目录
1.什么是数据仓库?
1.1数据仓库概念
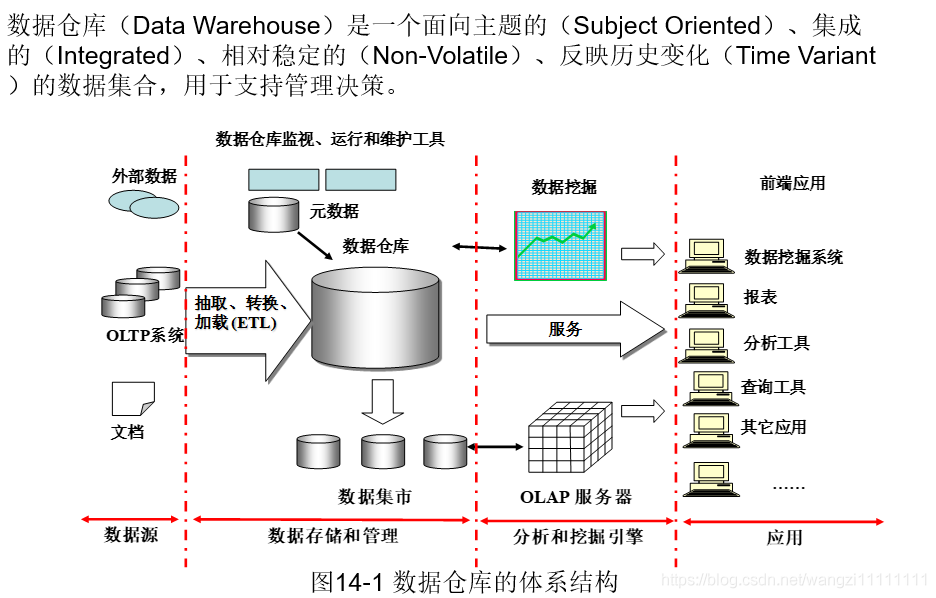
对历史数据变化的统计,从而支撑企业的决策。比如:某个商品最近一个月的销量,预判下个月应该销售多少,从而补充多少货源。
1.2传统数据仓库面临的挑战

