第7讲 MapReduce
7.1 MapReduce概述
7.1.1 分布式并行编程
“摩尔定律”, CPU性能大约每隔18个月翻一番
•从2005年开始摩尔定律逐渐失效 ,需要处理的数据量快速增加,人们开始借助于分布式并行编程来提高程序性能

•分布式程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,从而获得海量的计算能力
•谷歌公司最先提出了分布式并行编程模型MapReduce,Hadoop MapReduce是它的开源实现,后者比前者使用门槛低很多
问题:在MapReduce出现之前,已经有像MPI这样非常成熟的并行计算框架了, 那么为什么Google还需要MapReduce?MapReduce相较于传统的并行计算框架有什么优势?


7.1.2 MapReduce模型简介
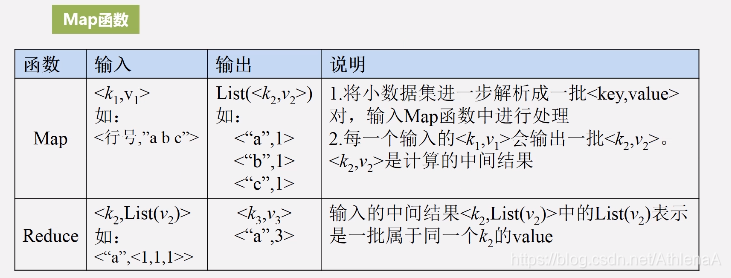
•MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
•编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算 •MapReduce采用**“分而治之”策略**,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
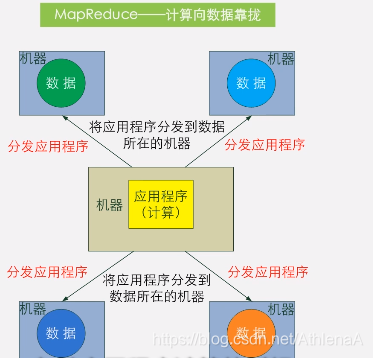
•MapReduce设计的一个理念就是**“计算向数据靠拢”,而不是“数据 向计算靠拢”,因为,移动数据需要大量的网络传输开销


•MapReduce框架采用了Master/Slave架构**,包括一个Master和若干个Slave。 Master上运行JobTracker,Slave上运行TaskTracker

•Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
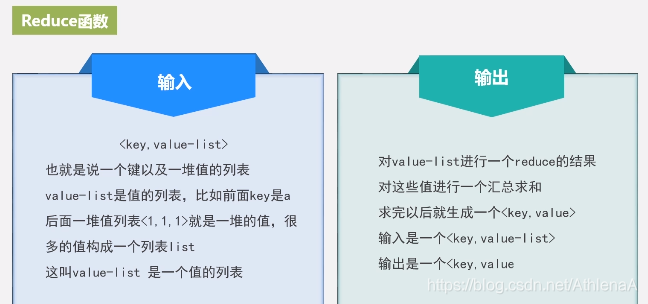
7.1.3 Map和Reduce函数
7.2 MapReduce的体系结构
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、 TaskTracker以及Task
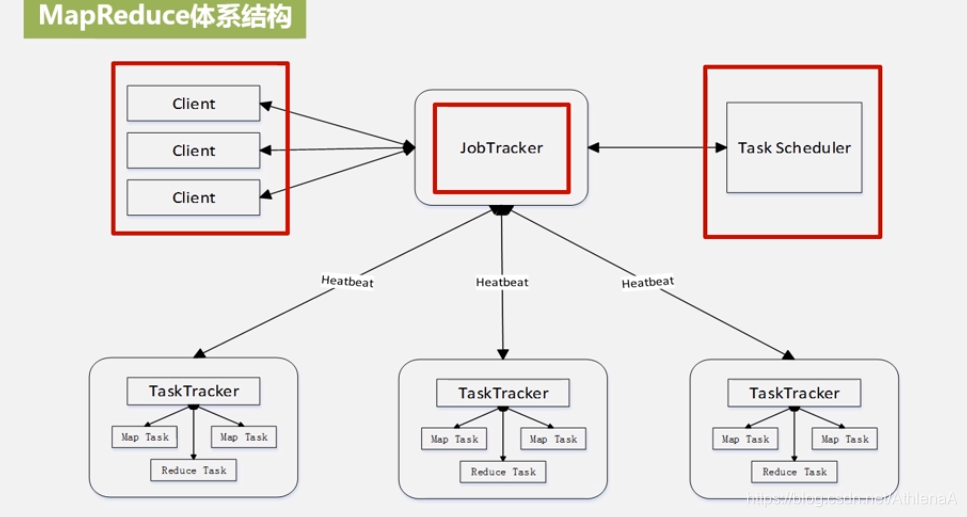
MapReduce主要有以下4个部分组成:
1)Client
•用户编写的MapReduce程序通过Client提交到JobTracker端
•用户可通过Client提供的一些接口查看作业运行状态
2)JobTracker
•JobTracker负责资源监控和作业调度
•JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
•JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器 (TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
3)TaskTracker
执行具体的相关任务,一般接收JobTracker 发来的命令
•TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报 给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、 杀死任务等)
•TaskTracker 使用**“slot”等量**划分本节点上的资源量(CPU、内存等)。一个Task 获取到 一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分 配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用

两个slot不通用
4)Task Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动 Client
7.3 MapReduce工作流程
7.3.1 工作流程概述

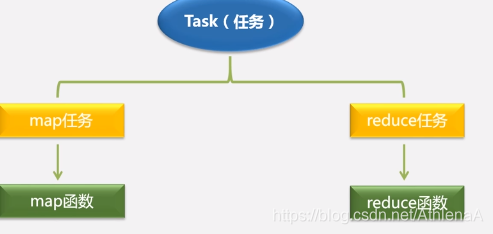
对大的数据集进行分片操作

•不同的Map任务之间不会进行通信 (map任务的输入是keyvalue,输出也是keyvalue)
•不同的Reduce任务之间也不会发生任何信息交换
•用户不能显式地从一台机器向另一台机器发送消息
•所有的数据交换都是通过MapReduce框架自身去实现的
输入输出都是HDFS
7.3.2 MapReduce各个执行阶段
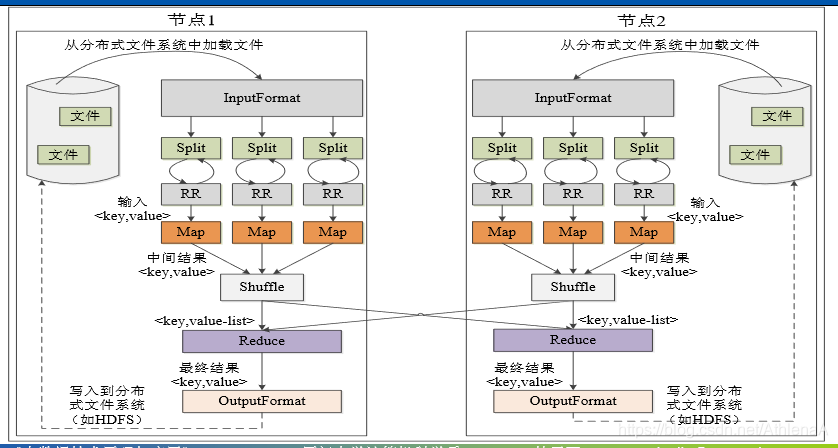
首先要从分布式文件系统HDFS中加载文件 ,加载读取是由InputFormat模块来完成的,要负责对输入进行格式验证,要把一个大的输入文件分成片。只是逻辑上的切分,由记录阅读器去具体根据分片的位置长度信息去底层的HDFS中找到各个块 ,把相关的分片给读出来,输出keyvalue的形式。因为mapreduce中map函数只接受keyvalue形式的数据。然后进行处理,形成中间结果,经过分区、排序、合并、归并,然后才能分发给对应的reduce去处理,然后才进行输出。
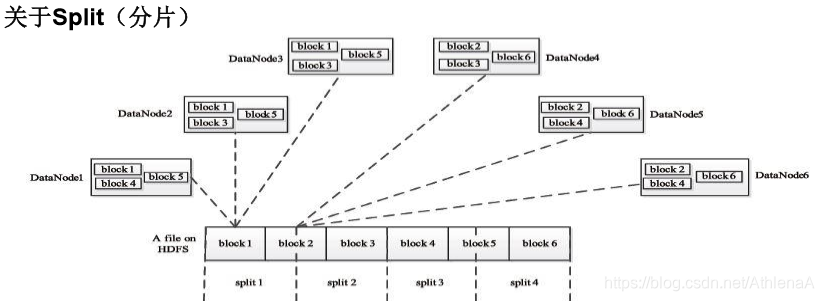
HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其 处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
分片和块是不同的概念。
Map任务的数量
•Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的 数目。大多数情况下,理想的分片大小是一个HDFS块 分片和map的数量是一样的。一般来说,用一个块的大小作为一个分片大小,64M。
Reduce任务的数量
•最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
•通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可 以预留一些系统资源处理可能发生的错误)

