版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/vivian_ll/article/details/88780661
RNN
RNNs的目的使用来处理序列数据。
在传统的神经网络模型中,假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
假如说基于传统的非循环NN采用滑框的形式来处理先后关系,可是因为是滑框大小是必须固定的,对于序列数据是可变长度情况下,还是没法解决。而且对于对话系统或者说自动驾驶等任务来说,也没法基于所谓的分类器和回归器去组合成一个新模型从而解决问题。所以还是需要一些能够显示的处理时序依赖关系的方法。
为什么不能用HMM呢?
因为HMM必须基于离散的适度数量的状态集合S中去状态转换,即使使用了viterbi算法,算法时间复杂度也是O(|S|2),所以一旦状态增多,那么HMM的复杂度就急速上升了,而且如果采用滑框形式来融合多个状态,一旦窗口变大,计算复杂度也指数上升了,所以HMM对于长时依赖问题也是很麻烦的。
所以RNN系列应运而生了。一方面基于非线性激活函数的固定size的RNN几乎可以拟合任意的数学计算,并且RNN是基于NN的,不但可以用SGD方式训练,而且还可以增加正则项等来缓解过拟合问题;另一方面,RNN的图灵完备特性使得其一旦结构定义了,就不太可能生成任何其他随意的模式(固定性)。
RNNs隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
RNN典型结构如下:
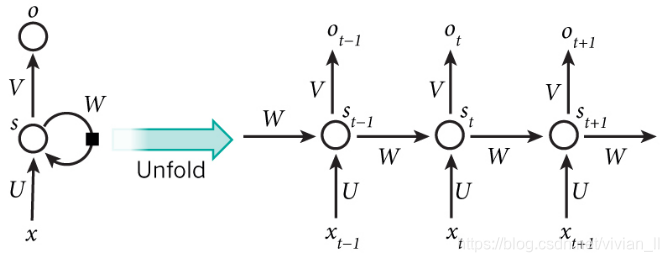
xt为time step为t时的输入,如可以为对应句子某个单词的one-hot向量。
st为time step为t时的隐藏层状态,即网络的“记忆”:
St=f(U∗Xt+W∗St−1)
,其中f常为tanh或ReLU。
