目标检测总结:SSD
之前回顾了one-stage目标检测中的Yolo系列,本文介绍另一种 one-stage 框架——SSD。
思想:
- 多尺度的特征层用于目标检测,如下图所示,共有6个不同尺度的特征层进行预测。
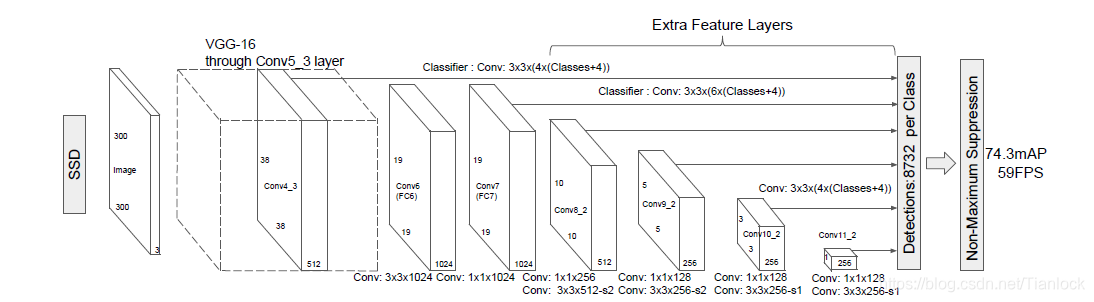
- 基于卷积的预测器,SSD通过卷积操作对对应特征层进行预测。
- 默认的边界框和长宽比,与faster RCNN类似,ssd预先指定anchor的大小,但不同的是SSD是把anchor应用到不同分辨率的特征映射中。
- 匹配策略,gtbox可能与多个anchor重叠,SSD将gtbox与gtbox的IOU>0.5的anchor相匹配,也就是允许多个重叠的anchor负责预测同一个gtbox,这简化了学习问题。
- 目标函数:
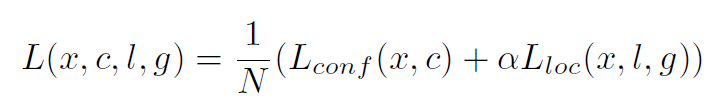
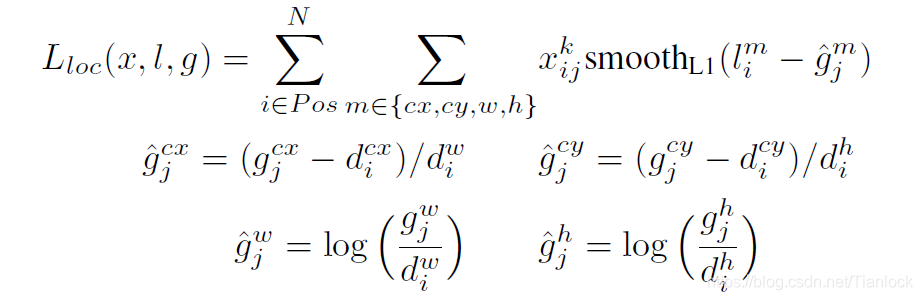
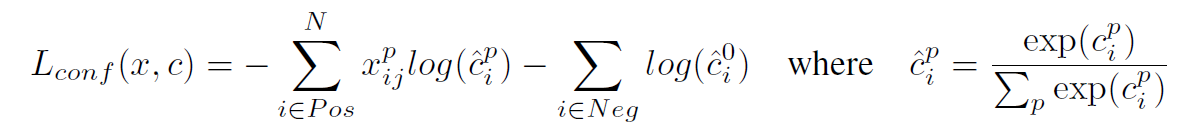
与fasterRCNN类似,ssd对于坐标回归的目标也是偏移量。 - 默认边界框的长宽比以及尺度:
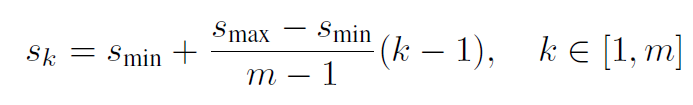
Smin取0.2,Smax取0.9,这意味着最低层有0.2的尺度,最高层有0.9的尺度,长宽比有1,2,3,1/2,1/3,我们可以为每个边界框计算w和h,另外中心点为(0,1),wh为原尺度
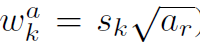
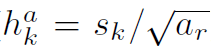
另外对于长宽比为1的,还添加了默认边界框: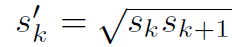
每个anchor中心点的设定: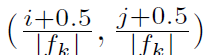
其中fk为当前特征映射层的大小,0<=i,j<fk
代码:
for k, f in enumerate(self.feature_maps):
for i, j in product(range(f), repeat=2):
f_k = self.image_size / self.steps[k]
# unit center x,y
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# aspect_ratio: 1
# rel size: min_size
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
- hard negative minning,这个与之前RCNN不同,RCNN采用的是得分最高的负例,SSD采用的是损失函数最高的边界框来进行优化。
通过代码可以知道:
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c[pos] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
- 数据增强:1原图输入2随机裁剪3变换尺度
SSD在保证了one-stage目标检测器速度的同时,依然保持了很高的精度,很多应用场景下的目标检测都是基于SSD改进的,算法相比于FasterRCNN还是比较好理解的,代码也比较容易看懂。