7.4 Shuffle过程原理
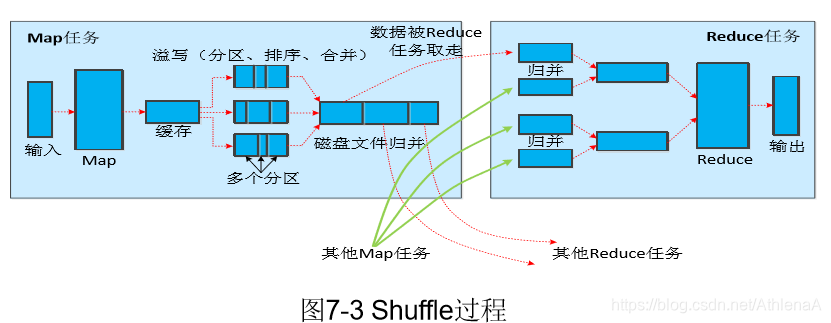
只放大画出了一个map任务和一个reduce任务
2. Map端的Shuffle过程
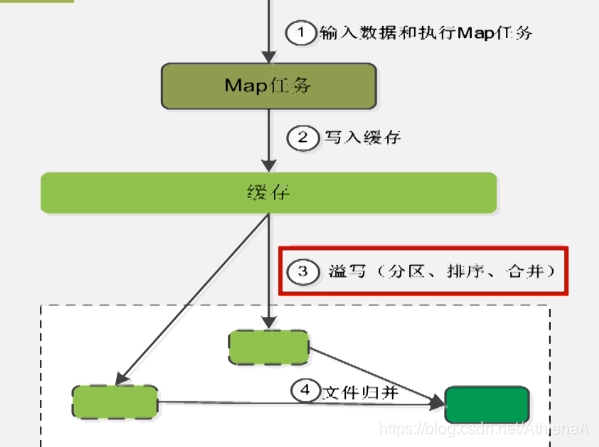
1输入数据和执行Map任务
2写入缓存
3 溢写(分区、排序、合并)
4 文件归并
•每个Map任务分配一个缓存
•MapReduce默认100MB缓存
•设置溢写比例0.8 (不能等满了才去溢写)
•分区默认采用哈希函数 (4个reduce要分四个区)
•排序是默认的操作 (不需要用户干预)
•排序后可以合并(Combine)
•合并不能改变最终结果
•在Map任务全部结束之前进行归并
•归并得到一个大的文件,放在本地磁盘
•文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner,少于3不需要
•JobTracker会一直监测Map任务的执行,并通知 Reduce任务来领取数据
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
- Reduce端的Shuffle过程
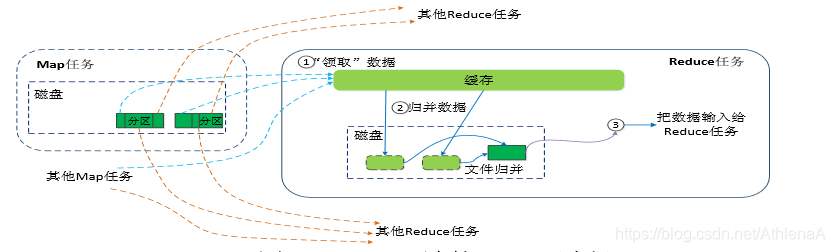
•Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据
•Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
•多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
•当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
7.5 MapReduce应用程序执行过程
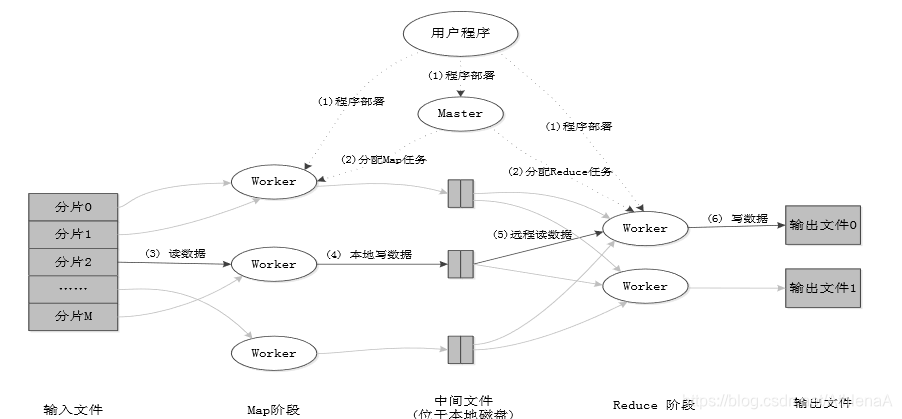
分为6个步骤
首先用户写完MapReduce应用程序以后,第一步要进行程序的部署,把程序分布到不同的机器上,要从整个集群当中选出相关的机器,有些机器作为Master,Master只有一个,然后其他机器作为Worker,Master机器作为一个管家的角色,上面运行JobTracker,Worker可以执行map任务也可以执行reduce任务,当然要在一堆Worker当中,选出一部分Worker去执行map任务,选出另外一部分Worker做reduce任务。所以要把执行的用户逻辑分发到这些机器上去,这是第一步,完成程序的部署。
第二步,集群中已经有这么多的worker,加下来就要选出一部分的worker,把它作为执行map任务的机器,另外一部分的worker把它作为执行reduce任务的机器,然后对于执行map任务的机器,因要要执行map任务,所以要给它输入数据,输入数据一般都是一个非常大的文件,所以要对文件进行拆分。要对一个大的数据集进行分片,分成多个片段,然后需要从集群中执行map任务的机器里面选出几个空闲的机器,让它去执行数据分片的处理。
接下来进入第三个过程,从分布式文件系统各个分片中把数据读入,读入以后生成相关的(key,value)键值对,然后提交给map任务去执行,map里面包含了用户编写的应用程序处理逻辑,然后会输出一堆的相关的(key,value),输出结果不是直接写入磁盘,也不是直接发送给reduce任务,而是先写到缓存,这样就完成了第三步。
第四步是把缓存当中的数据写到磁盘,一旦写满以后,就要写到磁盘,要把缓存当中的数据经过分区排序或者可能 发生的合并操作,再把它写到磁盘当中去,写到磁盘以后就生成一个大的文件,这个文件当中包含的是很多个分区的数据,然后这个分区中的数据都是排序的合并以后的数据,这些数据要发送给远端的reduce任务去处理。
第五步远程读数据,负责执行相关reduce任务的机器,会从各个相关的map任务机器,把属于自己处理的数据都拉回去,拉回到本地进行相关的处理,处理完以后执行用户自定义的reduce函数,完成数据处理,处理结果就是一堆的键值对。
第六步,把相关的结果写到输出文件当中去 ,这个输出文件会写入分布式文件系统HDFS。
分为5个阶段;
HDFS-输入文件、map阶段、中间文件、reduce阶段、输出文件-HDFS
中间的过程是不写入HDFS的,而是写到磁盘
7.6 实例分析:WordCount
7.6.1 WordCount程序任务


只有能够满足分而治之的任务才能采用mapreduce去做。有依赖的就不能这么做。
7.6.2 WordCount设计思路
• 首先,需要检查WordCount程序任务是否可以采用MapReduce来实现
• 其次,确定MapReduce程序的设计思路
• 最后,确定MapReduce程序的执行过程
7.6.3 一个WordCount执行过程的实例
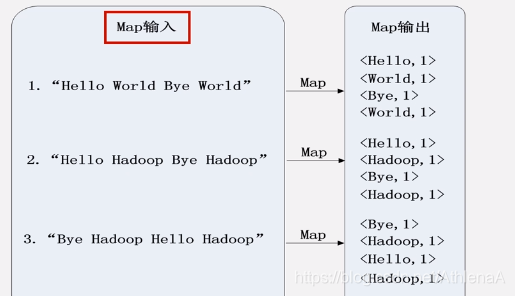
Map过程示意图
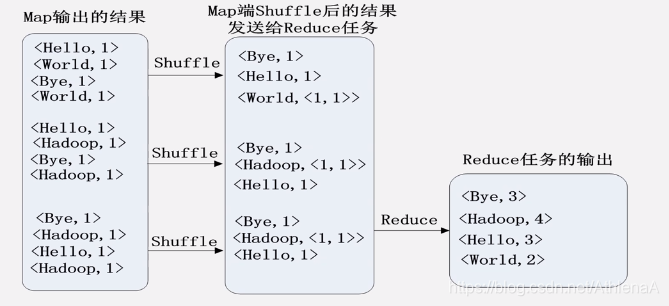
用户没有定义Combiner时的Reduce过程示意图
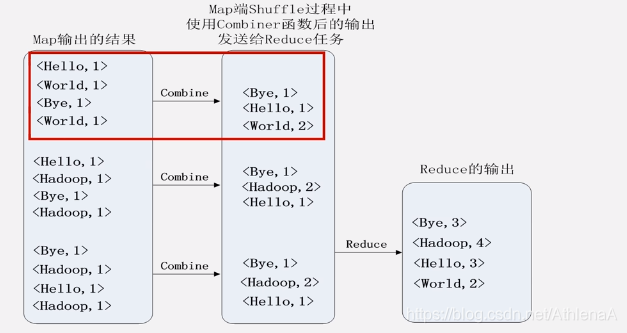
用户有定义Combiner时的Reduce过程示意图
7.7 MapReduce的具体应用
MapReduce可以很好地应用于各种计算问题
• 关系代数运算(选择、投影、并、交、差、连接)
• 分组与聚合运算
• 矩阵-向量乘法
• 矩阵乘法
用MapReduce实现关系的自然连接
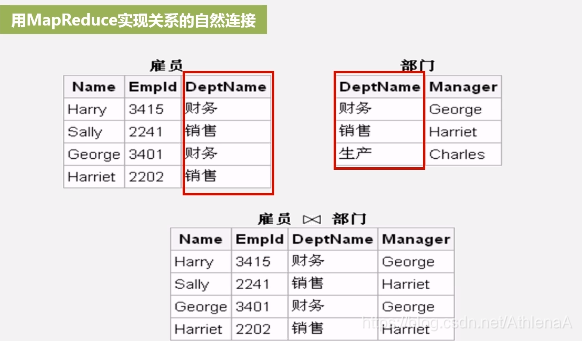
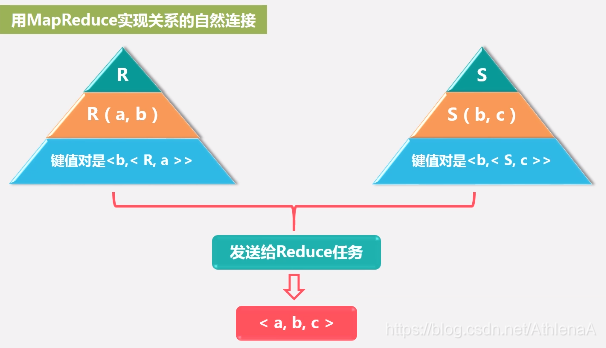
• 假设有关系R(A,B)和S(B,C),对二者进行自然连接操作
• 使用Map过程,把来自R的每个元组<a,b>转换成一个键值对<b, <R,a>>,其中的键就是属性B的值。把关系R包含到值中,这样做使得我们可以在 Reduce阶段,只把那些来自R的元组和来自S的元组进行匹配。类似地,使用Map过程,把来自S的每个元组<b,c>,转换成一个键值对<b,<S,c>>
• 所有具有相同B值的元组被发送到同一个Reduce进程中,Reduce进程的任务是,把来自关系R和S的、具有相同属性B值的元组进行合并
• Reduce进程的输出则是连接后的元组<a,b,c>,输出被写到一个单独的输出文件中
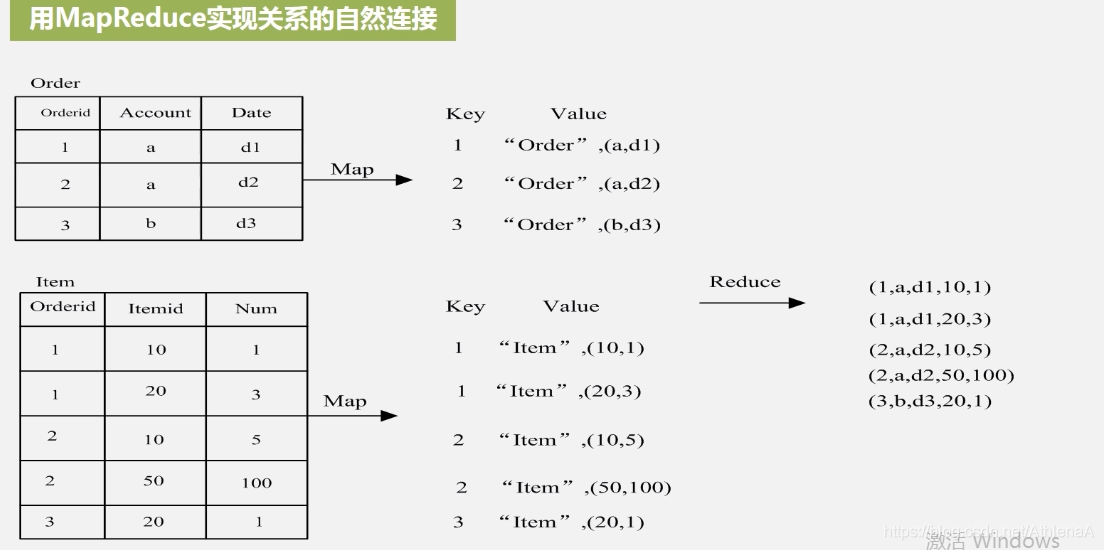
第一个元组来自order表、第二个元组来自item表,才能进行连接
7.8 MapReduce编程实践
7.6.1 任务要求