ot为t步的输出,若我们想预测句子的下一个单词,它可以为词汇表中的概率向量。
ot=softmax(Vst)
沿时间轴将RNN展开:
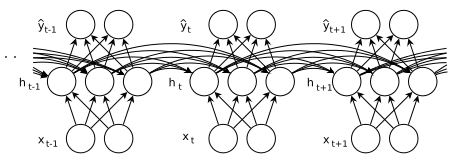
RNNs在NLP中的应用有:
语言模型与文本生成(Language Modeling and Generating Text),机器翻译(Machine Translation),语音识别(Speech Recognition),图像描述生成 (Generating Image Descriptions)。
RNN的训练
由于RNN在所有的时间步中共享参数(U,V,W),因此每个输出的梯度不仅取决于当前时间步长的计算,而且还取决于以前的时间步长。 例如,为了计算t=4处的梯度,我们需要反向传播3个步骤并对梯度求和(链式法则),这叫做时间反向传播(BPTT)。
由于RNN模型如果需要实现长期记忆的话需要将当前的隐含态的计算与前n次的计算挂钩(具体推导见下文),那样的话计算量会呈指数式增长,导致模型训练的时间大幅增加,因此RNN模型一般不直接用来进行长期记忆计算。
使用BPTT训练的普通RNNs由于消失/爆炸梯度问题而难以学习长期依赖关系(例如,步骤之间相距很远的依赖关系)。
RNN的梯度消失和梯度爆炸
RNN的损失函数可以为交叉熵:
Et(yt,y^t)=−ytlogy^tE(y,y^)=t∑Et(yt,y^t)=−t∑ytlogy^t
其中
yt为真实标签,
y^t为预测标签。
为了计算误差对U、V、W的梯度,和误差相加类似,对每一个时间步长的梯度相加,
∂W∂E=t∑∂W∂Et。
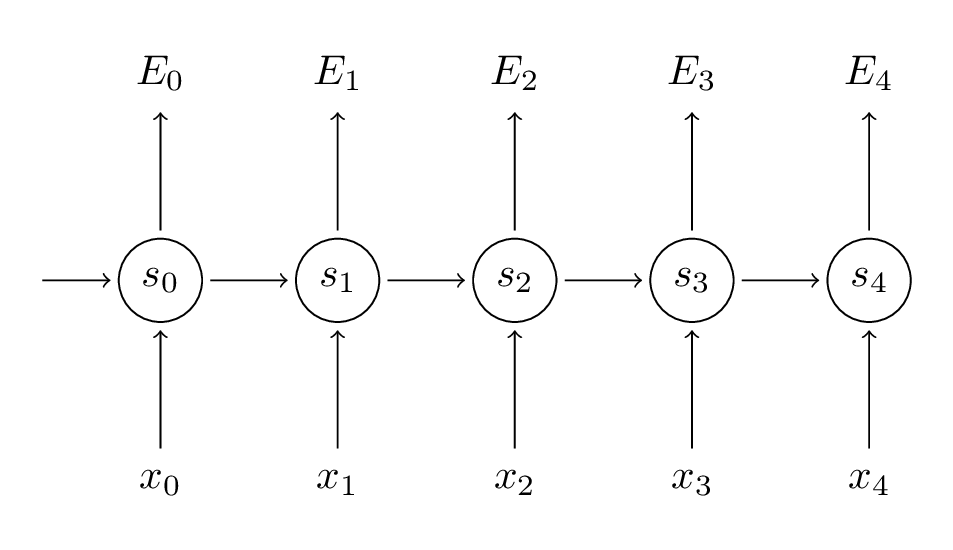
如图所示,以
E3为例计算梯度:
∂V∂E3=∂y^3∂E3∂V∂y^3=∂y^3∂E3∂z3∂y^3∂V∂z3=(y^3−y3)⊗s3
其中
z3=Vs3,
⊗是两个向量的外积。
所以
∂V∂E3只取决于当前time step的值:
y^3,y3,s3。
但对于
∂W∂E3:
∂W∂E3=∂y^3∂E3∂s3∂y^3∂W∂s3
其中
s3=tanh(Uxt+Ws2)取决于
s2,而
s2取决于
W和
s1,所以此处求导不能简单地将看作
s2常数:
∂W∂E3=k=0∑3∂y^3∂E3∂s3∂y^3∂sk∂s3∂W∂sk
∂s1∂s3这里也有一个链式法则:
∂s1∂s3=∂s2∂s3∂s1∂s2,所以梯度传播如图:
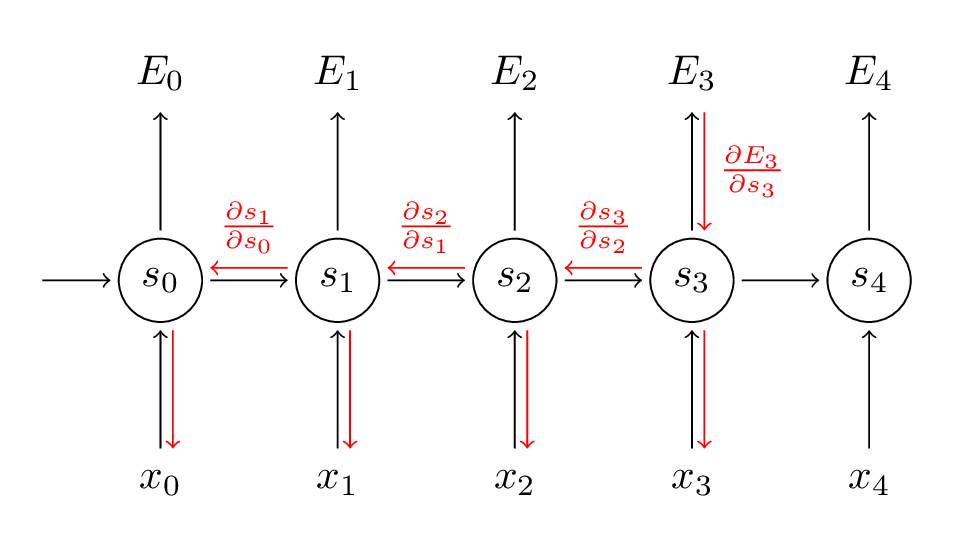
∂W∂E3=k=0∑3∂y^3∂E3∂s3∂y^3⎝⎛j=k+1∏3∂sj−1∂sj⎠⎞∂W∂sk
再加上激活函数
st=tanh(U∗xt+W∗st−1),则
j=k+1∏t∂sj−1∂sj=j=k+1∏ttanh′WS。
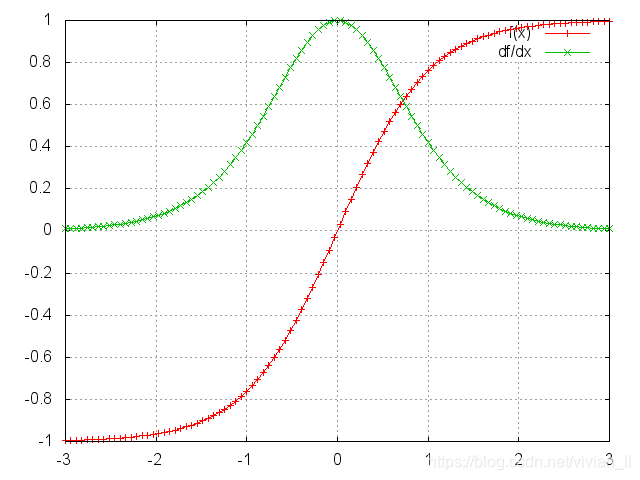
又因为tanh的倒数在[0,1]之间,大部分时间小于1,如果
Ws 也是一个大于0小于1的值,则当t很大时,使得
tanh′∗Ws<1,则连乘式就会趋近于0,即出现梯度消失。同理,当
Ws很大时,使得
tanh′∗Ws>1,则连乘式就会趋近于无穷,即出现梯度爆炸。
梯度消失和爆炸的根本原因在于
∏j=k+1t∂Sj−1∂Sj 这里。
要消除这种情况就需要把这一坨在求偏导的过程中去掉,至于怎么去掉,一种办法就是使
∂Sj−1∂Sj≈1 另一种办法就是使
∂Sj−1∂Sj≈0 。
为了解决这种问题,有三种方式:(1)合适地初始化W,即采用正则化;(2)将tanh或sigmoid替换为ReLU;(3)使用LSTM或者GRU。
总结:
梯度消失:RNN梯度消失是因为激活函数tanh函数的倒数在0到1之间,反向传播时更新前面时刻的参数时,当参数W初始化为小于1的数,则多个(tanh函数’ * W)相乘,将导致求得的偏导极小(小于1的数连乘),从而导致梯度消失。