1.3 Hive介绍


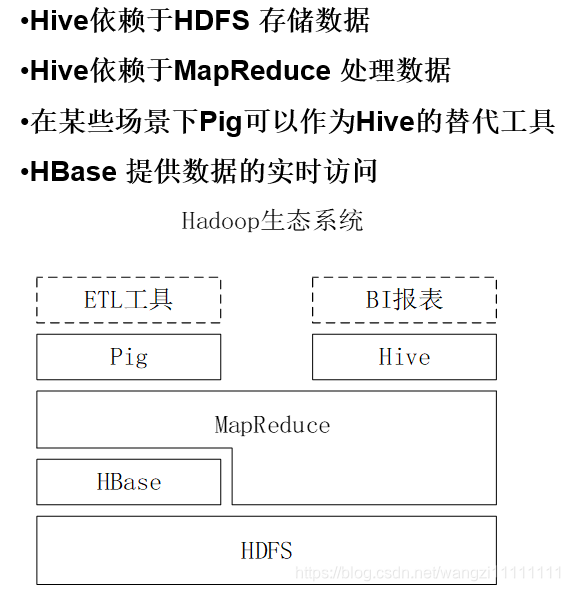
Hbase支持快速的交互式的大数据应用
pig,Hive支持批量式的数据分析业务
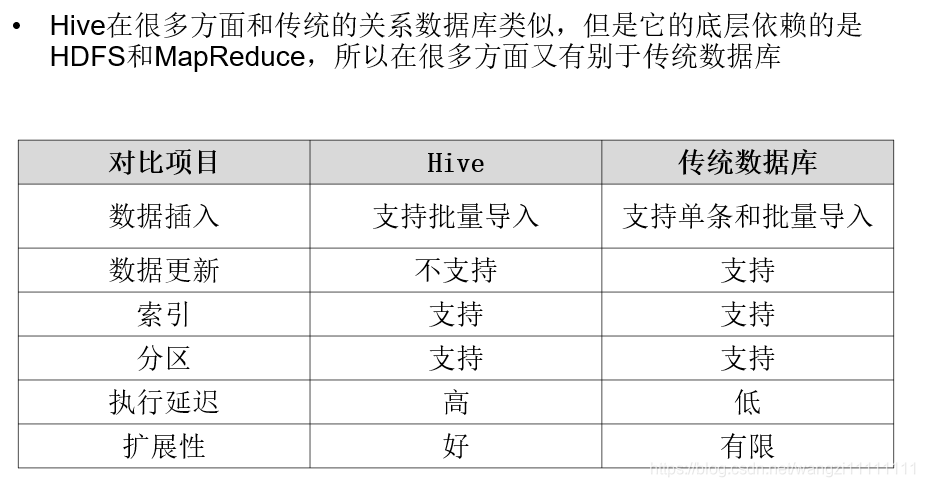
1.4 Hive与传统数据库的对比
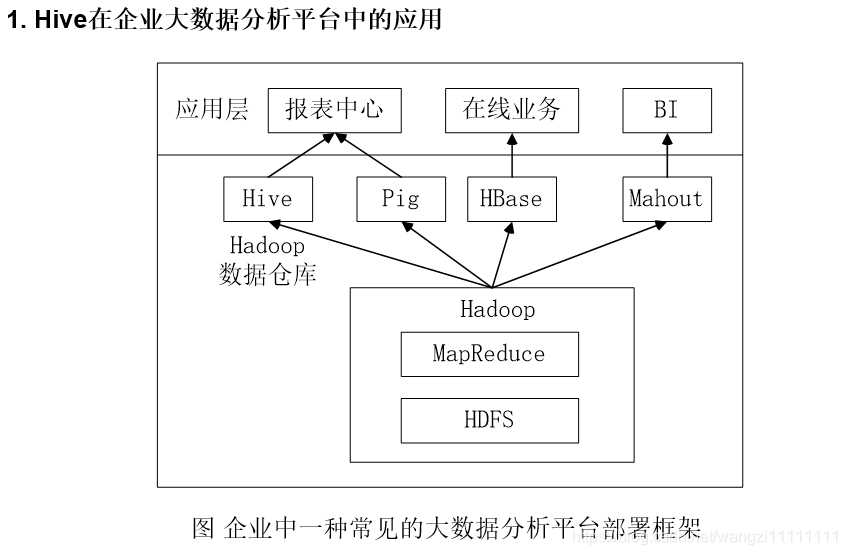
1.5 Hive在企业中的部署与应用
2.Hive系统架构
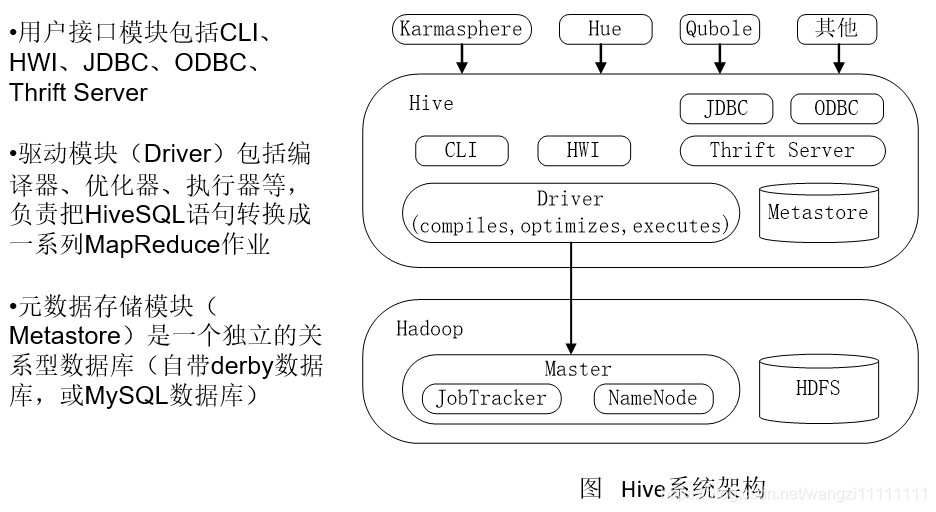