7.6.2 编写Map处理逻辑
•Map输入类型为<key,value>
•期望的Map输出类型为<单词,出现次数>
•Map输入类型最终确定为<Object,Text>
•Map输出类型最终确定为<Text,IntWritable>
public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString()); //切分
while (itr.hasMoreTokens()) { //一个个把单词分解出来
word.set(itr.nextToken());
context.write(word,one); //输出键值对
}
}
}
7.6.3 编写Reduce处理逻辑
•在Reduce处理数据之前,Map的结果首先通过Shuffle阶段进行整理
•Reduce阶段的任务:对输入数字序列进行求和
•Reduce的输入数据为<key,Iterable容器>
Reduce任务的输入数据: <”I”,<1,1>> <”is”,1> …… <”from”,1> <”China”,<1,1,1>>
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException,InterruptedException{ int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
7.6.4 编写main方法
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration(); //程序运行时参数
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf,“word count”); //设置环境参数
job.setJarByClass(WordCount.class); //设置整个程序的类名
job.setMapperClass(MyMapper.class); //添加MyMapper类
job.setReducerClass(MyReducer.class); //添加MyReducer类
job.setOutputKeyClass(Text.class); //设置输出类型
job.setOutputValueClass(IntWritable.class); //设置输出类型
FileInputFormat.addInputPath(job,new Path(otherArgs[0])); //设置输入文件 FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); //设置输出文件 System.exit(job.waitForCompletion(true)?0:1);
}
完整代码 :
import java.io.IOException; import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount{ //WordCount类的具体代码见下一页 }
public class WordCount{
public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{ StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word,one); } } }
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException,InterruptedException{ int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2); }
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1); } }
7.6.5 编译打包代码以及运行程序
实验步骤:
•使用java编译程序,生成.class文件
•将.class文件打包为jar包
•运行jar包(需要启动Hadoop)
•查看结果
Hadoop 2.x 版本中的依赖 jar Hadoop 2.x 版本中 jar 不再集中在一个 hadoop-core*.jar 中,而是 分成多个 jar,如使用 Hadoop 2.6.0 运行 WordCount 实例至少需要 如下三个 jar:
•
HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceclient-core-2.6.0.jar •$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
通过命令 hadoop classpath 可以得到运行 Hadoop 程序所需的全部 classpath信息
将 Hadoop 的 classpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=
HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
执行 source ~/.bashrc 使变量生效,接着就可以通过 javac 命令编译 WordCount.java

接着把 .class 文件打包成 jar,才能在 Hadoop 中运行:

运行程序:


7.6.6 Hadoop中执行MapReduce任务的几种方式
•Hadoop jar
•Pig
•Hive
•Python
•Shell脚本
在解决问题的过程中,开发效率、执行效率都是要考虑的因素,不要太局限于某一种方法
总结:
• 本章介绍了MapReduce编程模型的相关知识。MapReduce将复杂的 、运行于大规模集群上的并行计算过程高度地抽象到了两个函数: Map和Reduce,并极大地方便了分布式编程工作,编程人员在不会 分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式 系统上,完成海量数据集的计算
• MapReduce执行的全过程包括以下几个主要阶段:从分布式文件系 统读入数据、执行Map任务输出中间结果、通过 Shuffle阶段把中间 结果分区排序整理后发送给Reduce任务、执行Reduce任务得到最终 结果并写入分布式文件系统。在这几个阶段中,Shuffle阶段非常关键 ,必须深刻理解这个阶段的详细执行过程
• MapReduce具有广泛的应用,比如关系代数运算、分组与聚合运算 、矩阵-向量乘法、矩阵乘法等
• 本章最后以一个单词统计程序为实例,详细演示了如何编写 MapReduce程序代码以及如何运行程序
第8讲 数据仓库Hive
8.1 数据仓库概念
8.1.1 数据仓库概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant )的数据集合,用于支持管理决策。
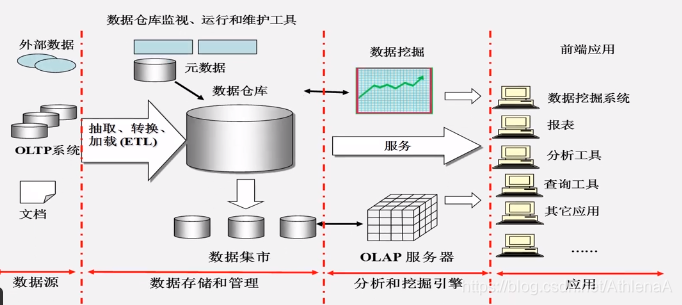

8.1.2 传统数据仓库面临的挑战
• (1)无法满足快速增长的海量数据存储需求
• (2)无法有效处理不同类型的数据
• (3)计算和处理能力不足
8.1.3 Hive简介
•Hive是一个构建于Hadoop顶层的数据仓库工具
•支持大规模数据存储、分析,具有良好的可扩展性
•某种程度上可以看作是用户编程接口,本身不存储和处理数据

•依赖分布式文件系统HDFS存储数据
•依赖分布式并行计算模型MapReduce处理数据
•定义了简单的类似SQL 的查询语言——HiveQL
•用户可以通过编写的HiveQL语句运行MapReduce任务
•可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop 平台上
•是一个可以提供有效、合理、直观组织和使用数据的分析工具
Hive具有的特点非常适用于数据仓库
1采用批处理方式处理海量数据
•Hive需要把HiveQL语句转换成MapReduce任务进行运行
•数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
2提供适合数据仓库操作的工具
•Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的 工具,可以存储、查询和分析存储在Hadoop中的大规模数据
•这些工具能够很好地满足数据仓库各种应用场景
8.1.4 Hive与Hadoop生态系统中其他组件的关系
•Hive依赖于HDFS 存储数据
•Hive依赖于MapReduce 处理数据
•在某些场景下Pig可以作为Hive的替代工具
•HBase 提供数据的实时访问
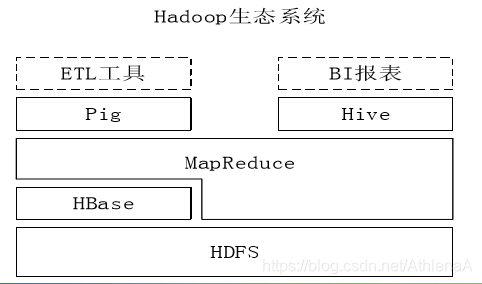

Hase是交互实时性的
8.1.5 Hive与传统数据库的对比分析
• Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是 HDFS和MapReduce,所以在很多方面又有别于传统数据库

