目标检测系列(七):SSD
References
- https://blog.csdn.net/qianqing13579/article/details/82106664
- https://blog.csdn.net/zhangjunp3/article/details/80597312
- https://blog.csdn.net/ikerpeng/article/details/54316814
《SSD: Single Shot MultiBox Detector》
STAR
S: YOLO将目标检测问题变为回归问题来做, 整张图划分为77的网格, 每一个格子预测两个目标,直接输出置信度+坐标位置,并没有使用region proposal,而且77的划分很粗糙,对效目标不好。
T: 如何提高预测的精度?
A: YOLO+多尺度+proposal+FCN: 整张图88网格 + anchors + FCN, 不同层的feature map 33 滑窗感受野不同,作为不同尺度的检测。
R: MAP73.9%, 58FPS。
1. 多尺度

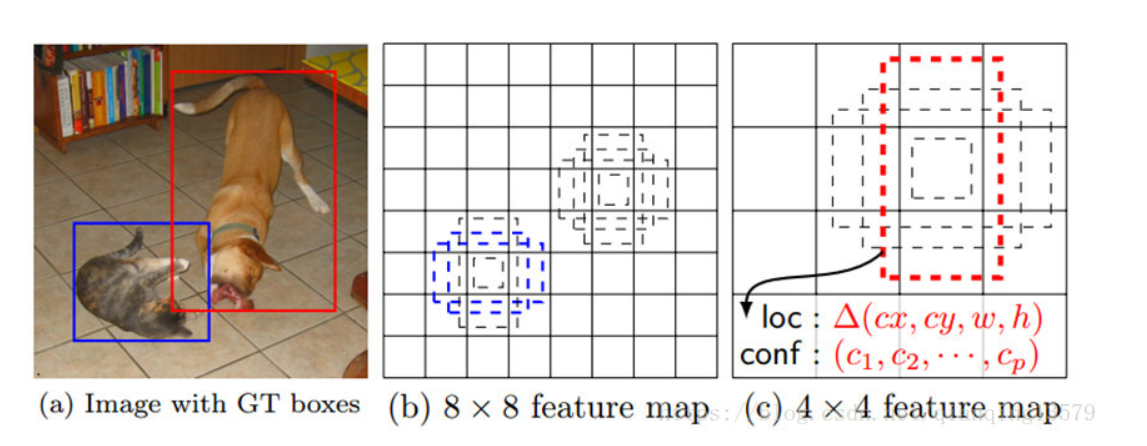
由SSD的网络结构可以看出,SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标。

