进化算法之遗传算法
进化算法Evoluation Algorithms(EAs)有以下三个特征:
- Population-Based:进化算法的优化过程可以描述为:从当前一些比较差的解集当中生成相对比较好的一点的解集。而当前的解集叫做Population。
- Fitness-Oriented: 如果现在已经有了许多解,那该怎么比较两个解的好坏呢?因此就需要一个衡量一个解好坏的标准:适应性函数。适应性函数能对每一个解赋予它们一个对应的适应度。
- Variation-Driven:如果在当前的pululation中没有合适的解或者不是最优解,我们就希望做点什么从而得到最优解。因此,这是,每一个解都要经过一些变化,去产生新的解。
下面介绍一个具体的算法:遗传算法 Genetic Algorithm(GA)
遗传算法(Genetic Algorithm, GA)
遗传算法是基于随机的经典进化算法。这里随机的意思是,为了使用遗传算法找到一个解,我们将把一些随机变换应用到当前的解里,从而产生变化,生成新的解。注意:遗传算法(EA)也会被叫做简单遗传算法(Simple Genetic Algorithm,SGA),原因就是它相比于其他遗传算法来说是最简单的。
遗传算法启发与达尔文的进化论。这是一个缓慢渐进的过程,通过做出微小又缓慢的改变发挥作用。因此,遗传算法也是通过对现有解做微小又缓慢的改变,直到得到最好的解。
遗传算法的原理
遗传算法作用在整个“种群”(Population)当中。这个“种群”包含一些个体,每一个个体实际上就是一种解决方法(一个解)。而每一个个体有一个染色体。通常这个染色体是一些特征的集合,它独一无二地描述了相对应的个体。同时,染色体里面有许多基因。在计算机里,我们可以用许多方法去表示基因。如下图,用0和1去表示基因。

当然,每一个个体都要用一个适应度,这个适应度是由适应函数给出的。它可以用于评估两个个体之间的好坏。适应度越高,表示该个体越适合在该“环境”下,那么就应该被保留下来;适应度越低,表示个体不适合该“环境”,或者说解不够好,那么就应该淘汰这个个体。
