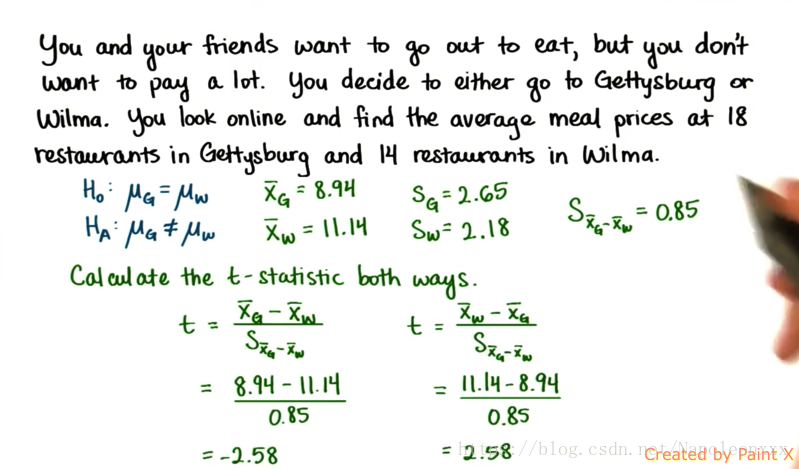前言
接着上一篇t分布,主要内容有:
- 相依样本 vs 独立样本
- 独立样本 (Independent sample)
- 独立样本t统计量
- 举例(餐厅价格)
相依样本 vs 独立样本
相依样本或重复测量,这个概念指的是为同一人提供两种条件,看看他们对这两种条件的反应。这两种条件可以是对照组和处理组,或者两种处理类型,或者可以是纵向研究,在某个时间点测量某个变量,然后在另一个时间点再次测量该变量,看看变量是否有变化。或者是预期测试和后期测试,测量处理前后变量的值。
相依样本的研究方法非常有用,因为它控制了个体差异,也就是说,如果我们给某人带来某种处理措施,下次再实施同一处理措施。这样我们可以判断在同一条件下两种不同处理措施的效果。因为我们控制了个体差异性,因此就可以使用更少的受试者,成本更低,花费时间更少。
但是也有一些不足,其中之一是残留效应(carry-over effects)。例如,假设有一种新的数学教学方法,我们想知道该方法是否有效。如果使用同一组学生来检验这一新的教学方法,不可避免的,学生第二次测试时的数学能力肯定更强。我们不知道第二个处理方式的结果是因为该处理措施有效,还是学生在第一次教学中已经学过相关数学知识。
另外我们实施处理措施的顺序可能会影响到结果。假设我们想测试两种类型的药丸。如果第一种药丸和第二种药丸有相互作用呢?按这种顺序服用的话会影响到结果。
综上所述就是为什么需要独立样本。显然,相依样本的优势就成为了独立样本的不足。相依样本的不足也成为了独立样本的优势。
对于独立样本,我们需要更多的受试者,因为我们需要随机的选择两组受试者来接受两种处理措施,我们需要更大的n来尽量控制个体差异。意味着更加消耗时间,开支也更多。而独立样本的优势是不存在残留效应。
对于独立样本来说,可以开展实验性检验,对受试者实施处理措施或者开展观察性检验,只是观察两组不同总体的特性,然后对比它们。零假设,对立假设,t统计量和作出统计决策的方式和之前都是相同的。


独立样本t统计量


举例