本篇博客主要是对于train文件以及yolov5s.yaml文件进行讲解,yolov5代码虽然一直有在更新但整体的框架基本相似。
1.Usage
该部分是作者的一个说明。
第一行表示我们传入的data数据集是coco128数据集,权重模型是yolov5s模型,–img表示图片大小640,第二行与第一行的主要区别在于,第一行是在加载yolov5s的权重基础上进行训练,而第二行是在配置yolov5s网络结构后,从零开始搭建一个模型,然后从头开始训练。

2.导包、导库操作
前面都是一些导包导库操作,train文件在如下图部分出现三个参数,这三个参数主要用于分布式训练,对于我们初学者而言,一般都是默认参数。

3.解析参数
将参数进行传递然后解析。主要包含四大部分。
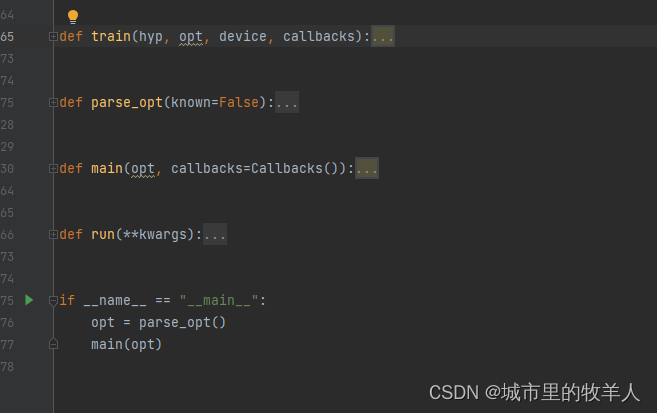
3.1首先是校验函数
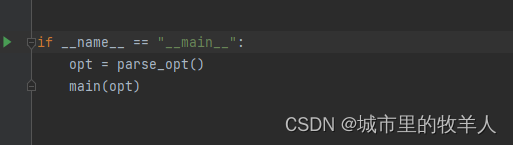
3.2main函数
首先是代码的校验工作,紧接着会根据是否在命令行传入Resume来判断执行不同的操作,第三部分会判断你是否采用DDP这种训练方法,第四部分开始正式进行训练。
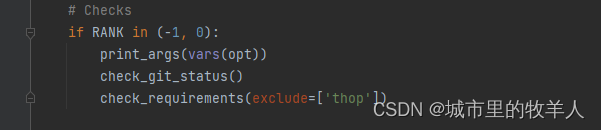
首先它会根据rank变量来判断是否执行下面的三行代码,这块rank的这个值在开头也已经说过,如果不进行分布式训练的话,默认是-1,因此它会去执行下面的三行代码,第一行是负责打印文件所用到的参数信息,这个参数包括命令行传入进去的参数以及默认参数,第二行是检查yolov5的github仓库是否更新,如果更新的话,会有一个提示。第三行用来检查requirements中要求的安装包有没有正确安装成功,没有成功的话会给予一定的提示。
