
出于演示目的,我们将使用简单数据集,但您可以将相同的逻辑应用于更复杂的任务。 Boston Housing数据集用于预测房价的经典回归任务。 波士顿地区有13个数字和分类变量构成房屋价格。 幸运的是,sklearn库已经附带了数据集,因此加载它很简单。
dataset = load_boston()
X, y = dataset.data, dataset.target
features = dataset.feature_names
您可以阅读更多关于功能的描述这里。
让我们计算线性回归估计的CV得分。 我们选择均方误差(MSE)作为度量:
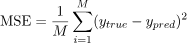
est = LinearRegression()
score = -1.0 * cross_val_score(est, X, y, cv=5, scoring="neg_mean_squared_error")
print("CV MSE before feature selection: {:.2f}".format(np.mean(score)))
CV MSE为37.22。 它的计算假设考虑了所有特征。 通过适当的特征选择算法,即选择对模型最重要的变量并跳过冗余的变量,可以减少这种误差。 有一些特征选择方法,其中包括:
- Recursive feature elimination,
- Feature selection based on feature importances from Random Forest estimator,
- Boruta algorithm.
事实证明,我们也可以使用遗传算法进行特征选择,效果非常好。 让我们为波士顿住房问题实施它,看看它是如何表现的!
Genetic algorithm
Preliminaries
Feel free to use full code hosted on GitHub.
遗传算法由不同的操作和参数组成,因此将其作为Python类包含在内是有益的。 我们将使用描述遗传算法的几个参数初始化GeneticSelector。
def __init__(self, estimator, n_gen, size, n_best, n_rand,
n_children, mutation_rate):
# Estimator
self.estimator = estimator
# Number of generations
self.n_gen = n_gen
# Number of chromosomes in population
self.size = size
# Number of best chromosomes to select
self.n_best = n_best
# Number of random chromosomes to select
self.n_rand = n_rand
# Number of children created during crossover
self.n_children = n_children
# Probablity of chromosome mutation
self.mutation_rate = mutation_rate
if int((self.n_best + self.n_rand) / 2) * self.n_children != self.size:
raise ValueError("The population size is not stable.")
参数的含义将在本文的课程中阐明。 接下来的部分将向类中添加后续方法,同时解释定义和逻辑。
Genes
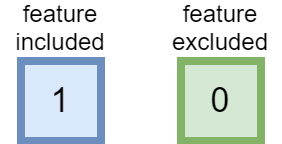
Boston Housing数据集中有13个功能。 使用遗传算法命名法,一个特征称为基因。 在特征选择过程中,它可以包括(1)或排除(0)。
Chromosome
13个基因的列表称为染色体。 染色体包含哪些特征包含在内并被排除在外的信息。

Population
群体包含不同染色体的几个实例。 它只是不同功能子集的集合。

第一批n_size染色体是通过随机排除特征而创建的。 我们在我们的类中添加了一个initilize方法。
def initilize(self):
population = []
for i in range(self.size):
chromosome = np.ones(self.n_features, dtype=np.bool)
mask = np.random.rand(len(chromosome)) < 0.3
chromosome[mask] = False
population.append(chromosome)
return population
概率0.3是任意选择的,但建议避免大的概率。 我们不想创建排除所有变量的染色体。
Fitness
我们的目标是选择最小化CV MSE的功能子集。 计算群体中每条染色体的适合度得分的函数如下:
def fitness(self, population):
X, y = self.dataset
scores = []
for chromosome in population:
score = -1.0 * np.mean(cross_val_score(self.estimator, X[:,chromosome], y,
cv=5,
scoring="neg_mean_squared_error"))
scores.append(score)
scores, population = np.array(scores), np.array(population)
inds = np.argsort(scores)
return list(scores[inds]), list(population[inds,:])
适应度函数返回排序分数列表和基于分数排序的染色体列表。 这两个列表将用于选择过程。
Selection
下一步是选择。 我们根据CV分数选择n_best染色体,以便我们的群体朝着最佳解决方案移动并随机选择n_rand染色体,这样我们的优化算法就不会陷入局部最优。
def select(self, population_sorted):
population_next = []
for i in range(self.n_best):
population_next.append(population_sorted[i])
for i in range(self.n_rand):
population_next.append(random.choice(population_sorted))
random.shuffle(population_next)
return population_next
Crossover
我们混合了两个人的DNA。 此操作称为交叉,并为每对染色体创建n_children。

我们在我们的类中添加交叉方法,它混合了先前选择的n_best + n_rand父类的基因。
def crossover(self, population):
population_next = []
for i in range(int(len(population)/2)):
for j in range(self.n_children):
chromosome1, chromosome2 = population[i], population[len(population)-1-i]
child = chromosome1
mask = np.random.rand(len(child)) > 0.5
child[mask] = chromosome2[mask]
population_next.append(child)
return population_next
Mutation
最后一个操作是改变染色体。 染色体稍微改变一点,以免过快地收敛到局部最优。 该变化涉及以较小概率随机排除特征。

def mutate(self, population):
population_next = []
for i in range(len(population)):
chromosome = population[i]
if random.random() < self.mutation_rate:
mask = np.random.rand(len(chromosome)) < 0.05
chromosome[mask] = False
population_next.append(chromosome)
return population_next
注意,首先用概率self.mutation_rate随机选择变异染色体,然后每个基因可以以0.05的概率改变。 这些概率不应太大,以便遗传算法可以收敛。
Generation
The genetic operations:
selection,
crossover and
mutation
are repeated so that each population should become better and better in terms of the CV scores.
一次迭代称为生成,可以通过下面的图片进行总结。
该方法生成调用遗传操作并保存每一代的最佳结果。
def generate(self, population):
# Selection, crossover and mutation
scores_sorted, population_sorted = self.fitness(population)
population = self.select(population_sorted)
population = self.crossover(population)
population = self.mutate(population)
# History
self.chromosomes_best.append(population_sorted[0])
self.scores_best.append(scores_sorted[0])
self.scores_avg.append(np.mean(scores_sorted))
return population
Fit
最后一步是传递数据并执行遗传算法。 还有一种方法可以返回具有最佳特征的染色体(来自上一代的最佳染色体)和绘图功能。
def fit(self, X, y):
self.chromosomes_best = []
self.scores_best, self.scores_avg = [], []
self.dataset = X, y
self.n_features = X.shape[1]
population = self.initilize()
for i in range(self.n_gen):
population = self.generate(population)
return self
@property
def support_(self):
return self.chromosomes_best[-1]
def plot_scores(self):
plt.plot(self.scores_best, label='Best')
plt.plot(self.scores_avg, label='Average')
plt.legend()
plt.ylabel('Scores')
plt.xlabel('Generation')
plt.show()
Results
我们需要使用GeneticSelector类的所有部分来执行特征选择。 让我们将遗传算法应用于Boston Housing数据集,并在特征选择后计算CV得分。
sel = GeneticSelector(estimator=LinearRegression(),
n_gen=7, size=200, n_best=40, n_rand=40,
n_children=5, mutation_rate=0.05)
sel.fit(X, y)
sel.plot_scores()
score = -1.0 * cross_val_score(est, X[:,sel.support_], y, cv=5, scoring="neg_mean_squared_error")
print("CV MSE after feature selection: {:.2f}".format(np.mean(score)))
现在,CV MSE是28.92! 这是一项重大改进(特征选择前为37.22)。 我们介绍了遗传优化的历史,每一代的得分和平均得分最低。
正如我们在第四代之后所看到的那样,优化器融合了。
结果如何与其他方法一起使用? 下表总结了其他特征选择算法的CV分数(代码可以在这里找到(https://github.com/dawidkopczyk/genetic/blob/master/genetic_other.py))。
对于该特定问题,使用遗传算法的特征选择证明是最好的。 这可以通过检查相对大量的不同特征子集的事实来解释(每8代中有100个人)。 实际上,遗传算法的执行时间在数据集更复杂的情况下可能是一个缺点,而诸如Boruta之类的其他方法可能更合适。
请注意,使用正确的高度优化的神经网络或随机森林估算器可以获得类似或更好的结果,而无需任何特征选择。 但是,对于更复杂的回归或分类,通常使用特征选择和复杂估计。
Other areas
算法在哪里也适用? 有一个返回波士顿地区房屋价格的模型,我们还要问另一个问题 - 房屋价格最小的特征值组合是什么? 假设特征值是离散化的,我们也可以用遗传算法进行这种优化。 在交通(TensorTraffic project1)和旅行商问题中可以找到相同的应用程序。

在流量优化中,可以通过遗传算法搜索最佳信号定时。 资料来源:TensorTraffic
Conclusions
我们已成功应用遗传算法进行特征选择。 事实证明,遗传优化对该特定问题非常有效。 现在是时候将遗传算法应用到您的机器学习任务中了!