8.1.6 Hive在企业中的部署和应用
- Hive在企业大数据分析平台中的应用
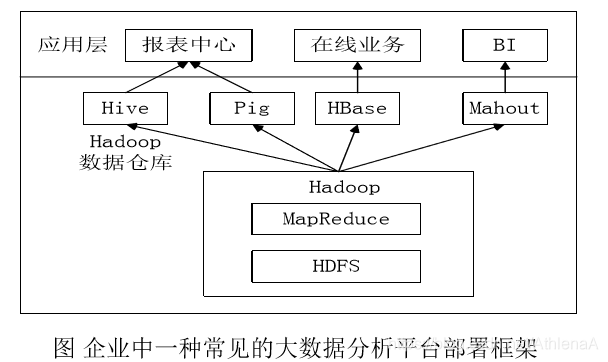
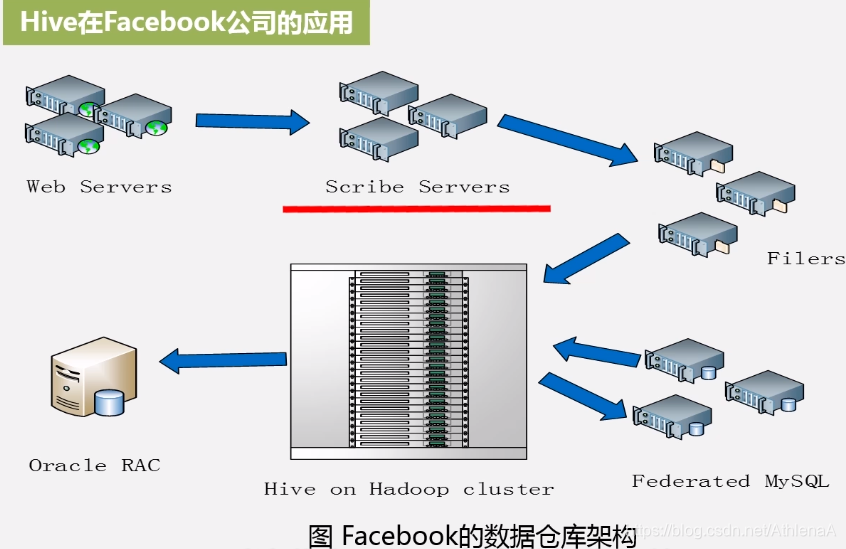
2.Hive在Facebook公司中的应用
•基于Oracle的数据仓库系统已经无法满足激增的业务需求
•Facebook公司开发了数据仓库工具Hive,并在企业内部进行了大量部署
8.2 Hive简介
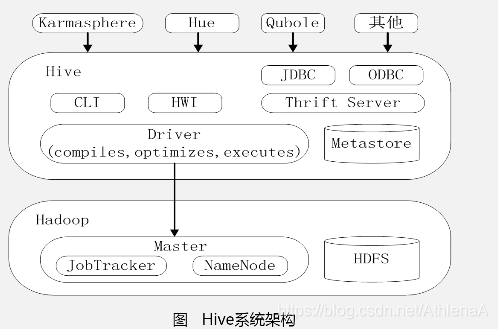
•用户接口模块包括CLI、 HWI、JDBC、ODBC、 Thrift Server

•驱动模块(Driver)包括编 译器、优化器、执行器等, 负责把HiveSQL语句转换成 一系列MapReduce作业
•元数据存储模块( Metastore)是一个独立的关 系型数据库(自带derby数据库,或MySQL数据库)


8.3 SQL转换成MapReduce作业的原理
8.3.1 SQL语句转换成MapReduce作业的基本原理

在第七章举过类似实例
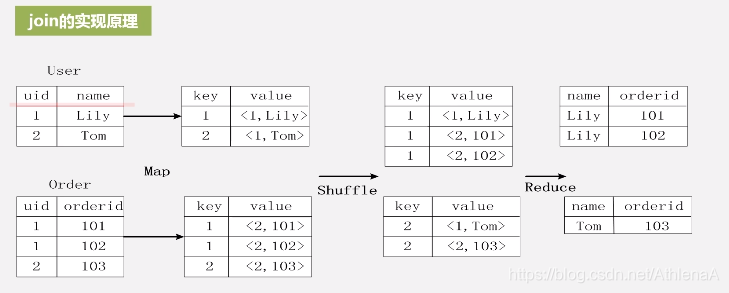

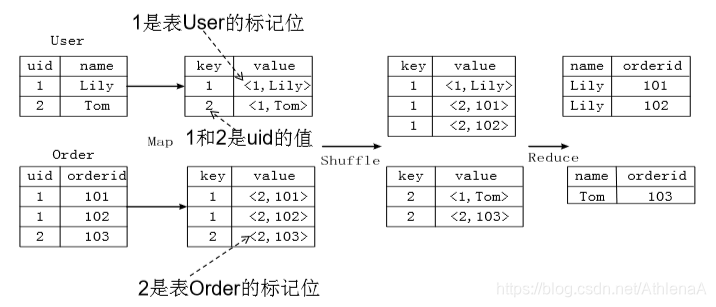
要想进行reduce操作,必须保证它们的key相等,还要保证生成的标记为中第一个是来自user表,第二个来自order表。
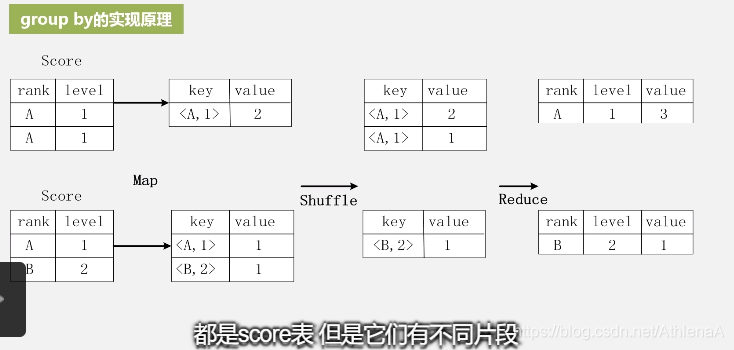
要进行分组操作,要按照rank和level的组合值进行合并,比如要计算不同的rank和level的组合值
分别有几条记录
存在一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和 level的组合值进行合并,计算不同rank和level的组合值分别有几条记录:
select rank, level ,count(*) as value from score group by rank, level
value是值这种组合有几条记录
key相同进行合并
8.3.2 Hive中SQL查询转换成MapReduce作业的过程
当用户向Hive输入一段命令或查询时,Hive需要与Hadoop交互工作来 完成该操作:
•驱动模块接收该命令或查询编译器
•对该命令或查询进行解析编译
•由优化器对该命令或查询进行优化计算
•该命令或查询通过执行器进行执行
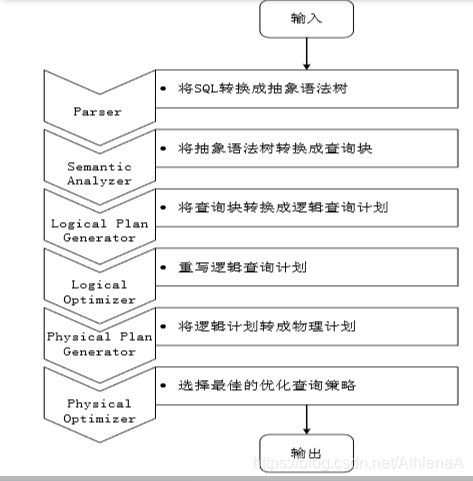
第1步:由Hive驱动模块中的编译器对用户输入 的SQL语言进行词法和语法解析,将SQL语句转化为抽象语法树的形式
第2步:抽象语法树的结构仍很复杂,不方便直接翻译为MapReduce算法程序,因此,把抽象 语法书转化为查询块
第3步:把查询块转换成逻辑查询计划,里面包 含了许多逻辑操作符
第4步:重写逻辑查询计划,进行优化,合并多 余操作,减少MapReduce任务数量
第5步:将逻辑操作符转换成需要执行的具体 MapReduce任务
第6步:对生成的MapReduce任务进行优化,生 成最终的MapReduce任务执行计划
第7步:由Hive驱动模块中的执行器,对最终的 MapReduce任务进行执行输出
几点说明:
• 当启动MapReduce程序时,Hive本身是不会生成MapReduce算法程序的
• 需要通过一个表示**“Job执行计划”的XML文件**驱动执行内置的、原生 的Mapper和Reducer模块
• Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在 JobTracker所在的管理节点上执行
• 通常在大型集群上,会有专门的网关机来部署Hive工具。网关机的作用 主要是远程操作和管理节点上的JobTracker通信来执行任务
• 数据文件通常存储在HDFS上,HDFS由名称节点管理
8.4 Impala
8.5.1 Impala简介

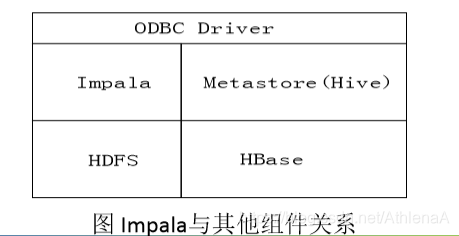
• Impala是由Cloudera公司开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop 的HDFS和HBase上的 PB级大数据,在性能上比Hive高出3~30倍
• Impala的运行需要依赖于Hive的元数据
• Impala是参照 Dremel系统进行设计的
• Impala采用了与商用并行关系数据库类似的分布式查询引擎,可以直接与HDFS和HBase 进行交互查询
不需要用转化为mapreduce任务,hive转化为mapreduce任务不好
• Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口
8.5.2 Impala系统架构
Impala和Hive、HDFS、HBase等工具是统一部署在一个Hadoop平台上的 Impala主要由Impalad,State Store和CLI三部分组成