梯度爆炸:当参数初始化为足够大,使得tanh函数的倒数乘以W大于1,则将导致偏导极大(大于1的数连乘),从而导致梯度爆炸。
参考网址:
Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
循环神经网络(RNN, Recurrent Neural Networks)介绍(上文的翻译+变体RNN)
Recurrent Neural Network[survey]
RNN梯度消失和爆炸
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
LSTM
LSTM的结构
首先是LSTM的cell的结构
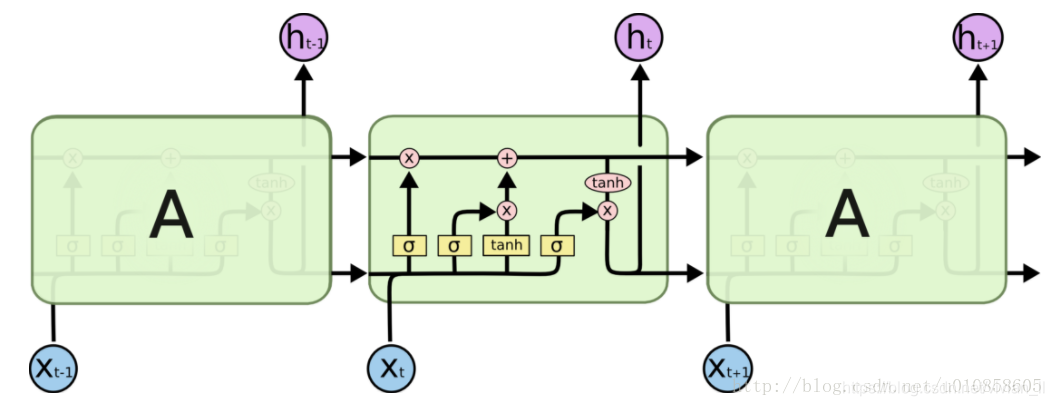
具体遗忘门、输入门、输出门的前向传播公式,见Understanding LSTM Networks
ft=σ(WfXt+bf)
it=σ(WiXt+bi)
oi=σ(WoXt+bo)
要点:
- 结构:
输入门 weight bias 决定更新信息 决定什么值更新
遗忘门 weight bias 确定丢弃信息
输出门 weight bias 输出信息
原始cell(rnn部分)weight bias 创建新的候选值到状态中
每个时刻weight同时变化、每个时刻weight相互影响
- 激活函数:
sigmoid:门控、确定哪部分输出
导数 :f(1-f)
映射到[0,1]
梯度消失 :当值接近0或1时,梯度接近0,反向传播计算每层残差接近0,梯度接近0,在参数微调中引起梯度弥散,前几层梯度靠近0,不再更新。
函数中心不为0
tanh:状态和输出,对数据处理,创建候选值向量
导数:1-f^2
函数中心0 【-1,1】
relu:解决梯度消失问题;计算速度快,收敛快,在前几层也能很快更新
- LSTM反向传播:
沿时间反向传播;从t时刻开始,计算每个误差项;误差向上一级传递
LSTM解决梯度消失问题
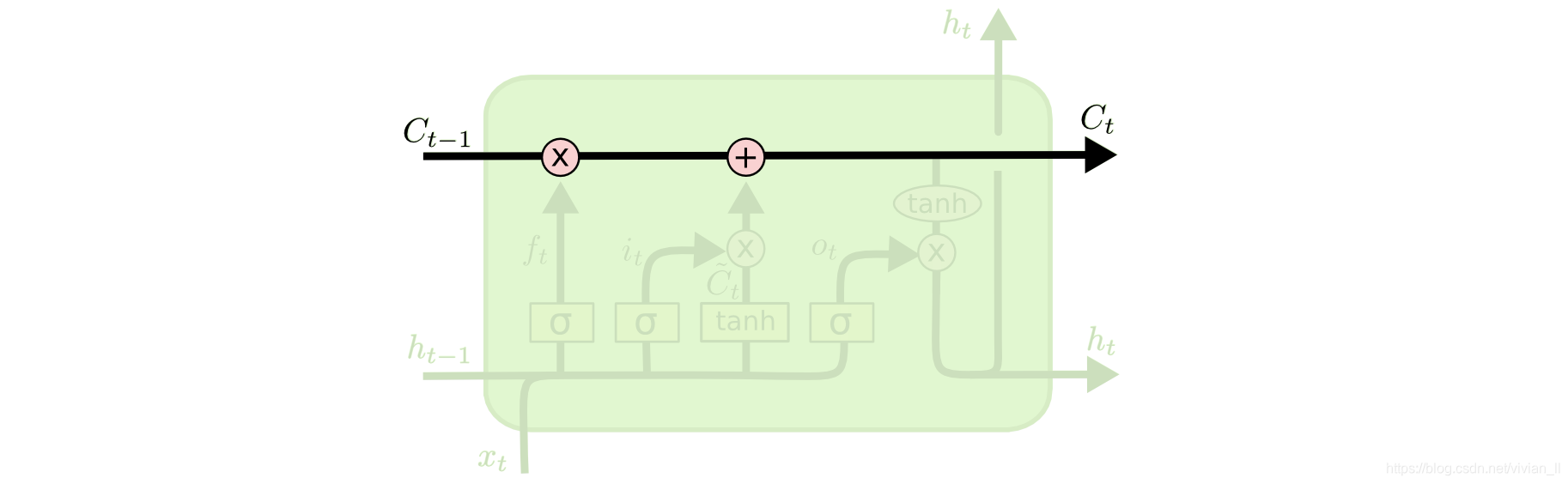