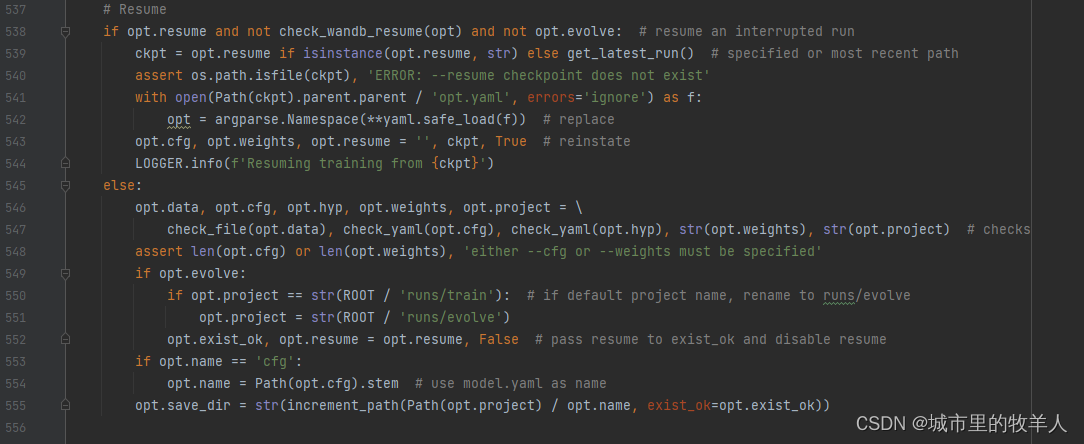
首先它会判断你有没有在命令行中传入resume这个参数,resume参数表示在中断中恢复,例如我们因电脑断电等情况下,导致训练尚未完成而停止,那我们就可以利用这个参数将我们之前的训练给恢复过来。因为我们使用的是yolov5s.pt这个训练模型,因此并没有必要传入这个参数,所以它会执行else中的代码内容。
在else代码中首先它会去检查这几个文件的路径,包括数据集data,cfg以及权重、project等,这里我们没有用到cfg,因此它传入为空,紧接着判断cfg与weights是否都为空,如果为空的话,会进行报错。
接下来会进行是否输入evolve判断,决定保存在那个文件夹下面,那这里我们没有输入evolve。接着是保存文件的名称。
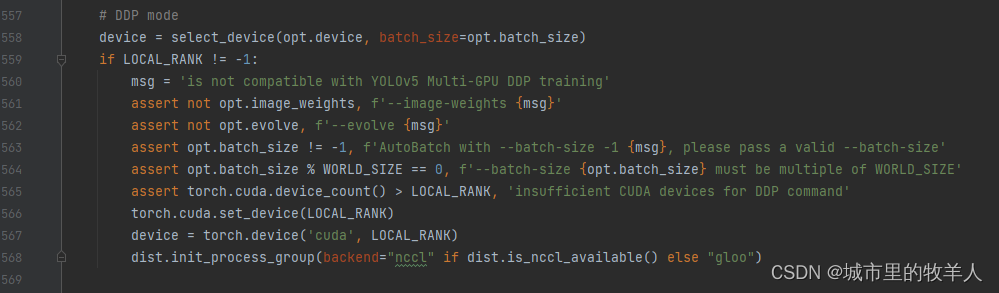
这部分它会选择你是使用cpu还是gpu,假如你采用的是分布式训练的话,它就会额外执行下面的一些操作,我们这里一般不会用到分布式,所以也就没有执行什么东西。
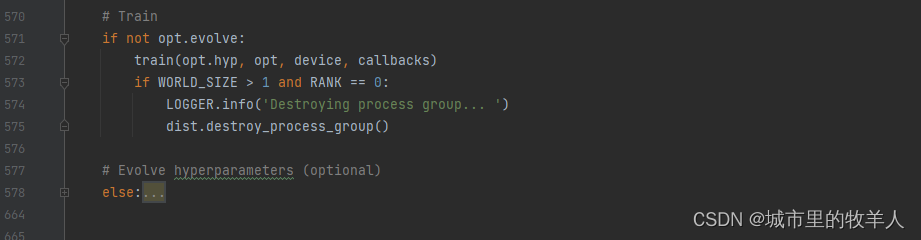
在模型训练这部分,如果输入evolve会执行else下面这些代码,因为我们没有输入evolve并且不是分布式训练,因此会执行train函数。因此,其实我们只需要关注一下train函数就可以啦。evolve呢是作者给出的一种净化超参数的方法,一般情况下,我们采用默认的参数配合部分手动调参,就已经足够优秀啦。