Microsoft推出的ODBC(Open Database Connectivity)技术 [1] 为异质数据库的访问提供了统一的接口
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
CIL (Common Intermediate Language) 公共中间语言
3.Hive工作原理
3.1 SQL转换为MapReduce作业的基本原理
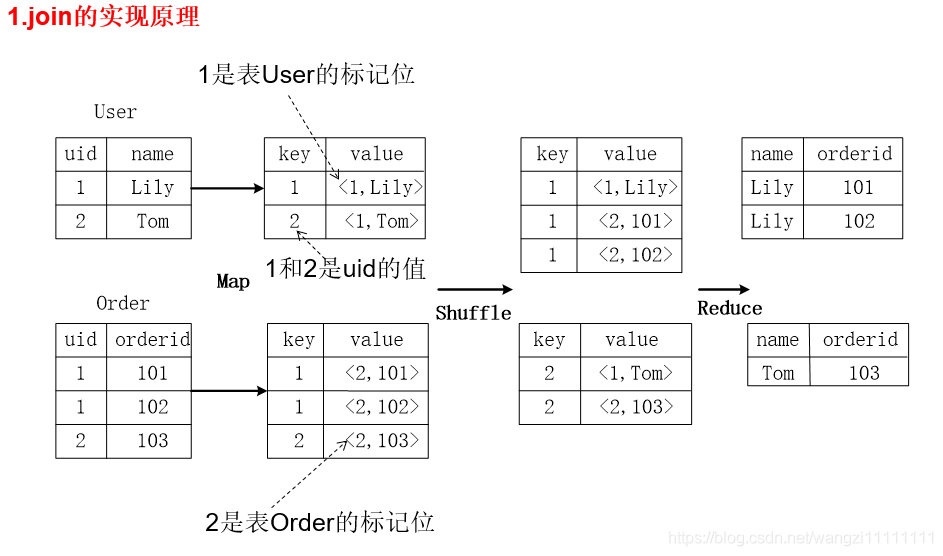
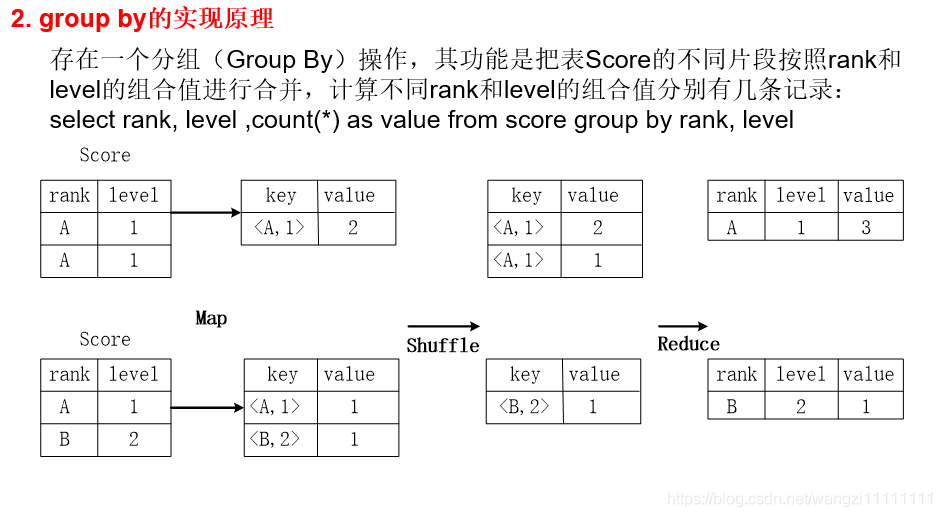
3.2 Hive中SQL查询转换MapReduce作业的过程