LSTM可以抽象成下图:
LSTM当前的状态
St=ftSt−1+itXt与传统RNN的当前状态
St=WsSt−1+WxXt+b1类似。
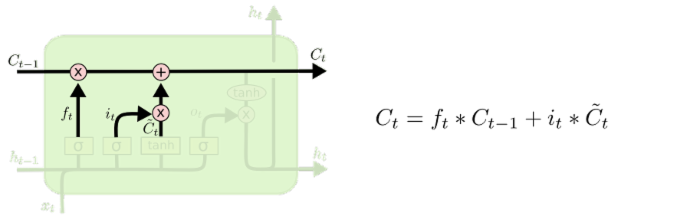
将LSTM的状态表达式展开并加上激活函数tanh后如下:
St=tanh[σ(WfXt+bf)St−1+σ(WiXt+bi)Xt]
对比传统RNN求偏导的过程:
j=k+1∏t∂Sj−1∂Sj=j=k+1∏ttanh′Ws
LSTM同样包含这一项,但形式为:
j=k+1∏t∂Sj−1∂Sj=j=k+1∏ttanh’σ(WfXt+bf)
假设
Z=tanh′(x)σ(y),则Z的函数图像如下图所示:
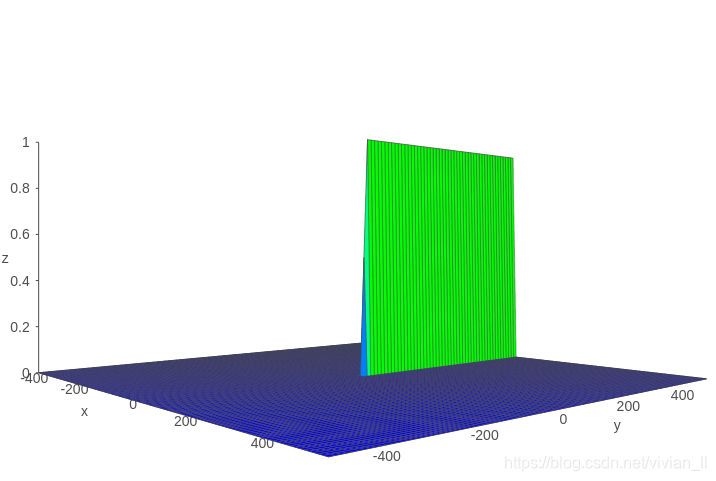
可以看到该函数值基本上不是0就是1,所以
∏j=k+1t∂Sj−1∂Sj=∏j=k+1ttanh’σ(WfXt+bf)≈0∣1,即解决了传统RNN中梯度消失的问题。
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
LSTM的变体
流形的 LSTM 变体
由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。即让门层 也会接受细胞状态的输入。
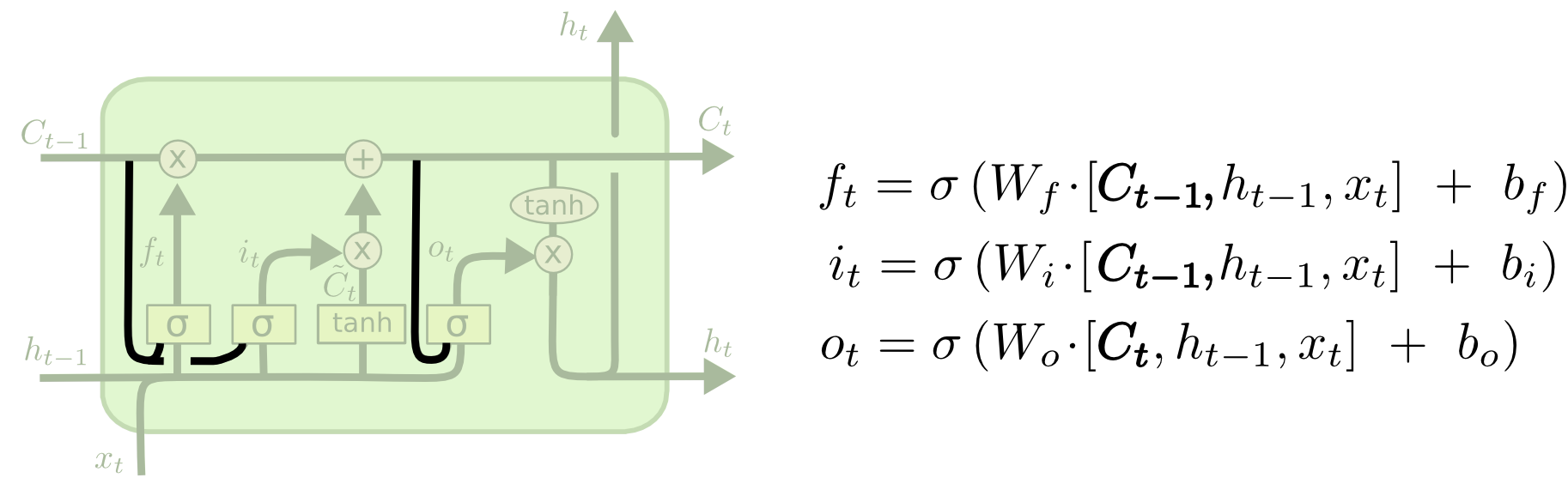
上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
GRU(Gated Recurrent Unit)
GRU由 Cho, et al. (2014) 提出。在 GRU 中,只有两个门:重置门(reset gate)和更新门(update gate)。同时在这个结构中,把细胞状态和隐藏状态进行了合并。最后模型比标准的 LSTM 结构要简单,而且这个结构后来也非常流行。