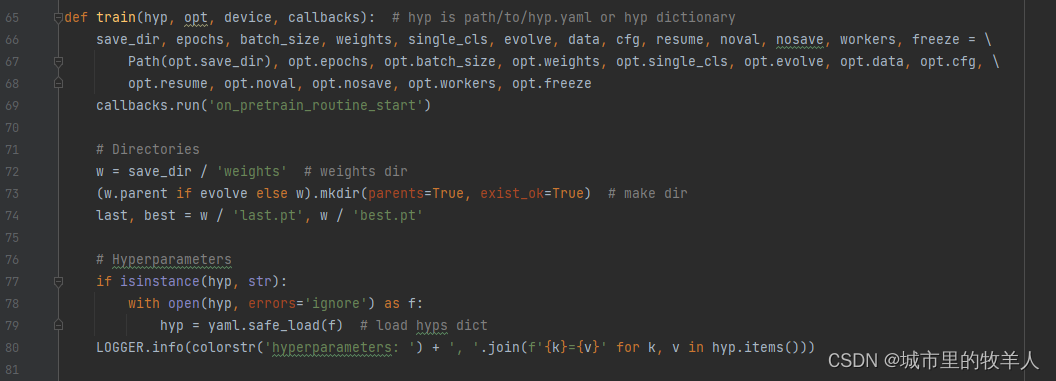
3.3train函数
然后是最关键的train函数,首先是一些参数的传入,然后定义了训练权重文件的文件路径保存,紧接着是一些训练过程中需要使用的超参数,将一些超参数加载,并打印出来。
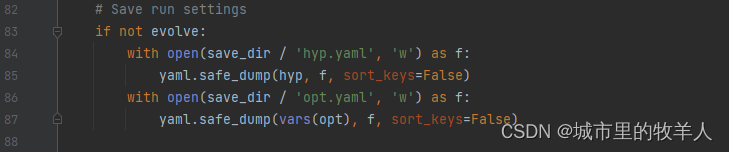
随后进行运行配置过程的保存操作,会保存在你训练目录下的hyp.yaml文件中,并且会保存你执行过程中使用的参数在opt.yaml文件中。

在日志文件中,基于wandb与tensorboard这两个库来完成训练过程中的可视化操作。在这个文件中完成对于程序训练日志的记录过程。
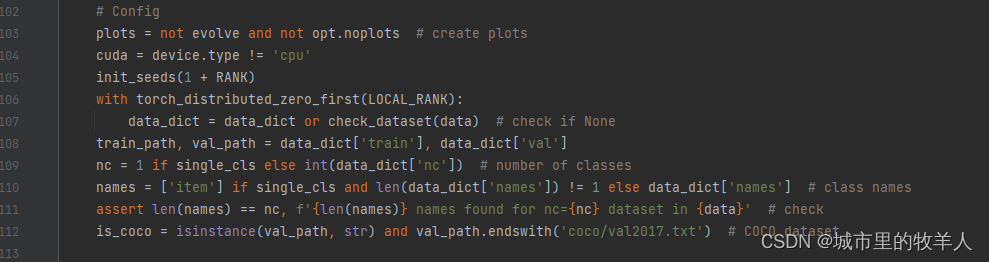
Config文件中,首先基于plots的true或者false反馈是否将训练过程及结果给画出来,紧接着判断电脑是否支持cuda,第三行是为了保证我们的训练是否是可复现的,第四行是与分布式训练相关的,如果不进行分布式训练则不执行。第五行会进行数据集检查读取操作,第六行会取出数据集的训练路径以及验证路径,第七行取出你的类名,第八行会进行类的种数以及类的名称是否相同的判断,不相同会进行报错处理,最后一行会进行是否是coco数据集进行判断,如果是的话会进行一些额外的操作,本次不是,回复false。
