传统的知识图谱表示方法是采用OWL、RDF等本体语言进行描述;随着深度学习的发展与应用,我们期望采用一种更为简单的方式表示,那就是【向量】,采用向量形式可以方便我们进行之后的各种工作,比如:推理,所以,我们现在的目标就是把每条简单的三元组< subject, relation, object > 编码为一个低维分布式向量。(有关【分布式表示】的概念请大家自行百度)
paper:Translating Embeddings for Modeling Multi-relational Data
这里介绍一个概念:
【表示学习】: 表示学习旨在将研究对象的语义信息表示为稠密低维实值向量,知识表示学习主要是面向知识图谱中的实体和关系进行表示学习。使用建模方法将实体和关系表示在低维稠密向量空间中,然后进行计算和推理。简单来说,就是将三元组表示成向量的这个过程就称为表示学习,而我们今天介绍的就是【Trans系列】中的一个经典方法【TransE模型】。
知识表示的几个代表模型:翻译模型、距离模型、单层神经网络模型、能量模型、双线性模型、张量神经网络模型、矩阵分解模型等
TransE模型属于翻译模型:直观上,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r 和 t(head、relation和tail的向量),使(h + r) 尽可能与 t 相等,即 h + r = t
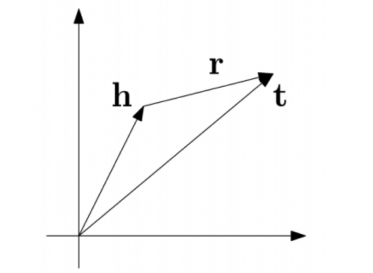
TransE 是基于实体和关系的分布式向量表示,由 Bordes 等人于2013年提出,受word2vec启发,利用了词向量的【平移不变现象】。
例如:C(king)−C(queen)≈C(man)−C(woman) 其中,C(w)就是word2vec学习到的词向量表示。
TransE 定义了一个距离函数 d(h + r, t),它用来衡量 h + r 和 t 之间的距离,在实际应用中可以使用 L1 或 L2 范数。在模型的训练过程中,transE采用最大间隔方法,最小化目标函数,目标函数如下:

其中,S是知识库中的三元组即训练集,S’是负采样的三元组,通过替换 h 或 t 所得,是人为随机生成的。γ 是取值大于0的间隔距离参数,是一个超参数,[x]+表示正值函数,即 x > 0时,[x]+ = x;当 x ≤ 0 时,[x]+ = 0 。算法模型比较简单,梯度更新只需计算距离 d(h+r, t) 和 d(h’+r, t’)。这个过程和训练小狗一样,它做对了,就给骨头吃;做错了,就打两下。
模型训练过程

- 首先,确定训练集,超参数γ,学习率λ
- 初始化关系向量与实体向量,对于每个向量的每个维度在 [ -6/√k,6/√k)内随机取一个值,k为低维向量的维数,对所有的向量初始化之后要进行归一化
- 进入循环:采用minibatch,一批一批的训练会加快训练速度,对于每批数据进行负采样(将训练集中的三元组某一实体随机替换掉),T_batch初始为一个空列表,然后向其添加由元组对(原三元组,打碎的三元组)组成的列表 :
T_batch = [ ( [h,r,t], [h',r,t'] ), ([ ], [ ]), ......]
- 拿到T_batch后进行训练,采用梯度下降进行调参
参考: