Hive --数据仓库
Overview
Apache Hive数据仓库软件有助于使用SQL读取,编写和管理驻留在分布式存储中的大型数据集。 可以将结构投影到已存储的数据中。 提供了命令行工具和JDBC驱动程序以将用户连接到Hive。
一、Hive环境搭建
1.安装一个mysql
Ubuntu 16.04下安装MySQL的过程:
首先执行下面三条命令:
sudo apt-get install mysql-server
sudo apt install mysql-client
sudo apt install libmysqlclient-dev
安装成功后可以通过下面的命令测试是否安装成功:
sudo netstat -tap | grep mysql
出现如下信息证明安装成功:

可以通过如下命令进入MySQL服务:
mysql -uroot -p你的密码
2.Hive环境配置
1)Hive下载:http://archive.cloudera.com/cdh5/cdh/5/
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
2)解压
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz
3)配置
系统环境变量(~/.bahs_profile)
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=
PATH
修改配置文件:$HIVE_HOME/conf/hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
4)拷贝mysql驱动到$HIVE_HOME/lib/
mysql 各个版本驱动jar包:http://central.maven.org/maven2/mysql/mysql-connector-java/
5)启动hive: $HIVE_HOME/bin/hive

二、Hive操作
1.创建表
CREATE TABLE table_name [(col_name data_type [COMMENT col_comment])]
create table hive_wordcount(context string);

2.加载数据到hive表
LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE tablename
load data local inpath ‘/home/hadoop/data/hello.txt’ into table hive_wordcount;
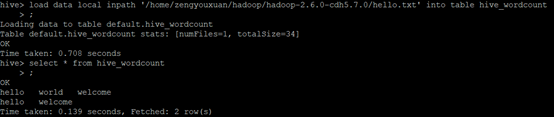
3.执行SQL
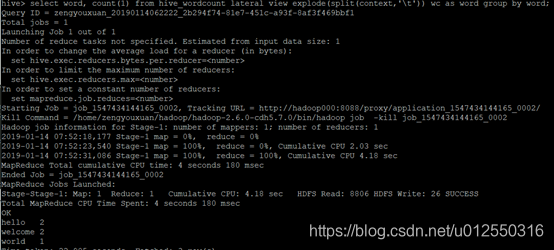
select word, count(1) from hive_wordcount lateral view explode(split(context,’\t’)) wc as word group by word;
#lateral view explode(): 是把每行记录按照指定分隔符进行拆解
#hive sql提交执行以后会生成mr作业,并在yarn上运行
三、案例操作
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
create table dept(
deptno int,
dname string,
location string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
load data local inpath ‘/home/hadoop/data/emp.txt’ into table emp;
load data local inpath ‘/home/hadoop/data/dept.txt’ into table dept;
求每个部门的人数
select deptno, count(1) from emp group by deptno;