我们把适应度比较高的个体放在一个交配池(mating pool)里。在交配池里的个体就叫做父辈。从交配池中任意选出来的两个个体将会产生一个孩子。通过交配两个高质量的父辈,我们期望会得到一个比父辈更高质量的孩子出来。当然,如果产生出来的孩子适应度比父辈还低,那么这个孩子就会被淘汰掉。通过这样不断的迭代,直到产生了具有最优适应度的孩子或达到了预先的要求为止。
当前种群中产生出来的孩子具有父辈的一些特点。且这些孩子就不在改变了。而接着再产生下一代的时候,可能会生成跟上一代相同的孩子,且父辈们的缺点都保留着。因此,我们就希望孩子也要加入到种群当中,甚至是淘汰掉父辈们。
其流程图大概如下:
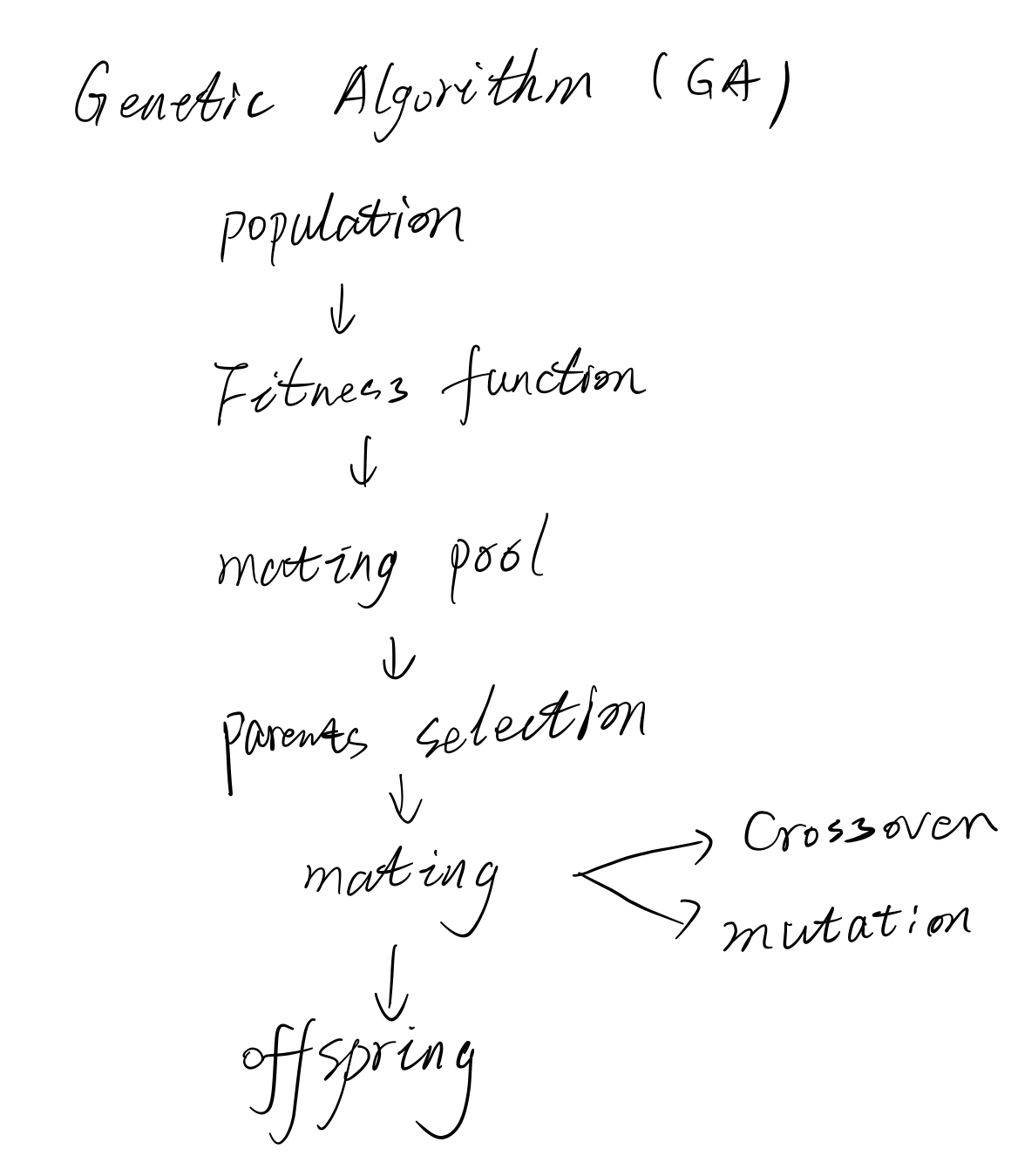
到这里为止,为了完全理解GA算法,我们必须弄清楚以下两个问题:
- 如何从连个父辈中生成孩子?
- 如何轻微地修改孩子使得其成为一个不同的个体?
下面介绍染色体的表示方法和进化过程。
染色体的表示方法和进化
现存在有许多有效表示染色体的方法。染色体的表示方法针对具体问题而变化。一个好的表示方法能缩小整个搜索空间,减少搜索时间,从而提高算法的效率。
现有的表示染色体的方法:
- Binary(二进制):就是每一个染色体都变表示成0和1的字符串。
- Permutation(排列组合):这种表示方法在面对一些有序问题的时候很有效,如旅行商人问题。
- Value(数值):就把染色体编码成一个具体的实数。
例如,我们用二进制去表示数字7:
\[0 1 1 1\]
\(0111\)就是我们说的染色体,而里面的每一个字符就是一个基因。
学过高中生物的同学应该知道,染色体的表现形式有两种:
- 基因型:即染色体中所有基因的集合。
- 表现型:即物理上表现出来的形状。
在上面这个例子中,\(0111\)就是基因型,数字7就是表现型。
在明白了染色体的表现方法后,这下来我们看如何去计算每一个染色体它的适应度值(fitness value)?
假设适应函数(fitness function)为:
\[f(x)=2x+2\]
其中\(x\)就是染色体。
那么,数字7这条染色体它的适应函数值就为:
\[f(7)=2*7 + 2 = 16\]
计算染色体适应函数的过程就称为进化(evolution)
初始化
在表示完每一个个体之后,接下来就是选着一定数量的个体作为种群.