Impala主要由Impalad,State Store和CLI三部分组成
1.Impalad
• 负责协调客户端提交的查询的执行
• 包含Query Planner、Query Coordinator和Query Exec Engine三个模块
• 与HDFS的数据节点(HDFS DN)运行在同一节点上
• 给其他Impalad分配任务以及收集其他Impalad的执行结果进行汇总
• Impalad也会执行其他Impalad给其分配的任务,主要就是对本地HDFS和HBase里的部分数据进 行操作 •
2.State Store
• 会创建一个statestored进程
• 负责收集分布在集群中各个Impalad进程的资源信息,用于查询调度
3.CLI
• 给用户提供查询使用的命令行工具
• 还提供了Hue、JDBC及ODBC的使用接口
说明:Impala中的元数据直接存储在Hive中。Impala采用与Hive相同的元数据、SQL语法、ODBC驱动 程序和用户接口,从而使得在一个Hadoop平台上,可以统一部署Hive和Impala等分析工具,同时支持批 处理和实时查询
8.5.3 Impala查询执行过程
Impala执行查询的具体过程:
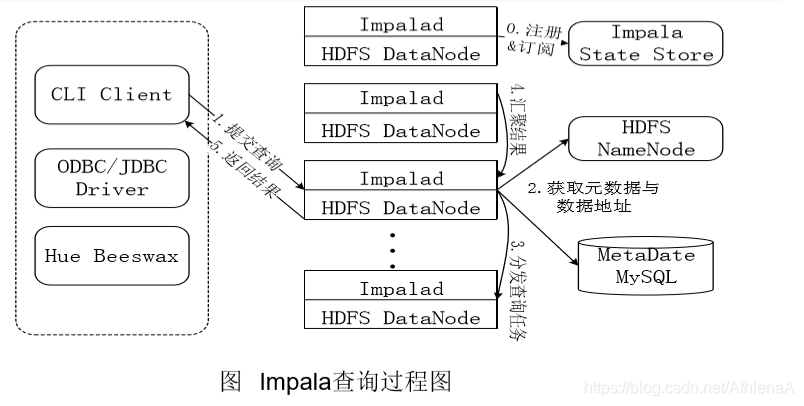
• 第0步,当用户提交查询前,Impala先创建一个负责协调客户端提交的查 询的Impalad进程,该进程会向Impala State Store提交注册订阅信息, State Store会创建一个statestored进程,statestored进程通过创建多个 线程来处理Impalad的注册订阅信息。
• 第1步,用户通过CLI客户端提交一个查询到impalad进程,Impalad的 Query Planner对SQL语句进行解析,生成解析树;然后,Planner把这个查 询的解析树变成若干PlanFragment,发送到Query Coordinator
• 第2步,Coordinator通过从MySQL元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点。
• 第3步,Coordinator初始化相应impalad上的任务执行,即把查询任务分配给所有存储这个查询相关数据的数据节点。
• 第4步,Query Executor通过流式交换中间输出,并由Query Coordinator 汇聚来自各个impalad的结果。
• 第5步,Coordinator把汇总后的结果返回给CLI客户端。
8.5.4 Impala与Hive的比较
Hive与Impala的不同点总结如下:
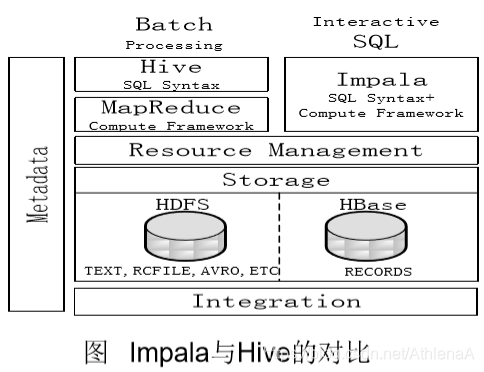
1.Hive适合于长时间的批处理查询分析,而 Impala适合于实时交互式SQL查询
2.Hive依赖于MapReduce计算框架(批处理延迟高),Impala 把执行计划表现为一棵完整的执行计划树, 直接分发执行计划到各个Impalad执行查 询
3.Hive在执行过程中,如果内存放不下所有 数据,则会使用外存,以保证查询能顺序 执行完成,而Impala在遇到内存放不下数据时,不会利用外存,所以Impala目前处理查询时会受到一定的限制
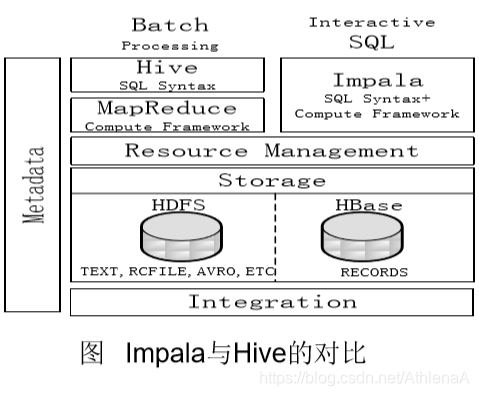
Hive与Impala的相同点总结如下:
1.Hive与Impala使用相同的存储数 据池,都支持把数据存储于 HDFS和HBase中
2.Hive与Impala使用相同的元数据
3.Hive与Impala中对SQL的解释处 理比较相似,都是通过词法分析 生成执行计划
总结
•Impala的目的不在于替换现有的MapReduce工具
•把Hive与Impala配合使用效果最佳
•可以先使用Hive进行数据转换处理,之后再使用Impala在 Hive处理后的结果数据集上进行快速的数据分析
8.5 Hive编程实践
Hive上机实践详细过程,请参考厦门大学数据库实验室建设的 “中国高校大数据课程公共服务平台”中的 “大数据课程学生服务站”中的“学习指南”栏目: 学生服务站地址:http://dblab.xmu.edu.cn/post/4331/
8.6.1 Hive的安装与配置
1.Hive安装
安装Hive之前需要安装jdk1.6以上版本以及启动Hadoop
•下载安装包apache-hive-1.2.1-bin.tar.gz 下载地址:http://www.apache.org/dyn/closer.cgi/hive/
•解压安装包apache-hive-1.2.1-bin.tar.gz至路径 /usr/local
•配置系统环境,将hive下的bin目录添加到系统的path中
2.Hive配置 Hive有三种运行模式,单机模式、伪分布式模式、分布式模式。 均是通过修改hive-site.xml文件实现,如果 hive-site.xml文件不存在,我们 可以参考$HIVE_HOME/conf目录下的hive-default.xml.template文件新建。
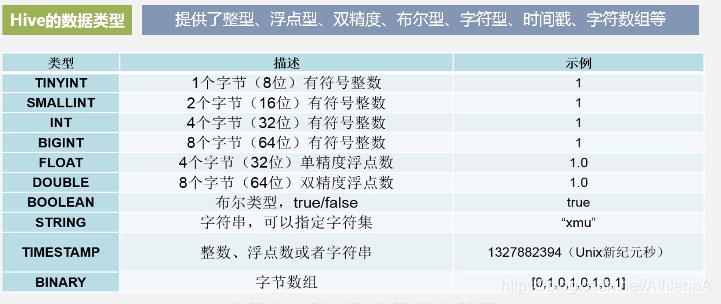
8.6.2 Hive的数据类型


8.6.3 Hive基本操作
1.create: 创建数据库、表、视图
• 创建数据库
①创建数据库hive
hive> create database hive;
②创建数据库hive。因为hive已经存在,所以会抛出异常, 加上if not exists关键字,则不会抛出异常
hive> create database if not exists hive;
• 创建表
①在hive数据库中,创建表usr,含三个属性id,name,age
hive> use hive;
hive>create table if not exists usr(id bigint,name string,age int);
②在hive数据库中,创建表usr,含三个属性id,name,age,存储路为“/usr/local/hive/warehouse/hive/usr”
hive>create table if not exists hive.usr(id bigint,name string,age int)
>location ‘/usr/local/hive/warehouse/hive/usr’;
• 创建视图
①创建视图little_usr,只包含usr表中id,age属性
hive>create view little_usr as select id,age from usr;
2.show:查看数据库、表、视图
• 查看数据库
① 查看Hive中包含的所有数据库
hive> show databases;
② 查看Hive中以h开头的所有数据库
hive>show databases like ‘h.*’;
• 查看表和视图
① 查看数据库hive中所有表和视图
hive> use hive;
hive> show tables;
② 查看数据库hive中以u开头的所有表和视图
hive> show tables in hive like ‘u.*’;
3.load:向表中装载数据
① 把目录‟/usr/local/data‟下的数据文件中的数据装载进usr表并覆盖原有数据
hive> load data local inpath ‘/usr/local/data’ overwrite into table usr;
② 把目录‟/usr/local/data‟下的数据文件中的数据装载进usr表不覆盖原有数据
hive> load data local inpath ‘/usr/local/data’ into table usr;
③ 把分布式文件系统目录‟hdfs://master_server/usr/local/data‟下的数据文件数据装载进usr表并覆盖原有数据 hive> load data inpath ‘hdfs://master_server/usr/local/data’
>overwrite into table usr;
4.insert:向表中插入数据或从表中导出数据
① 向表usr1中插入来自usr表的数据并覆盖原有数据
hive> insert overwrite table usr1
> select * from usr where age=10;
② 向表usr1中插入来自usr表的数据并追加在原有数据后
hive> insert into table usr1
> select * from usr
> where age=10;
8.6.4 Hive应用实例:WordCount
词频统计任务要求: 首先,需要创建一个需要分析的输入数据文件 然后,编写HiveQL语句实现WordCount算法
具体步骤如下:
(1)创建input目录,其中input为输入目录。命令如下:
$ cd /usr/local/hadoop
$ mkdir input
(2)在input文件夹中创建两个测试文件file1.txt和file2.txt,命令如下:
$ cd /usr/local/hadoop/input
$ echo “hello world” > file1.txt
$ echo “hello hadoop” > file2.txt
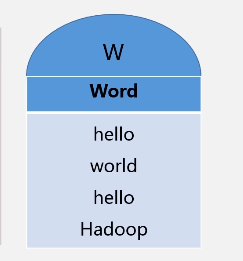
(3)进入hive命令行界面,编写HiveQL语句实现WordCount算法,命令如下:
$ hive
hive> create table docs(line string);
hive> load data inpath ‘input’ overwrite into table docs;
hive>create table word_count as
select word, count(1) as count from
(select explode(split(line,’ '))as word from docs) w //把一行行拿进来以后对它进行单词的拆分
group by word
order by word;

