0. 写作目的
好记性不如烂笔头。
1. SSD
1.1 网络的框架
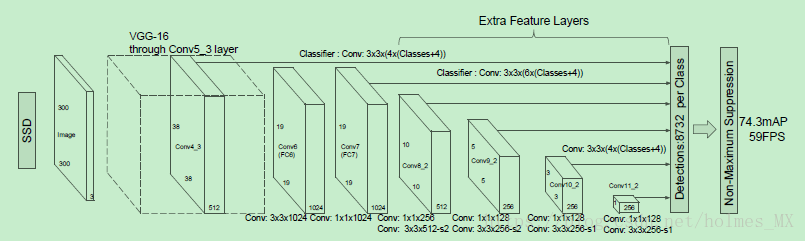
下面的第一个4表示的是4个default box(与faster R-CNN 和YOLO不同,这里是中心坐标加上宽高),
其中: classifer是通过3 * 3 * (4 * (classes + 4))的卷积实现的,得到结果即是检测的结果,然后将不同feature map的检测结果放在一起。先过滤掉confidence很低的检测结果,如可以过滤掉confidence 小于0.01。然后对每一类通过NMS。(然后一般保留前200个选择后的检测结果)

图中SSD300的Boxes数目计算方法:
SSD(300*300)中38 * 38 有4个default box, 19 * 19 有6个 defaule box, 10 * 10 有6 个default box, 5 * 5有6个default box, 3 * 3和 1 * 1有4个default box。所以共有: 38 * 38 * 4 + 19 * 19 * 6 + 10 * 10 * 6 + 5 * 5 * 6 + 3 *3 *4 +1*1*4 = 8732个预测结果。
YOLO(VGG16)的boxes数目计算方法(此处为YOLOv1):
YOLO采用的是7 * 7的feature map和 2个,因此 7 * 7 * 2 = 98个boxes。
1.2 训练匹配策略
由于SSD预测的时候在,class中包含了background类别,因此在训练的时候需要对background类别进行采样。当IOU>0.5的时候为正样本,否则为负样本。但是由于负样本远远多于正样本,如果不采取措施的话,会导致训练不稳定,因此SSD中采样,负样本为正样本的3倍。(注:YOLO中不存在选择背景,faster R-CNN也需要选择background)
如何选择负样本呢?
通过选择loss最高的top负样本。
1.3 default box的选择
如对于需要预测6个结果的cell,选择长宽比为{1, 2, 3, 1/2, 1/3},然后通过下面公式计算得到w, h。
其中对于长宽比为1时,多选择一次scale。

1.4 Data Augmentation

[Reference]
[1] SSD paper: https://arxiv.org/abs/1512.02325
[2] 理解SSD 英文版: https://medium.com/@jonathan_hui/ssd-object-detection-single-shot-multibox-detector-for-real-time-processing-9bd8deac0e06
[3] 理解SSD 英文版:https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab
[4] 理解SSD 英文版: https://medium.com/@smallfishbigsea/understand-ssd-and-implement-your-own-caa3232cd6ad