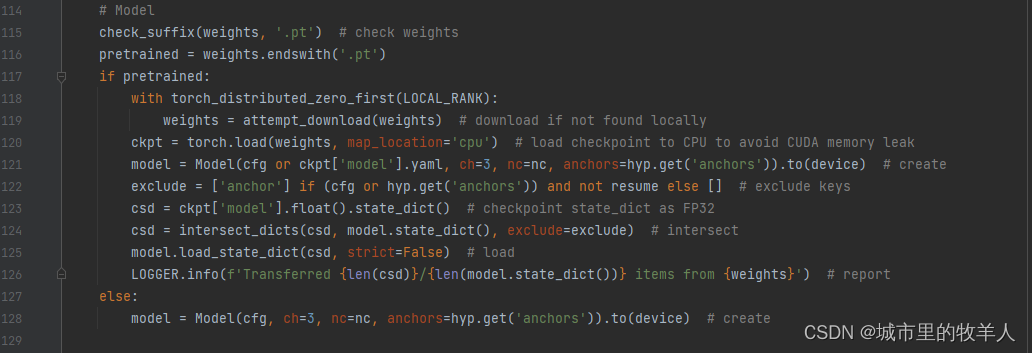
然后呢是模型加载部分,首先会去检测传进来的权重参数后缀名是否以.pt结尾,如果本地没有就回去会尝试去yolov5官方仓库去下载权重文件,加载权重文件,紧接着会根据你的权重文件中会带着一个yolov5s.yaml文件,代码根据yolov5s.yaml进行模型的训练。这块的主要意思通俗的理解就是我们预训练模型是yolov5s.pt,我们的新模型是基于我们自己的识别检测需求在yolov5s的基础上完成的。

Freeze是一个冻结过程,跟我们的传递参数有关,默认不冻结,在opt中我们传入10即表示我们冻结了backbone部分,也就是说我们训练过程中只用了head部分。通过Freeze这部分代码,你可以手动去控制你想冻结哪些层。

这部分代码主要是用于检查输入图片的尺寸满不满足32的倍数,如果不满足的话它会帮你自动补成32的倍数。

Batchsize部分一般不会去执行,除非我们手动输入-1,默认是16。
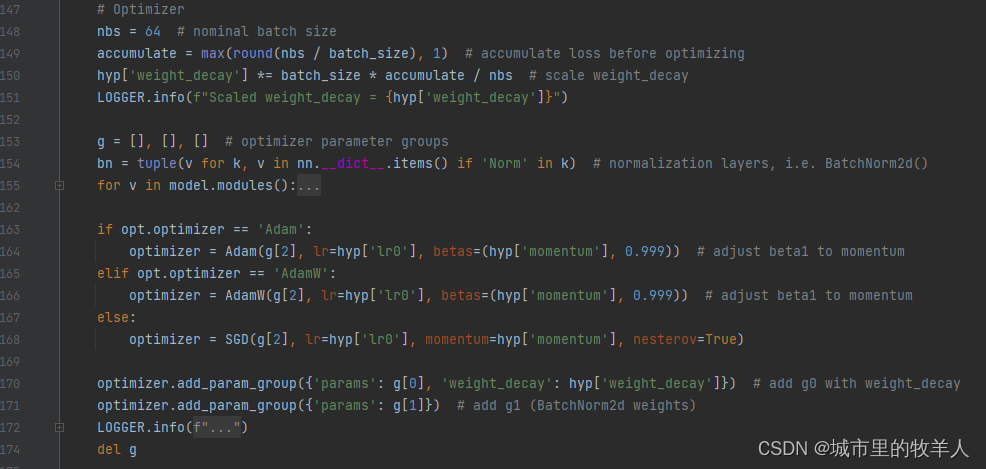
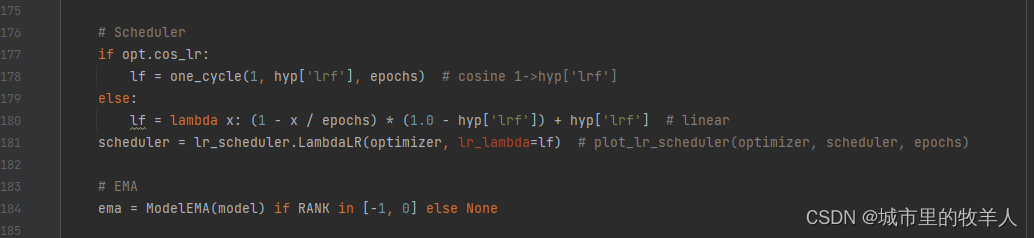
接下来是创建深度学习的优化器,随机衰减策略以及指数移动平均的方法。
#DP mode会判断是不是用了多张显卡,#SyncBatchNorm是跟分布式训练相关的,然后是加载训练数据操作,加载验证集数据操作。
紧接着是开始训练工作,在这个工程中,“compute_loss=ComputeLoss(model)”定义损失函数,等到训练结束,这个时候会挑选出 best.weight对验证集进行验证测试,并把这个结果给打印出来。