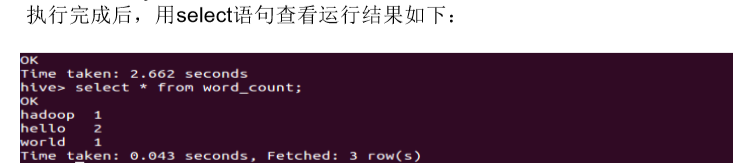
执行完成后,用select语句查看运行结果如下:
8.6.5 Hive编程的优势
WordCount算法在MapReduce中的编程实现和Hive中编程实现的 主要不同点:
1.采用Hive实现WordCount算法需要编写较少的代码量
• 在MapReduce中,WordCount类由63行Java代码编写而成
• 在Hive中只需要编写7行代码
2.在MapReduce的实现中,需要进行编译生成jar文件来执行算法 ,而在Hive中不需要
• HiveQL语句的最终实现需要转换为MapReduce任务来执行,这都是由Hive框架自动完成的,用户不需要了解具体实现细节
本章总结
• 本章详细介绍了Hive的基本知识。Hive是一个构建于Hadoop顶层的数据仓库 工具,主要用于对存储在 Hadoop 文件中的数据集进行数据整理、特殊查询 和分析处理。Hive在某种程度上可以看作是用户编程接口,本身不存储和处 理数据,依赖HDFS存储数据,依赖MapReduce处理数据。
• Hive支持使用自身提供的命令行CLI、简单网页HWI访问方式,及通过 Karmasphere、Hue、Qubole等工具的外部访问。
• Hive在数据仓库中的具体应用中,主要用于报表中心的报表分析统计上。在 Hadoop集群上构建的数据仓库由多个Hive进行管理,具体实现采用Hive HA 原理的方式,实现一台超强“hive"。
• Impala作为新一代开源大数据分析引擎,支持实时计算,并在性能上比Hive 高出3~30倍,甚至在将来的某一天可能会超过Hive的使用率而成为Hadoop 上最流行的实时计算平台。
• 本章最后以单词统计为例,详细介绍了如何使用Hive进行简单编程。
第9讲 Hadoop再探讨
9.1 Hadoop的优化与发展
9.1.1Hadoop的局限与不足
Hadoop1.0的核心组件(仅指MapReduce和HDFS,不包 括Hadoop生态系统内的Pig、Hive、HBase等其他组件), 主要存在以下不足:
•抽象层次低,需人工编码
•表达能力有限 (没办法用map和redeuce就完成很多任务)
•开发者自己管理作业(Job)之间的依赖关系 (多个mapreduce作业构成工作流,没办法进行依赖管理)
•难以看到程序整体逻辑 (么有给用户提供更高层的整体运行逻辑)
•执行迭代操作效率低 (作业分阶段,写入到HDFS中,不同阶段之间数据要迭代,效率低)
•资源浪费(Map和Reduce分两阶段执行,等所有map任务都结束后,才进入下一个阶段)
•实时性差(适合批处理,不支持实时交互式)
9.1.2针对Hadoop的改进与提升
Hadoop的优化与发展主要体现在两个方面:
•一方面是Hadoop自身两大核心组件MapReduce和 HDFS的架构设计改进

