数据增广:
目标检测:SSD的数据增强算法
代码地址
https://github.com/weiliu89/caffe/tree/ssd
论文地址
https://arxiv.org/abs/1512.02325
数据增强:
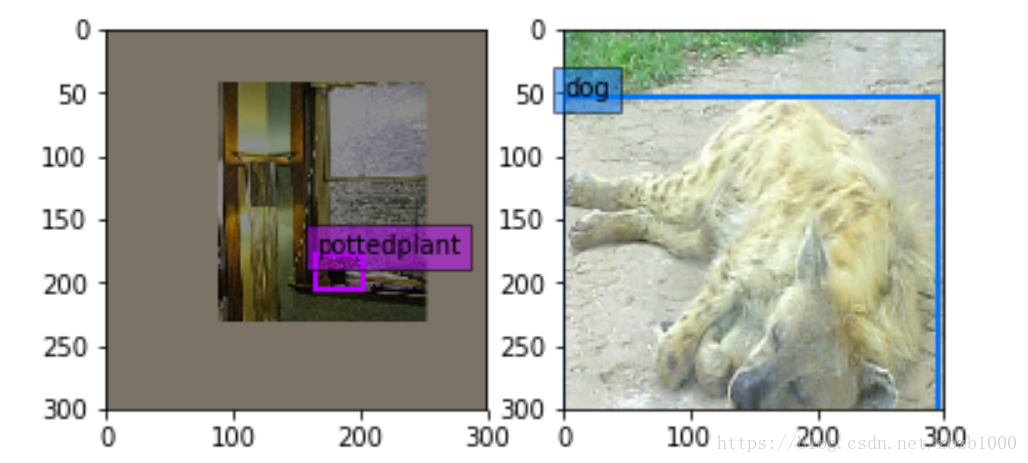
SSD数据增强有两种新方法:(1)expand ,左图(2)batch_sampler,右图
expand_param {
prob: 0.5 //expand发生的概率
max_expand_ratio: 4 //expand的扩大倍数
}
- 1
- 2
- 3
- 4
expand是指对图像进行缩小,图像的其余区域补0,下图是expand的方法。个人认为这样做的目的是在数据处理阶段增加多尺度的信息。大object通过expand方法的处理可以变成小尺度的物体训练。提高ssd对尺度的泛化性。
annotated_data_param {//以下有7个batch_sampler
batch_sampler {
max_sample: 1
max_trials: 1
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.1
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.3
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.7
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
max_jaccard_overlap: 1
}
max_sample: 1
max_trials: 50
}
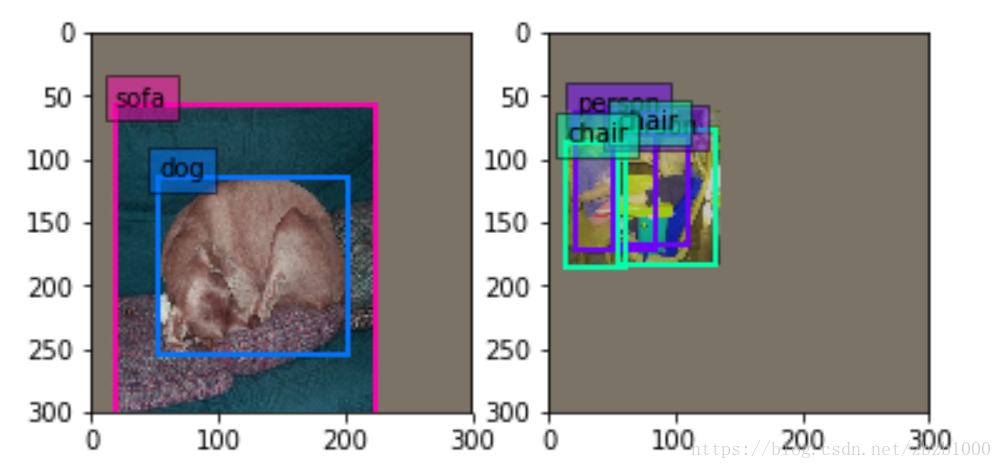
batch_sampler是对图像选取一个满足限制条件的区域(注意这个区域是随机抓取的)。限制条件就是抓取的patch和GT(Ground Truth)的IOU的值。
步骤是:先在区间[min_scale,max_sacle]内随机生成一个值,这个值作为patch的高Height,然后在[min_aspect_ratio,max_aspect_ratio]范围内生成ratio,从而得到patch的Width。到此为止patch的宽和高随机得到,然后在图像中进行一次patch,要求满足与GT的最小IOU是0.9,也就是IOU>=0.9。如果随机patch满足这个条件,那么张图会被resize到300300(**在SSD300300中**)送进网络训练。如下图。