4.YoloV5S.yaml

nc表示yolov5s所能预测出来的种类数,这里是80种。anchors就是提前定义好的一些矩形框,利用这些矩形框完成检测。三层anchors分别对应不同的特征层级,在每一层anchors上又定义了3个不同的anchors。depth_multiple深度倍数表示的含义体现为backbone中number的参数乘以depth_multiple即为实际参数,width_multiple表示通道参数,args中的特征通道参数乘以width_multiple即为实际参数。实际对比yolov5s、5l、5m、5n、以及5x就可以发现,.yaml文件中只有depth_multiple深度倍数以及width_multiple通道参数是不一样的。因此,这两个参数可以通俗的理解为调整网络规模。
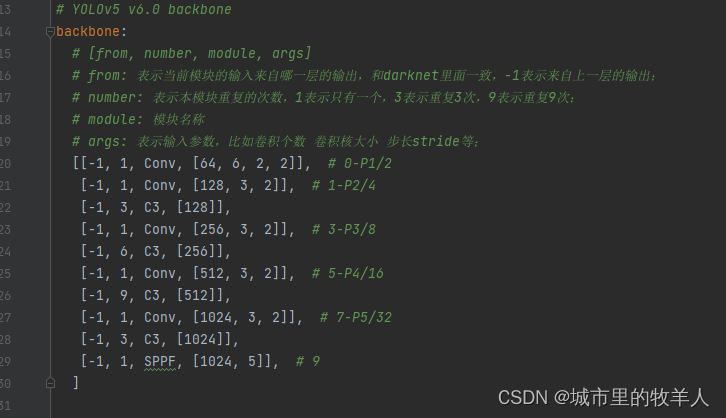
backbone表示yolov5模型结构中的backbone结构,这一行行表示yolov5每一层的结构信息,不同的层结构都定义在common.py文件中,这里的Conv、C3、Concat等,args表示参数,是根据前面module的形式确定相应的参数。
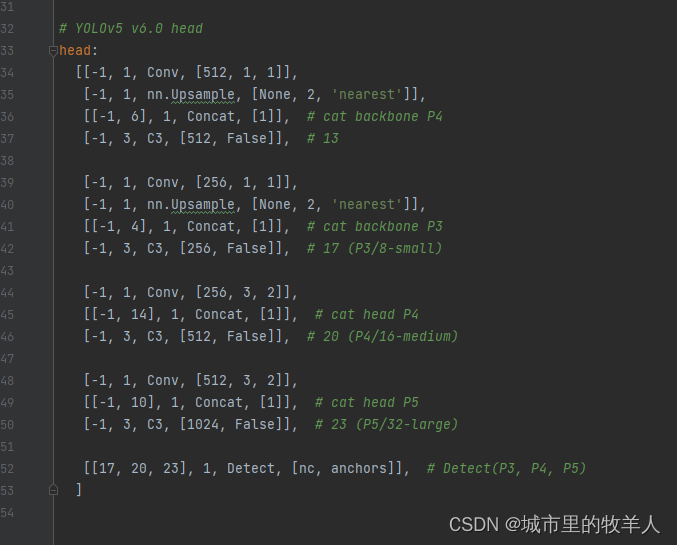
head表示yolov5的head部分,yolov5中没有neck,相似结构被作者并在head里。
本次就先到这,学习交流,互相进步~