•另一方面是Hadoop生态系统其它组件的不断丰富,加入 了Pig、Tez、Spark和Kafka等新组件

9.2 HDFS2.0的新特性
9.2.1HDFS HA
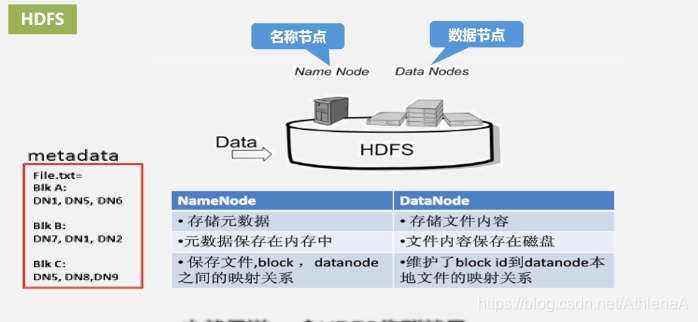
HDFS1.0组件及其功能回顾(具体请参见第3章HDFS) 名称节点保存元数据:
(1)在磁盘上:FsImage和EditLog
(2)在内存中:映射信息,即文件包含哪些块,每个块存储在哪个数据节点
HDFS 1.0存在单点故障问题
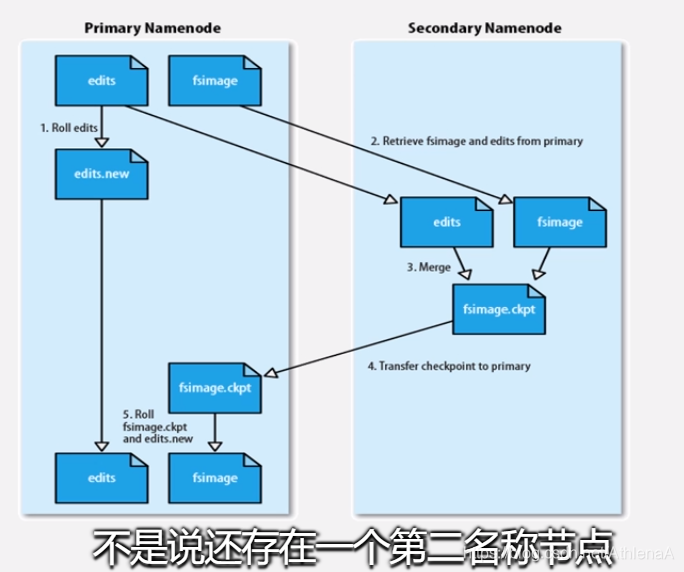
第二名称节点(SecondaryNameNode)无法解决单点故障问题
•SecondaryNameNode会定期和 NameNode通信
•从NameNode上获取到FsImage和 EditLog文件,并下载到本地的相应目录 下
•执行EditLog和FsImage文件合并
•将新的FsImage文件发送到NameNode 节点上
•NameNode使用新的FsImage和 EditLog(缩小了)
第二名称节点用途:
•不是热备份
•主要是防止日志文件EditLog过大,导 致名称节点失败恢复时消耗过多时间
•附带起到冷备份功能
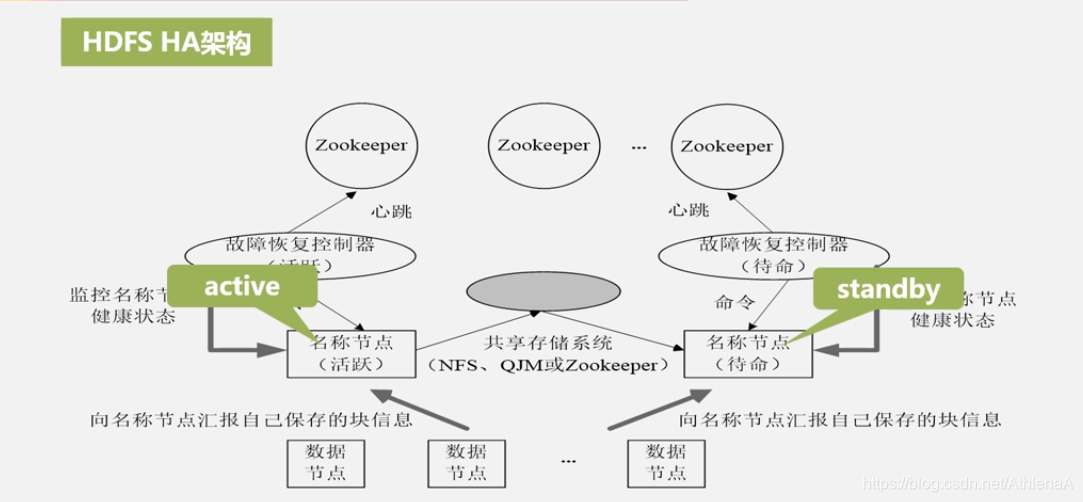
HDFS HA(High Availability)是为了解决单点故障问题
•HA集群设置两个名称节点,“活跃(Active)”和“待命(Standby)”
•两种名称节点的状态同步,可以借助于一个共享存储系统来实现 (EditLog)
•一旦活跃名称节点出现故障,就可以立即切换到待命名称节点
•Zookeeper确保一个名称节点在对外服务
•名称节点维护映射信息,数据节点同时向两个名称节点汇报信息 (实时的映射信息)
9.2.2HDFS Federation
1.HDFS1.0中存在的问题 (以上HA解决的是热备份的问题)
•单点故障问题
•不可以水平扩展(是否可以通过纵向扩展来解决?)
•系统整体性能受限于单个名称节点的吞吐量
•单个名称节点难以提供不同程序之间的隔离性
•HDFS HA是热备份,提供高可用性,但是无法解决可扩展性、系统性能和隔离性
2.HDFS Federation的设计
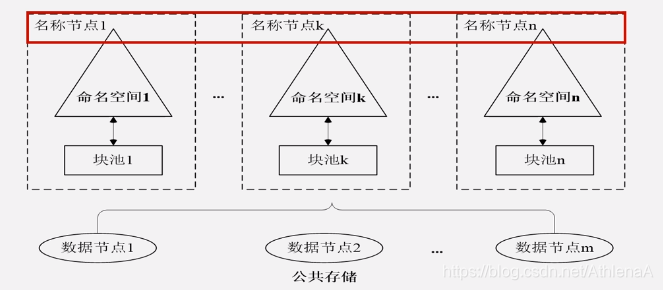
•在HDFS Federation中,设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟 (Federation)关系,不需要彼此协调。 并且向后兼容
•HDFS Federation中,所有名称节点会共 享底层的数据节点存储资源,数据节点向 所有名称节点汇报
•属于同一个命名空间的块构成一个“块池”
3.HDFS Federation的访问方式
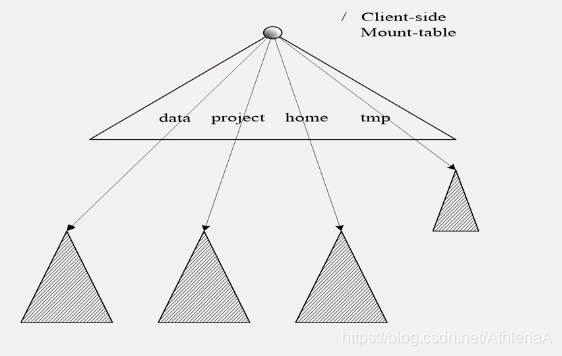
•对于Federation中的多个命名空间,可以采用客户端挂载表(Client Side Mount Table)方式进行数据共享和访问
•客户可以访问不同的挂载点来访问不同的子命名空间
•把各个命名空间挂载到全局“挂载表” (mount-table)中,实现数据全局共享
•同样的命名空间挂载到个人的挂载表中, 就成为应用程序可见的命名空间 3
4.HDFS Federation相对于HDFS1.0的优势
HDFS Federation设计可解决单名称节点存在的以下几个问题:
(1)HDFS集群扩展性。多个名称节点各自分管一部分目录,使得一个集 群可以扩展到更多节点,不再像HDFS1.0中那样由于内存的限制制约文件 存储数目
(2)性能更高效。多个名称节点管理不同的数据,且同时对外提供服务, 将为用户提供更高的读写吞吐率 (3)良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点 管理,这样不同业务之间影响很小
需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每 个名称节点都存在在单点故障问题,需要为每个名称节点部署一个后备名 称节点,以应对名称节点挂掉对业务产生的影响
9.3 新一代资源管理调度框架YARN
9.3.1 MapReduce1.0的缺陷
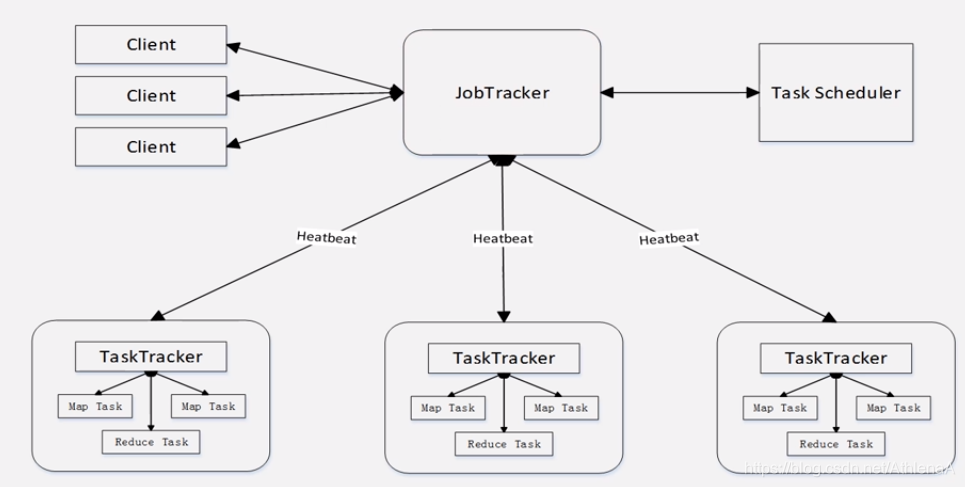
(1)存在单点故障
(2)JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
(3)容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
(4)资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
9.3.2 YARN设计思路
YARN架构思路:将原JobTacker三大功能拆分
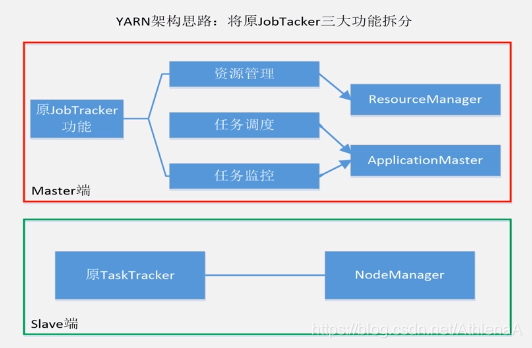
•MapReduce1.0既是一个计 算框架,也是一个资源管理 调度框架
•到了Hadoop2.0以后, MapReduce1.0中的资源管 理调度功能,被单独分离出 来形成了YARN,它是一个 纯粹的资源管理调度框架, 而不是一个计算框架
•被剥离了资源管理调度功能 的MapReduce 框架就变成 了MapReduce2.0,它是运 行在YARN之上的一个纯粹 的计算框架,不再自己负责 资源调度管理服务,而是由 YARN为其提供资源管理调 度服务
9.3.3 YARN体系结构
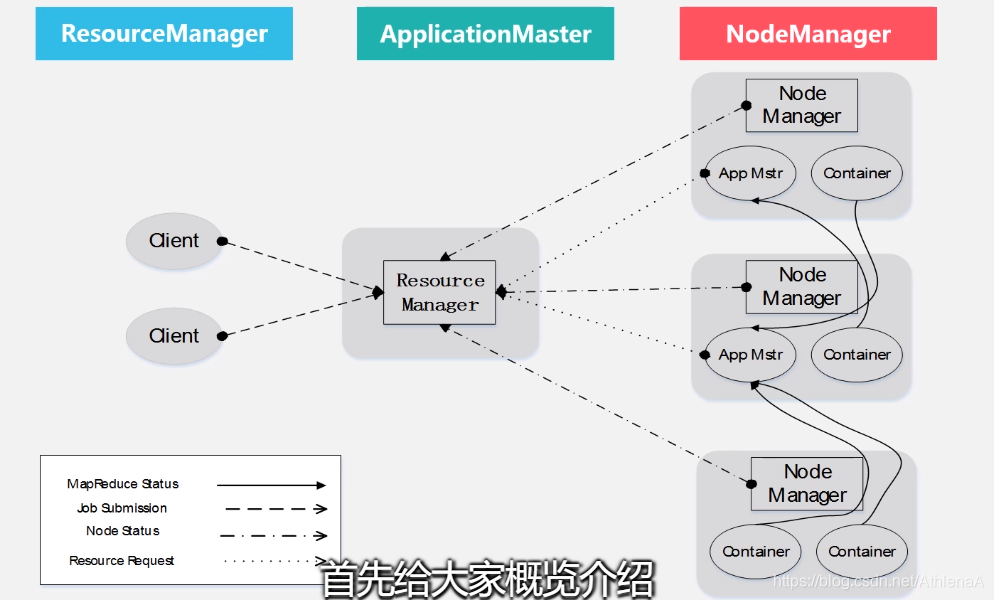
ResourceManager •处理客户端请求 •启动/监控ApplicationMaster •监控NodeManager •资源分配与调度
NodeManager •单个节点上的资源管理 •处理来自ResourceManger的命令 •处理来自ApplicationMaster的命令
ApplicationMaster •为应用程序申请资源, 并分配给内部任务 •任务调度、监控与容错
ResourceManager
•ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主 要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)
•调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行 就近选择,从而实现“计算向数据靠拢”
•容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、内存、 磁盘等资源,从而限定每个应用程序可以使用的资源量
•调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器
•应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状 态并在失败时重新启动等
ResourceManager
ApplicationMaster
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集 来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster
ApplicationMaster的主要功能是:
(1)当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源, ResourceManager会以容器的形式为ApplicationMaster分配资源;
(2)把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”;
(3)与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行 失败恢复(即重新申请资源重启任务);
(4)定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息;
(5)当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
NodeManager
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
•容器生命周期管理
•监控每个容器的资源(CPU、内存等)使用情况
•跟踪节点健康状况
•以“心跳”的方式与ResourceManager保持通信
•向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
•接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事 情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这 些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与 NodeManager通信来掌握各个任务的执行状态
在集群部署方面,YARN的各个组件是和Hadoop集群中的其他组件进行统一部署的
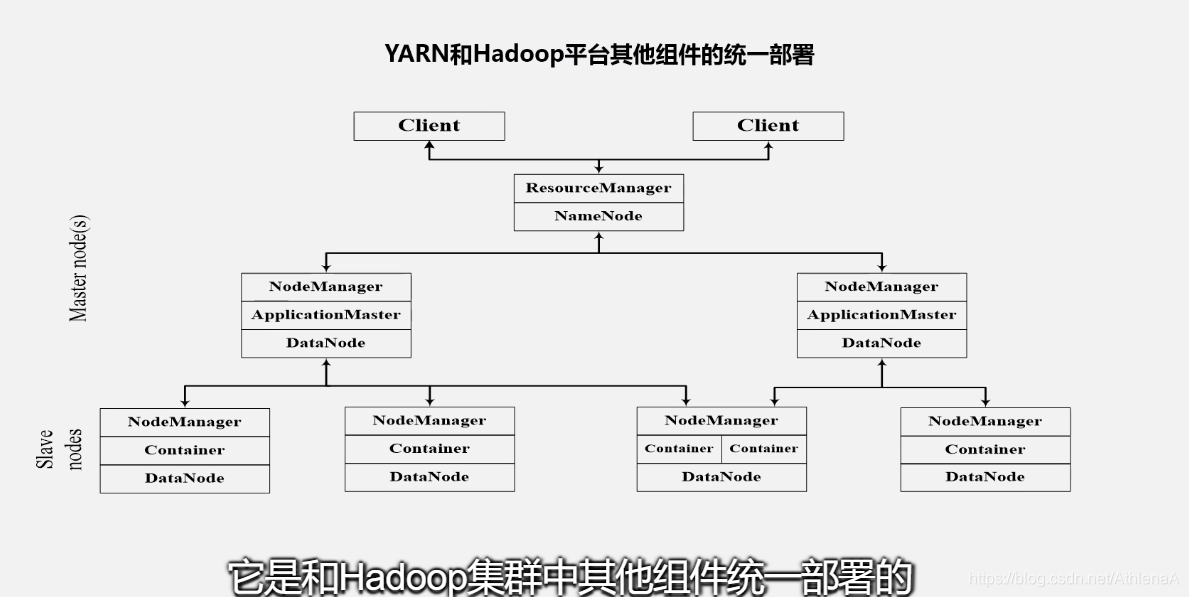
9.3.4 YARN工作流程