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
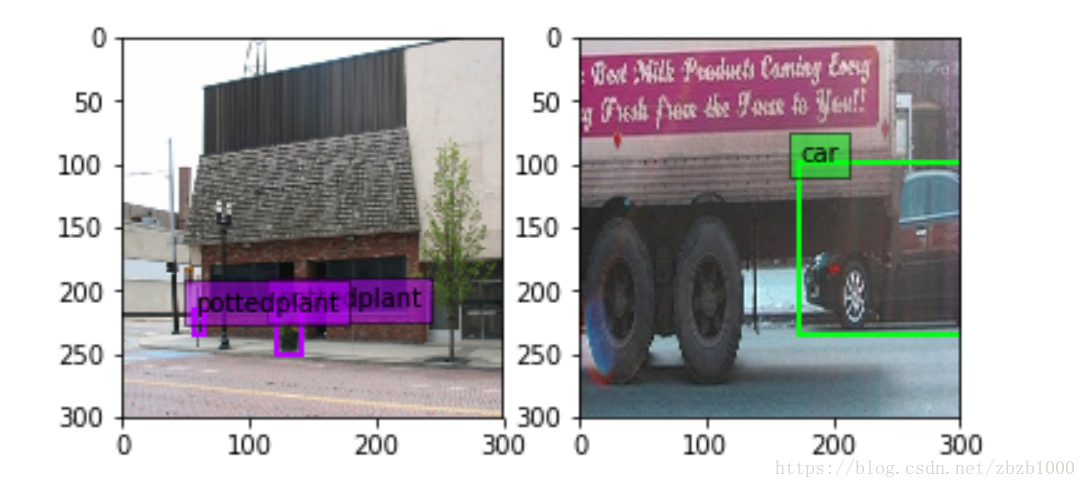
SSD数据增广中的图像变换与裁剪
SSD在数据增广部分做了很多工作,处理方法集中在load_batch函数中,首先是对每一帧图像,即每个datum做DistortImage处理,DistortImage包括亮度、饱和度,色调,颜色灰度扭曲等变换,再进行ExpandImage处理
>>>:现在的方法基本上就是靠大量训练数据(&negative sampling >>> 题外话:负采样效果好,有没有理论上的一些分析,比如稀疏、低维流形啥的),然后“分类” ;
而人类识别感觉是提取到了这类物体的 backbone/sketch,后续再加上各种颜色上的交换等,是顺理成章的 —— 是否能搞一种 attention 机制;或者是 orthogonal 叠加的机制( 形状骨架 + 换肤主题,然后再叠加)
另外总觉得 2-D 目标检测是伪命题——能否将calibration、透视变换、parts 组合成 object ... 这些结构性的机制引入进来?
seems like a fertile field
可能标注数据集也需要修正;
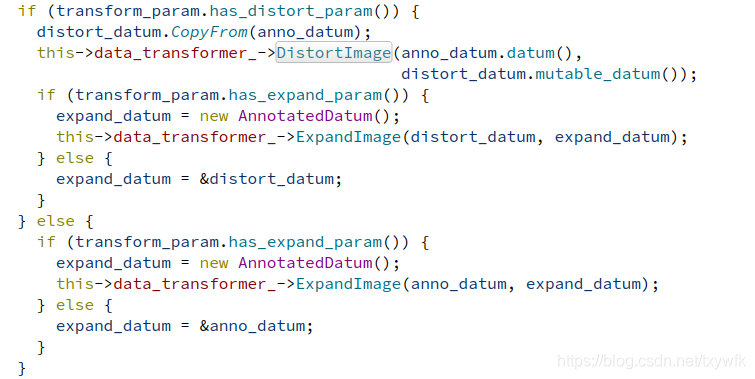
在DistortImage函数中,首先用OpenCV的 cv_img = DecodeDatumToCVMat(datum, param_.force_color())函数将图像从Datum数据中解码出来,数据的变形是针对图片来做的,在ApplyDistort(const cv::Mat& in_img, const DistortionParameter& param)函数中,输入一个Mat格式的图片,输出一个经过DistortionParameter参数所变换后的图像,其中包括随机亮度失真变换,随机对比度失真变换,做随机饱和度失真变换,随机色调失真变换和随机图像通道变换,这里是一种排列组合的方法,变换的顺序不同,得到的图片结果也不同,根据随机数是否大于0.5来确定对比度和色调失真变换的顺序。代码如下:

返回变换后的图片,再将其编码成Datum的格式,编码函数EncodeCVMatToDatum(const cv::Mat& cv_img, const string& encoding, Datum* datum),其中用到了一个opencv图像编码的接口cv::imencode("."+encoding, cv_img, buf);再把数据写入datum中。代码如下:

接着是ExpandImage(distort_datum, expand_datum)的操作,这个操作是按照百分之五十的概率发生的。ExpandImage可以理解为裁剪操作,在SSD中作者也提到裁剪相当与zoom in放大效果,可以使网络对尺度更加不敏感,因此可以识别小的物体。通过将原图缩小放到一个画布上再去裁剪达到缩小的效果。在原文中的Fig.6提到了在数据增强之后SSD网络确实对小物体识别能力有很大提升。裁剪后的图像至少一个 groundtruth box 的中心(centroid) 位于该图像块中.这样就可以避免不包含明显的前景目标的图像块不用于网络训练(只有包含明显的前景目标的图像块采用于网络训练.)同时,保证只有部分前景目标可见的图片用于网络训练.例如,下面图像中,Groundtruth box 表示为红色,裁剪的图像块表示为绿色. 由于是随机裁剪(概率百分之五十),因此有些图像是包含扩展的画布,有些则不包含.


在代码中实现ExpandImage的方法是,先按(1:max_expand_ratio)随机产生一个比例系数expand_ratio,创造一个expand_ratio*原图大小的0填充图,再按照代码里的方式确定一个顶点,用于将原图粘贴到所创造的“画布”中,并且确定好需要这张图需要裁剪的区域expand_bbox(这个区域我不太懂),然后用平均值进行画布填充,得到一张较大的图,用于后期的裁剪,这样做的原因,上文提到了(参考别人说的)

接着就是把填充的图片编码成expand_datum,然后进入TransformAnnotation函数,在上面的ExpandImage中,不存在任何对原数据中的AnnotationGroup的处理,即这里所生成的expand_datum仅仅是图片的裁剪的datum格式,expand_datum中的Annotation并没有做任何赋值或者更新,这一部分工作在TransformAnnotation函数中进行,主要是将原图的AnnotationGroup中的NormalizedBBox,通过映射变换后,复制到expand_datum的annotation中,注意这里所取的原图NormalizedBBox有条件,得满足这个框的中心点在裁剪图之中,其他在裁剪框之外的NormalizedBBox就直接舍弃。代码如下:

这里就解读到ExpandImage函数,下一篇将解读Samples这块儿的操作。