其中,
rt表示重置门,
zt表示更新门。重置门决定是否将之前的状态忘记。当
rt趋于 0 的时候,前一个时刻的状态信息
ht−1会被忘掉,隐藏状态
ht~会被重置为当前输入的信息。更新门决定是否要将隐藏状态更新为新的状态
ht~ (作用相当于合并了 LSTM 中的遗忘门和传入门)。
和 LSTM 比较一下:
(1) GRU 少一个门,同时少了细胞状态
Ct 。
(2) 在 LSTM 中,通过遗忘门和传入门控制信息的保留和传入;GRU 则通过重置门来控制是否要保留原来隐藏状态的信息,但是不再限制当前信息的传入。
(3) 在 LSTM 中,虽然得到了新的细胞状态
Ct,但是还不能直接输出,而是需要经过一个过滤的处理:
ht=ot∗tanh(Ct);同样,在 GRU 中, 虽然 (2) 中我们也得到了新的隐藏状态
ht~, 但是还不能直接输出,而是通过更新门来控制最后的输出:
ht=(1−zt)∗ht−1+zt∗ht~。
其他变体,如Yao, et al. (2015) 提出的 Depth Gated RNN。还有用一些完全不同的观点来解决长期依赖的问题,如 Koutnik, et al. (2014) 提出的 Clockwork RNN。(见循环神经网络(RNN, Recurrent Neural Networks)介绍)
参考网址:
LSTM如何解决梯度消失问题
Understanding LSTM Networks
[RNN介绍,较易懂]
(https://blog.csdn.net/prom1201/article/details/52221822)(上文的翻译)
(译)理解 LSTM 网络 (Understanding LSTM Networks by colah)(上文翻译+GRU)
LSTM在MNIST手写数据集上做分类(代码中尺寸变换细节)
https://blog.csdn.net/u010858605/article/details/78696325