步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括 ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
步骤2:YARN中的ResourceManager负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个ApplicationMaster
步骤3:ApplicationMaster被创建后会首先向 ResourceManager注册
步骤4:ApplicationMaster采用轮询的方式向 ResourceManager申请资源
步骤5:ResourceManager以“容器”的形 式向提出申请的ApplicationMaster分配资源
步骤6:在容器中启动任务(运行环境、脚本)
步骤7:各个任务向ApplicationMaster汇报自己的状态和进度
步骤8:应用程序运行完成后, ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己
9.3.5 YARN框架与MapReduce1.0框架的对比分析
从MapReduce1.0框架发展到YARN框架,客户端并没有发生变化,其大部分调用API及 接口都保持兼容,因此,原来针对Hadoop1.0开发的代码不用做大的改动,就可以直接放 到Hadoop2.0平台上运行
总体而言,YARN相对于MapReduce1.0来说具有以下优势:
•大大减少了承担中心服务功能的ResourceManager的资源消耗
•ApplicationMaster来完成需要大量资源消耗的任务调度和监控
•多个作业对应多个ApplicationMaster,实现了监控分布化
•MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是,只能支持 MapReduce编程模型。
•而YARN则是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架,只要编程实现相应的ApplicationMaster 可替换的模块
•YARN中的资源管理比MapReduce1.0更加高效
•以容器为单位,而不是以slot为单位
9.3.6 YARN的发展目标
YARN的目标就是实现“一个集群多个框架”,为什么?
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架
•MapReduce实现离线批处理
•使用Impala实现实时交互式查询分析
•使用Storm实现流式数据实时分析
•使用Spark实现迭代计算
•这些产品通常来自不同的开发团队,具有各自的资源调度管理机制
•为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个集群,分 别安装运行不同的计算框架,即“一个框架一个集群”
导致问题
•集群资源利用率低
•数据无法共享
•维护代价高
•YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源 调度管理框架YARN,在YARN之上可以部署其他各种计算框架
•由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架 的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩
•可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率
•不同计算框架可以共享底层存储,避免了数据集跨集群移动

9.4 Hadoop生态系统中具有代表性的功能组件
9.4.1 Pig
Pig是Hadoop生态系统的一个组件
•提供了类似SQL的Pig Latin语言(包含Filter、GroupBy、Join、 OrderBy等操作,同时也支持用户自定义函数)
•允许用户通过编写简单的脚本来实现复杂的数据分析,而不需要编 写复杂的MapReduce应用程序
•Pig会自动把用户编写的脚本转换成MapReduce作业在Hadoop集群 上运行,而且具备对生成的MapReduce程序进行自动优化的功能
•用户在编写Pig程序的时候,不需要关心程序的运行效率,这就大大 减少了用户编程时间
•通过配合使用Pig和Hadoop,在处理海量数据时就可以实现事半功 倍的效果,比使用Java、C++等语言编写MapReduce程序的难度要 小很多,并且用更少的代码量实现了相同的数据处理分析功能
Pig可以加载数据、表达转换数据以及存储最终结果
Pig语句通常按照如下的格式来编写:
•通过LOAD语句从文件系统读取数据
•通过一系列“转换”语句对数据进行处理
•通过一条STORE语句把处理结果输出到文件系统中,或者使用DUMP语句把 处理结果输出到屏幕上
数
下面是一个采用Pig Latin语言编写的应用程序实例,实现对用户访问网页 情况的统计分析:
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits); //得到的表的结构
visitCounts(url,visits) urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url; //得到的连接结果表的结构visitCounts(url,visits,category,pRank) gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
Pig Latin是通过编译为MapReduce在 Hadoop集群上执行的。统计用户访问 量程序被编译成MapReduce时,会产 生如图所示的Map和Reduce
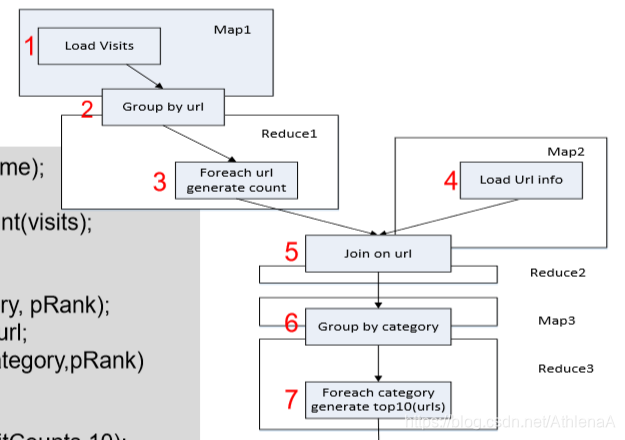
1 visits = load ‘/data/visits’ as (user, url, time);
2 gVisits = group visits by url;
3 visitCounts = foreach gVisits generate url, count(visits); //得到的表的结构visitCounts(url,visits)
4 urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
5 visitCounts = join visitCounts by url, urlInfo by url; //得到的连接结果表的结构visitCounts(url,visits,category,pRank)
6 gCategories = group visitCounts by category;
7 topUrls = foreach gCategories generate top(visitCounts,10);
8 store topUrls into ‘/data/topUrls’;
Pig的应用场景
•数据查询只面向相关技术人员
•即时性的数据处理需求,这样可 以通过pig很快写一个脚本开始运 行处理,而不需要创建表等相关 的事先准备工作
Pig主要用户
•Yahoo!: 90%以上的MapReduce作业是Pig生成的
•Twitter: 80%以上的MapReduce作业是Pig生成的
•Linkedin: 大部分的MapReduce作业是Pig生成的
•其他主要用户: Salesforce, Nokia, AOL, comScore
9.4.2 Tez
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架
•核心思想是将Map和Reduce两个操作进一步拆分
•Map被拆分成Input、Processor、Sort、Merge和Output
• Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等
•分解后的元操作可以任意灵活组合,产生新的操作
•这些操作经过一些控制程序组装后,可形成一个大的DAG作业
•通过DAG作业的方式运行MapReduce作业,提供了程序运行的整体处理逻辑,就可以去除工作流当中多余的Map阶段,减少不必要的操作, 提升数据处理的性能
•Hortonworks把Tez应用到数据仓库Hive的优化中,使得性能提升了约 100倍
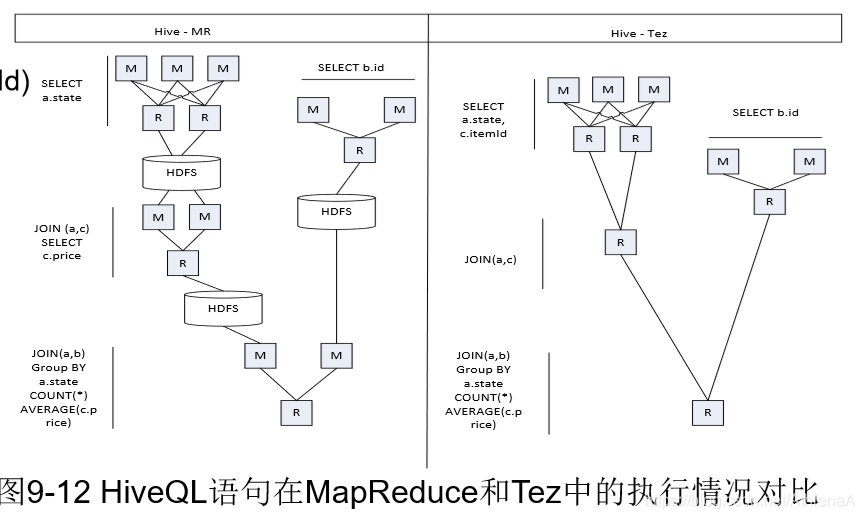
SELECT a.state, COUNT(*),AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
图9-12 HiveQL语句在MapReduce和Tez中的执行情况对比
•Tez的优化主要体现在:
•去除了连续两个作业 之间的“写入HDFS”
•去除了每个工作流中 多余的Map阶段
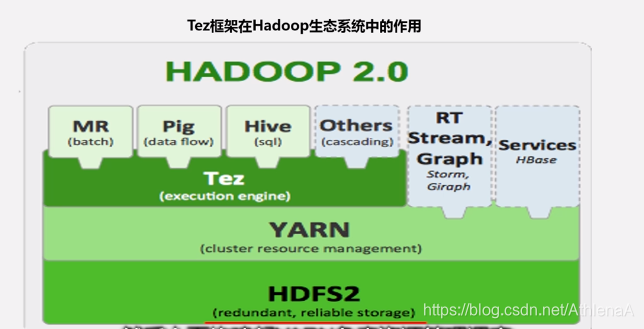
•在Hadoop2.0生态系统中,MapReduce、Hive、Pig等计算框架,都需要最终 以MapReduce任务的形式执行数据分析,因此,Tez框架可以发挥重要的作用
•借助于Tez框架实现对MapReduce、Pig和Hive等的性能优化
•可以解决现有MR框架在迭代计算(如PageRank计算)和交互式计算方面的 问题
(Tez+Hive)与Impala、Dremel和Drill的区别?
Tez在解决Hive、Pig延迟大、性能低等问题的思路,是和那些支持实时交互式 查询分析的产品(如Impala、Dremel和Drill等)是不同的
•Impala、Dremel和Drill的解决问题思路是抛弃MapReduce计算框架,不再将类 似SQL语句的HiveQL或者Pig语句翻译成MapReduce程序,而是采用与商用并行 关系数据库类似的分布式查询引擎,可以直接从HDFS或者HBase中用SQL语句 查询数据,而不需要把SQL语句转化成MapReduce任务来执行,从而大大降低 了延迟,很好地满足了实时查询的要求
•Tez则不同,比如,针对Hive数据仓库进行优化的“Tez+Hive”解决方案,仍采 用MapReduce计算框架,但是对DAG的作业依赖关系进行了裁剪,并将多个小 作业合并成一个大作业,这样,不仅计算量减少了,而且写HDFS次数也会大大 减少
9.4.3 Spark
Hadoop缺陷,其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因 而只适用于离线批处理的应用场景
•中间结果写入磁盘,每次运行都从磁盘读数据
•在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任 务
Spark最初诞生于伯克利大学的APM实验室,是一个可应用于大规模数据处理的快速、 通用引擎,如今是Apache软件基金会下的顶级开源项目之一
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题
•内存计算,带来了更高的迭代运算效率
•基于DAG的任务调度执行机制,优于MapReduce的迭代执行机制
当前,Spark正以其结构一体化、功能多元化的优势,逐渐成为当今大数据领域最热门 的大数据计算平台
9.4.4 Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消 息,同时也能实时订阅消费消息
•Kafka可以同时满足在线实时处理和批量离线处理
•在公司的大数据生态系统 中,可以把Kafka作为数 据交换枢纽,不同类型的 分布式系统(关系数据库、 NoSQL数据库、流处理系 统、批处理系统等),可以统一接入到Kafka,实 现和Hadoop各个组件之 间的不同类型数据的实时 高效交换 Kafka