作者在论文中通过实验验证了,采用多个特征图做检测能够大大提高检测精度,从上面的表格可以看出,采用6个特征图检测的时候,mAP为74.3%,如果只采用conv7做检测,mAP只有62.4%。
2. FCN: 卷积检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。注意全卷积神经网络与非全卷积神经网络的区别,一般的分类网络比如AlexNet只需要对整幅图像提取特征然后做分类,感受野是整幅图像,所以最后会用全连接层,而SSD中,由于要对每一个感受野做分类,所以只能用卷积层。
3. anchor:设置了多种宽高比的default box
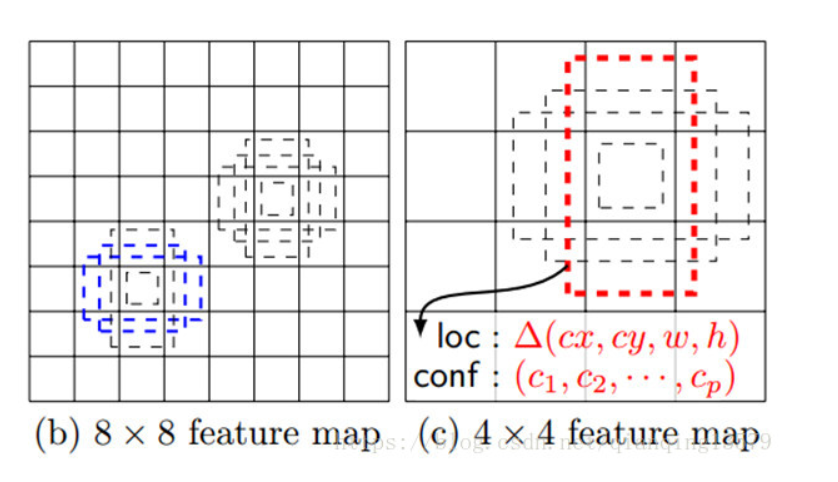
在特征图的每个像素点处,生成不同宽高比的default box(anchor box),论文中设置的宽高比为{1,2,3,1/2,1/3}。假设每个像素点有k个default box,需要对每个default box进行分类和回归,其中用于分类的卷积核个数为c*k(c表示类别数),回归的卷积核个数为4*k。
SSD300中default box的数量:(38384 + 19196 + 10106 + 556 + 334 + 114)= 8732
答疑解惑:
1. 为什么要设置default box?
每个特征图上每个像素点对应一个理论感受野, 每一层的default box设置了每一层特征图的有效感受野,然后使用这些default box与ground truth进行匹配来确定特征图上每个像素点的实际的有效感受野的label(包含分类label和回归label),分别用于分类和boundingbox回归。说的简单点,default box就是用来确定特征图上每个像素点实际的有效感受野的label的。
SSD对6个特征图上所有的default box进行分类和回归,其实就是对6个特征图对应的实际的有效感受野进行分类和回归,说得更加通俗一点,这些有效感受野其实就是原图中的滑动窗口,所以SSD本质上就是对所有滑动窗口进行分类和回归。这些滑动窗口图像其实就是SSD实际的训练样本。知道SSD的原理后我们发现深度学习的目标检测方法本质与传统的目标检测方法是相同的,都是对滑动窗口的分类。
然后通过default box 与 ground truth 进行对比,来确定label.
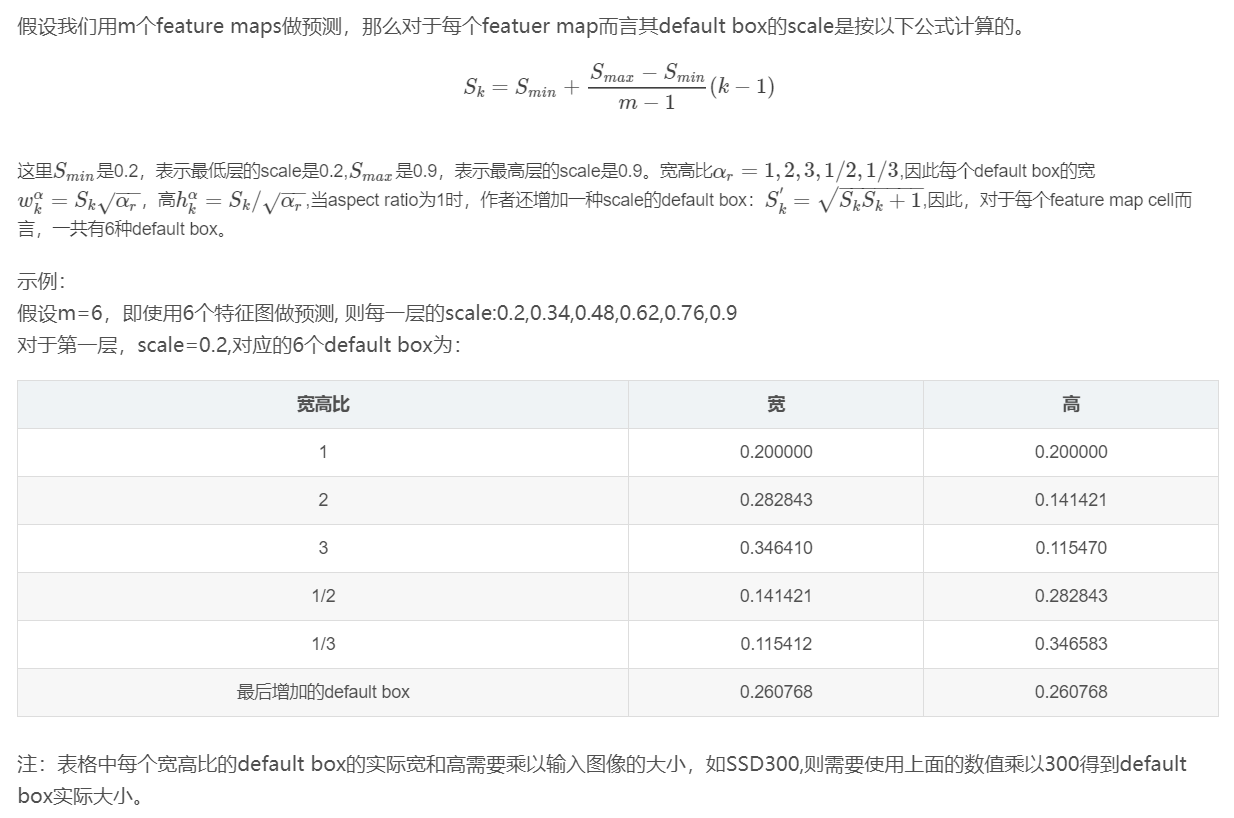
2. 为什么要设置多种宽高比的default box?
我们知道default box其实就是SSD的实际训练样本,如果只设置了宽高比为1的default box,最多只有1个default box匹配到,如果设置更多宽高比的default box,将会有更多的default box匹配到,也就相当于有更多的训练样本参与训练,模型训练效果越好,检测精度越高。

作者实验结果表明,增加宽高比为1/2,2,1/3,3的default box,mAP从71.6%提高到了74.3%。
但是怎么选择default box的scale和aspect ratio?(我感觉这就类似于anchor 的机制,其实到底要怎么设置,要取多少个:大小比例如何设置,还没有很好的方法)
4. 数据增强
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如下图所示:

作者实验表明,增加了数据增强后,mAP从65.5提高到了74.3!
5. SSD的问题
- SSD对小目标的检测效果一般,作者认为小目标在高层没有足够的信息。
论文原文: This is not surprising because those small objects may not even have any information at the very top layers. Increasing the input size (e.g. from 300× 300 to 512× 512) can help improve detecting small objects, but there is still a lot of room to improve.
- 对SSD的改进可以从下面几个方面考虑:
- 增大输入尺寸
- 使用更低的特征图做检测
- 设置default box的大小,让default box能够更好的匹配实际的有效感受野
如需转载请注明出处,谢谢!