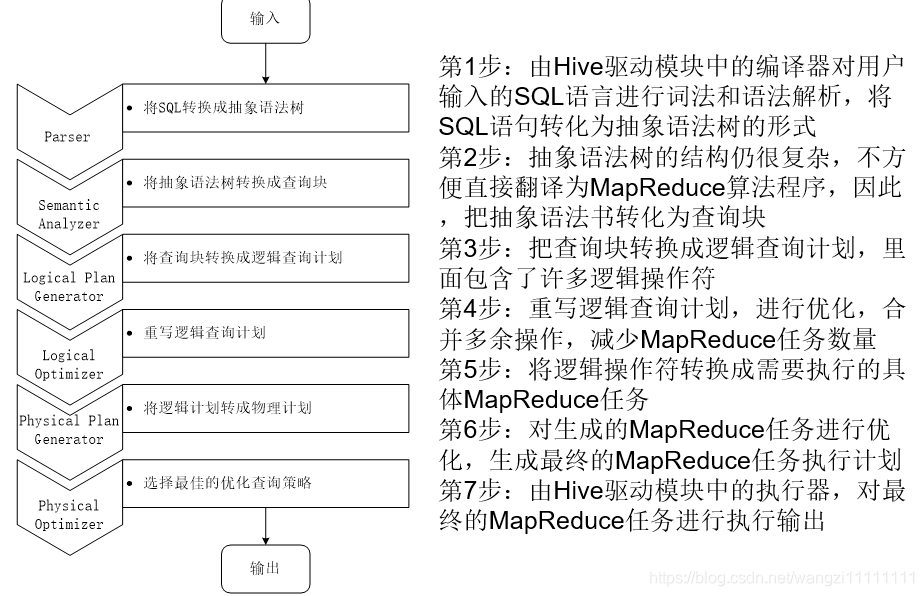

4.Hive HA基本原理
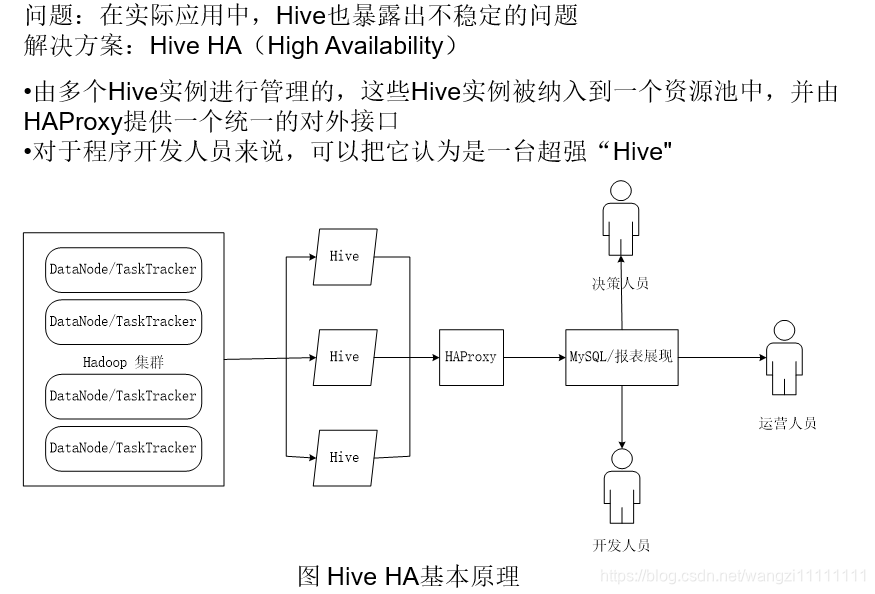
5.Impala
5.1 Impala介绍

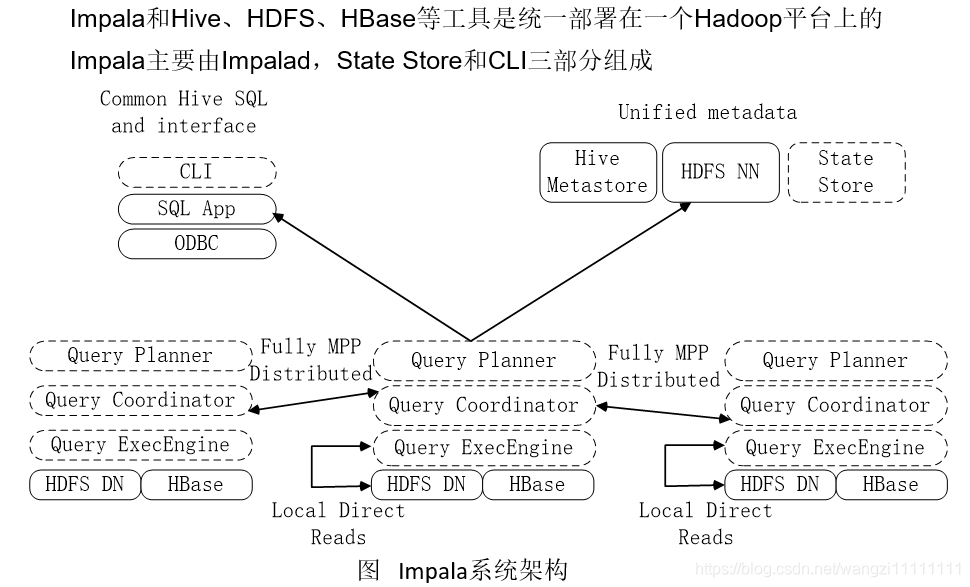