选择
然后就是基于给定的适应函数,选择出适应值比较高(高出指定的值)的个体,即从种群中选择一些个体,放在交配池里。
变异
然后从交配池中有序地选着两个个体出来作为父辈(如1-2,3-4等等)。另一种选着方法是每次都随机选两个。
针对选出来的两个父辈,进行变异操作。包括两种操作:
- 交叉变换
- 突变
下图是交叉变换和突变的示意图:
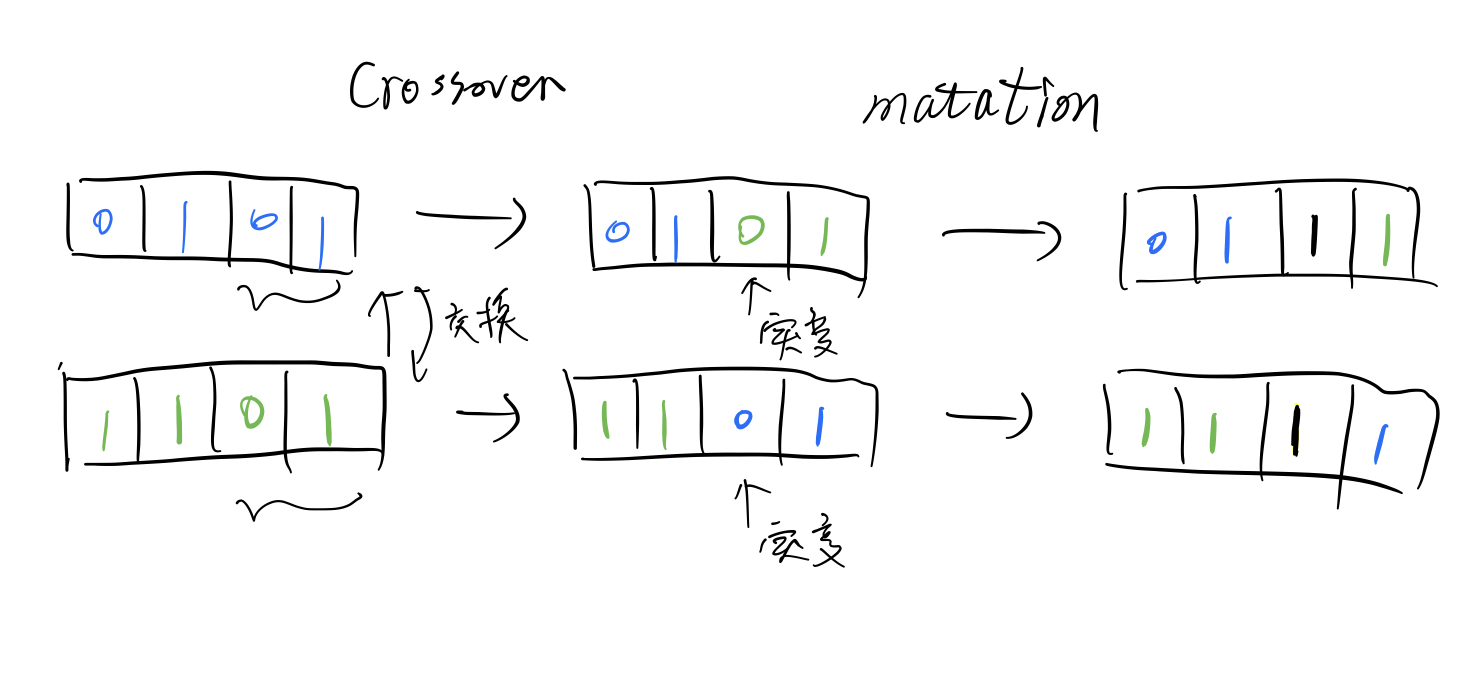
交叉变换
遗传算法的交叉变换也类似于生物学上染色体的交叉变换。通过拆分每一哥父辈的一部分染色体,然后在重新组合形成新的染色体。孩子从每一个父辈得到的基因数量是随机的。(因为本文介绍的算法就是基于随机的进化算法,也是最简单的进化算法。)。有时候,父辈染色体会被拆成两部分,拆分的位置随机,然后选择交换父辈们上半段的染色体或下半段染色体。最后的结果就是生成新的染色体。而这种只断开染色体一次的操作就称为单点交换(此外,还有多点交换)。

突变
针对每一个孩子,任意改动它的一些基因。当然,具体要怎么改依赖于染色体的表现形式。如果染色体是用二进制表示的,那么突变操作无非就是把某些为上的值从0改成1或者是从1改成0。但是如果染色体是用数值型的方法表示的,那么就只能在值域内随机选择了。
引用
https://www.linkedin.com/pulse/introduction-optimization-genetic-algorithm-ahmed-gad/