【参考资料】
【1】《模式识别与智能计算的matlab实现》
【2】《遗传算法的数学基础》
【3】《随机过程》
【4】《概率论与数理统计》
一、数学基础
随机过程
定义: 设 是一个概率空间,T是一个实的参数集,定义 和T上的一个二元函数 ,对于任意的固定的 , 是 上的随机变量,则称 为该概率空间上的随机过程。
简单理解随机过程就是一个带参数(通常这个参数是时间)的随机变量。 重新数理下概率论中的几个基本概念:
基本事件(样本点): 随机试验的一个结果,例如丢筛子可以丢出1,2,3…
样本空间: 全部随机事件的集合,以丢筛子为例
随机事件: 样本空间的一个子集,诸如丢筛子丢出偶数点的集合
随机变量: 对于任意实数x,集合
是一个随机事件,则称X为随机变量。
理解: 随机变量是函数概念的推广,这也是为什么概率论的基础是测度论的原因。随机变量把随机试验的结果映射到一个实数。比如,对于掷骰子这个随机试验,我可以定义一个随机变量是丢出每个数的概率,那么它是把{1},{2},{3},{4},{5},{6}分别对应到实数1/6;当然我也可以定义丢出偶数或奇数作为一个随机变量,那么它把{1,3,5}和{2,4,6}分别对应到实数1/2。当这个随机变量是连续的时候,这种映射关系就是概率密度函数
马尔可夫链
马儿可夫过程: 设
的状态空间是S,如果存在:
,则称其为马儿可夫过程。
如果此处参数集和状态集都是离散的,称其为**马儿可夫链**。
简单讲当前发生某事的概率只和上一时刻的状态有关,与再之前的都无关。
通常一个马儿可夫链可以表示为一个转移概率矩阵,参考笔记《【机器学习笔记18】隐马尔可夫模型》
二、遗传算法
经典遗传算法的流程
第一步: 将问题空间进行编码
例如求解函数极值,那么将x轴的坐标映射到固定位长的二进制的离散值,例如0000100010。此时这串编码就相当于DNA序列,而每一位就是一组基因编码。
通过这种编码,我们将求解极值的问题转换为一个遗传问题,即如果能够进化出一个最好的DNA序列。
def _to_binary_code(input, length = 10):
"""
将0 ~ 100 之内的整数转换为长度为length的二进制编码
input: 输入的整数
length: 编码长度
"""
bin_str = bin(input)
return bin_str.replace('0b','').zfill(length)
第二步: 定义适应性函数
该函数表述每一个DNA序列所具备的适应性,对于求解极值问题就是0000100010对应的x轴坐标能够计算得到的y值是多少。
def _adaptive_test(code):
"""
定义问题求解函数在0 ~ 10的范围内求极大值
"""
delta = 10/RESULT_NUM
x = int(code, 2) * delta
return x + 10 * np.sin(5 * x) + 7 * np.cos(7*x)
第三步: 初始化种群,即初始化一批DNA序列,设总群数量为N
def _init_ga():
"""
该GA问题求解某函数的极值,解空间为0 ~ 100个间隔,将其
进行二进制编码,编码长度10位
"""
for i in range(0, INIT_POPULATION_NUM):
cur_population.insert(i, _to_binary_code(random.randint(0, RESULT_NUM), CODE_LENGTH))
cur_fitness.insert(i,0)
cur_fitness_temp.insert(i, 0)
new_population.insert(i, cur_population[i])
第四步: 开始迭代
4.1 选择
从上一代种群中选择适应性好的进入下一代,当前代码采用的是锦标赛方式,即重复N次,每次随机从上一代中选出若干个DNA序列,将其中最好的放入下一代
def _selector():
"""
选择算子,采用锦标赛方式: 每次选择p个种群,在其中选出适应度最好的一个,重复N次,重新生成新的一代
"""
for i in range(0, INIT_POPULATION_NUM):
cur_fitness_temp[i] = _adaptive_test(cur_population[i])
#print(cur_fitness_temp)
"""
适应度函数分两步:
1. 将全部函数值做0,1归一化
2. 每个值 转换为 f(x)/sum f(xi)
"""
t_min = np.min(cur_fitness_temp)
t_max = np.max(cur_fitness_temp)
#print(t_min, t_max)
for i in range(0, INIT_POPULATION_NUM):
cur_fitness_temp[i] = (cur_fitness_temp[i] - t_min)/(t_max - t_min)
t_sum = np.sum(cur_fitness_temp)
for i in range(0, INIT_POPULATION_NUM):
cur_fitness[i] = cur_fitness_temp[i]/t_sum
#print(cur_fitness)
for i in range(0, INIT_POPULATION_NUM):
#随机选出6个
temp_index = random.randint(0, INIT_POPULATION_NUM - 1);
temp_fit = cur_fitness[temp_index]
for j in range(0, SELECT_NUM):
ti = random.randint(0, INIT_POPULATION_NUM - 1)
if cur_fitness[temp_index] < cur_fitness[ti]:
temp_index = ti
temp_fit = cur_fitness[ti]
new_population[i] = cur_population[temp_index]
4.2 交叉
在选择出的新一代种群中,随机选择一定比例的DNA序列,进行交叉,诸如:
父DNA:11111 母DNA:00000,那么我们随机选择第3位交换,于是新的序列为 父DNA:11011 母DNA:00100
def _crossover():
"""
交叉算子,选择每个种群,随机配对后,依据一定概率进行交叉
"""
for i in range(0, INIT_POPULATION_NUM):
pick = random.randint(0, 1)
if pick < CROSS_PERCENT:
other = random.randint(0, INIT_POPULATION_NUM - 1)
#将第i个 和 第other个 进行交叉
#随机选择一个位数进行交换
index = random.randint(0, CODE_LENGTH)
mother = cur_population[i]
father = cur_population[other]
if index == 0:
old_m = mother[0]
old_f = father[0]
str_m = ""
str_m += old_f
str_m += mother[index: len(mother)]
str_f = ""
str_f += old_m
str_f += father[index: len(father)]
else:
old_m = mother[index-1: index]
old_f = father[index-1: index]
str_m = ""
str_m += mother[0:index-1]
str_m += old_f
str_m += mother[index: len(mother)]
str_f = ""
str_f += father[0:index-1]
str_f += old_m
str_f += father[index: len(father)]
#print(cur_population)
#print(other, index, mother, father, str_m, str_f)
if int(str_m, 2) <= RESULT_NUM and int(str_f, 2) <= RESULT_NUM:
new_population[i] = str_m
new_population[i] = str_f
4.3 编译
在选择出的新一代种群中,随机选择一定比例(较低)进行变异,如随机选择一位置反
def _mutation():
"""
变异算子,依据概率选择一个基因进行变异
"""
for i in range(0, INIT_POPULATION_NUM):
pick = random.randint(0, 1)
if pick < MUTATION_PERCENT:
index = random.randint(0, CODE_LENGTH)
parent = new_population[i]
old_p = parent[index-1:index]
if old_p == '0':
old_p = '1'
else:
old_p = '0'
str_p = ""
str_p += parent[0:index-1]
str_p += old_p
str_p += parent[index: len(parent)]
#如果变异后的数大于上限,则丢弃
if int(str_p, 2) <= RESULT_NUM:
new_population[i] = str_p
第五步: 在迭代一定次数后,得出一个最优值
# -*- coding: utf-8 -*-
import numpy as np
import random
import math
import matplotlib.pyplot as plt
INIT_POPULATION_NUM = 10 #初始化种群数量
RESULT_NUM = 500 #解空间大小,即有100个备选答案
CODE_LENGTH = 10 #编码长度
SELECT_NUM = 6 #每次选择的数量
CROSS_PERCENT = 0.6 #发生交叉的概率
MUTATION_PERCENT = 0.1 #发生变异的概率
cur_population = [] #当前代的种群
cur_fitness = [] #当前代的适应性
cur_fitness_temp = [] #缓存当前代的适应性数据
new_population = [] #新的一代
#中间函数见上述章节
"""
说明:
简单遗传算法的实现,参考笔记《遗传算法》
作者:fredric
日期:2018-11-20
"""
if __name__ == "__main__":
_init_ga()
ITERATOR_NUM = 200 #迭代次数
for i in range(0, ITERATOR_NUM):
print("start iterator : ", i)
_selector()
_crossover()
_mutation()
#更新当前代 和 新代
for i in range(0, INIT_POPULATION_NUM):
cur_population[i] = new_population[i]
_get_max_value()
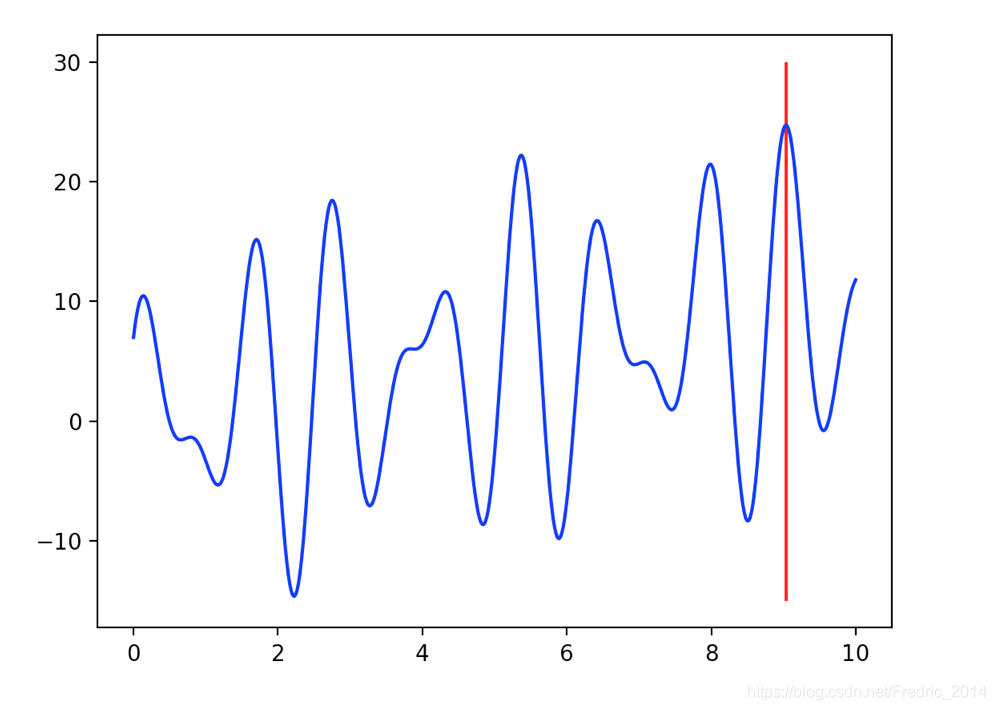
经典遗传算法的马氏链模型
定理:标准马儿可夫链是有限齐次不可约非周期的马儿可夫链。
定理:标准马儿可夫链存在极限分布。