5.2 Impala系统架构

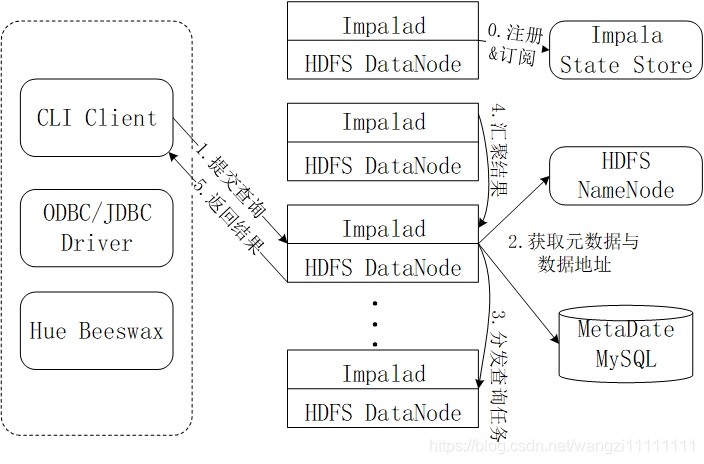
5.3 Impala查询执行过程


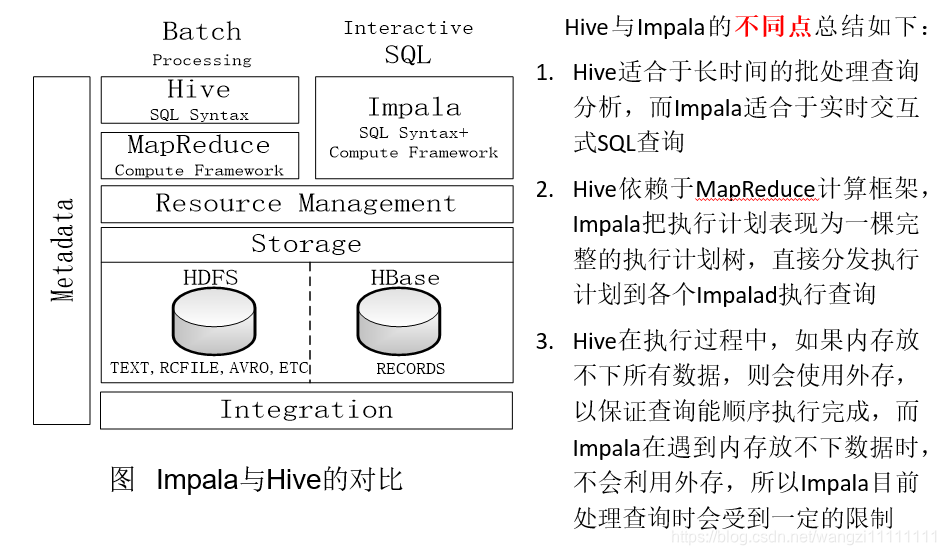
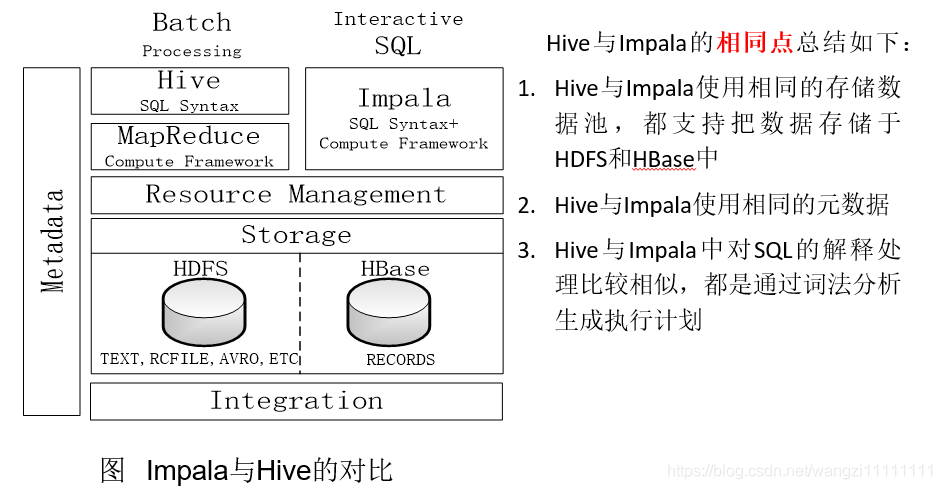
