说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。
1.需求分析
在国家一系列政策密集出台的环境下,在国内市场强劲需求的推动下,我国家用燃气灶具产业整体保持平稳较快增长。随着产业投入加大、技术突破与规模积累,在可以预见的未来,开始迎来发展的加速期。某电器公司的燃气灶产品销售额一直在国内处于领先地位,把产品质量视为重中之重,每年都要对其产品质量数据进行分析研究,以期不断完善,精益求精。本模型也是基于一些历史数据进行维修方式的建模、预测。
2.数据采集
本数据是模拟数据,分为两部分数据:
数据集:data.xlsx
在实际应用中,根据自己的数据进行替换即可。
特征数据:故障模式、故障模式细分、故障名称、单据类型
标签数据:维修方式
3.数据预处理
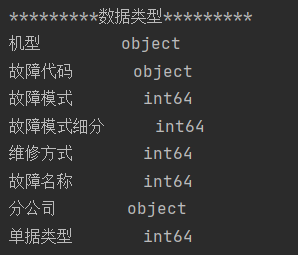
1)原始数据描述:
2)原始数据文本转换为数值:
2)数据完整性、数据类型查看:
print(data_.dtypes) # 打印数据类型
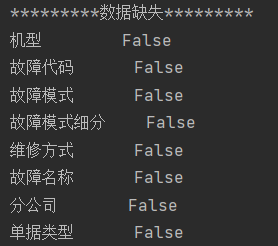
3)数据缺失值个数:
print(data_.isnull().any()) # 查看是否有NULL值
可以看到数据不存在缺失值。
4)哑特征处理
特征变量故障模式、故障模式细分、故障名称中的数值为文本类型,不符合机器学习数据要求,需要进行哑特征处理,变为0 1数值。
处理后,数据如下:
4.探索性数据分析
1)特征变量故障分析:
故障分析:在维修记录中不同部件维修数量不同,其中“电极针坏”的数量占比最多,占全部维修记录的64.12%。“热电偶坏”和“电磁阀坏”的占比次之,分别为14.87%和11.29%。
2)特征变量故障模式分析:
故障模式又分别细分为5项:“开裂”、“变形”、“老化”、“调整电极针位置”、“热电偶与电磁阀接触不良”。
3)相关性分析
说明:正值是正相关、负值时负相关,值越大变量之间的相关性越强。
5.特征工程
1)特征数据和标签数据拆分,y为标签数据,除y之外的为特征数据;
2)数据集拆分,分为训练集和尝试集,80%训练集和20%验证集;
3)数据归一化
6.机器建模
1)遗传算法简单介绍:
遗传算法,也叫Genetic Algorithm,简称 GA 算法他既然叫遗传算法,那么遗传之中必然有基因,那么基因染色体(Chromosome)就是它的需要调节的参数。我们在生物中了解到,大自然的法则是“物竞天择,适者生存”,我觉得遗传算法更适用于“优胜劣汰”。
- 优:最优解,
- 劣:非最优解。
遗传算法的实现流程:
涉及到还是适应度函数、选择、交叉、变异这几个模块。下面就这几个模块展开说明。具体的流程图解释如下:
(1)需要先对初始种群进行一次适应度函数进行计算,这样方便我们对个体进行选择,适应度值越大的越容易被保留;
(2)对群体进行选择,选择出适应度值较大的一部分优势群体;
(3)对优势种群进行 “交配”,更容易产生优秀的个体;
(4)模拟大自然变异操作,对染色体个体进行变异操作;
2)本次机器学习工作流程:
(1)种群数量NIND = 50代表第一代种群先进行50次的模型训练作为50个初始个体,每次训练的[C,G](当然每次训练的C和G还是随机初始化的)就是这个个体的的染色体;
(2)目标函数就是训练集上的分类准确度(当然下面代码用的交叉验证分数,含义其实是一样的);
(3)选择、交叉、变异、进化
(4)最后末代种群中的最优个体得到我们想要的C和Gamma,把这两个参数代入到测试集上计算测试集结果
3)应用遗传算法GA得到最优的调参结果
编号
名称
1
评价次数:750
2
时间已过 2950.9299054145813 秒
3
最优的目标函数值为:0.9611955168119551
4
最优的控制变量值为:
5
C的值:149.7418557703495
6
G的值:0.00390625
最优的空值变量C、G的值,大家在实际数据集过程种可以慢慢尝试。
4)建立支持向量机分类模型,模型参数如下:
编号
参数
1
C=C
2
kernel='rbf'
3
gamma=G
其它参数根据具体数据,具体设置。
7.模型评估
1)评估指标主要采用准确率分值、查准率、查全率、F1
编号
评估指标名称
评估指标值
1
准确率分值
0.96
2
查准率
95.02%
3
查全率
99.73%
4
F1
97.32%
通过上述表格可以看出,此模型效果良好。
8.实际应用
根据测试集的特征数据,来预测这些产品的维修方式。可以根据预测的维修方式类型,进行产品的优化和人员工作的安排。具体预测结果此处不粘贴图片了。










if __name__ == '__main__': """===============================实例化问题对象===========================""" PoolType = 'Thread' # 设置采用多线程,若修改为: PoolType = 'Process',则表示用多进程 problem = MyProblem(PoolType) # 生成问题对象 """=================================种群设置==============================""" # 本次机器学习项目实战所需的资料,项目资源如下: # 项目说明: # 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ # 提取码:thgk if BestIndi.sizes != 0: print('最优的目标函数值为:%s' % (BestIndi.ObjV[0][0])) print('最优的控制变量值为:') for i in range(BestIndi.Phen.shape[1]): print(BestIndi.Phen[0, i]) """=================================检验结果===============================""" problem.test(C=BestIndi.Phen[0, 0], G=BestIndi.Phen[0, 1]) else: print('没找到可行解。')