5.4 Impala和Hive的区别

6.Hive编程实践
6.1 Hive的安装和配置

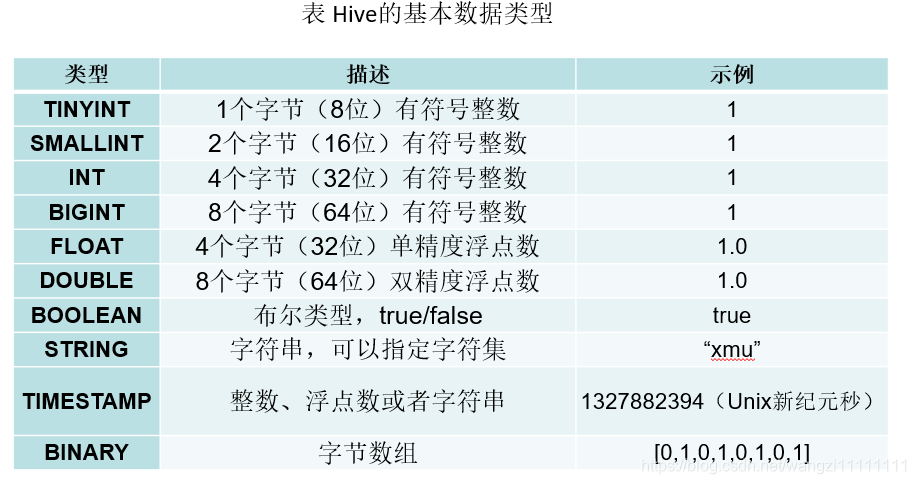
6.2 Hive的基本数据类型

6.3 Hive的基本操作






6.4 Hive的应用实例(wordCount)


6.5 Hive的优势

7.总结
