计划完成深度学习入门的126篇论文第三十六篇,FAIR的Tomas Mikolov等发表的在文本分类的Bag技巧的论文。FastText [github]
Abstract
本文探讨了一种简单有效的文本分类基准。实验表明,我们的快速文本分类器fastText在准确率上与深度学习分类器基本相当,在训练和评价方面,速度提高了许多数量级。使用一个标准的多核CPU,我们可以在不到10分钟的时间内训练快速文本处理超过10亿个单词,并且在不到一分钟的时间内在312K个类中分类50万个句子。
1 Introduction
文本分类是自然语言处理中的一项重要任务,有许多应用,如web搜索、信息检索、排序和文档分类(Deerwester et al., 1990; Pang and Lee, 2008)。近年来,基于神经网络的模型越来越受欢迎(Kim, 2014; Zhang and LeCun, 2015; Conneau et al., 2016)。虽然这些模型在实践中实现了非常好的性能,但是它们在训练和测试时的速度都相对较慢,这限制了它们在非常大的数据集上的使用。
同时,线性分类器通常被认为是文本分类问题的强baselines(Joachims, 1998; McCallum and Nigam, 1998; Fan et al., 2008)。尽管它们很简单,但如果使用了正确的功能,它们通常可以获得最先进的性能(Wang and Manning, 2012)。它们也有可能扩展到非常大的语料库(Agarwal et al., 2014)。
在本文中,我们将探讨如何在文本分类的上下文中将这些baselines扩展到具有较大输出空间的非常大的语料库。受近期高效词汇表征学习(Mikolov et al., 2013; Levy et al., 2015),我们证明了具有秩约束和快速损失近似的线性模型可以在10分钟内训练10亿个单词,同时实现与最先进水平相当的性能。我们评估了fastText方法在两个不同任务上的质量,即标签预测和情绪分析。
2 Model architecture
一个简单有效的句子分类baselines是将句子表示为单词包(BoW)并训练线性分类器,如logistic回归或SVM(Joachims, 1998; Fan et al., 2008)。然而,线性分类器不会在特征和类之间共享参数。这可能限制了它们在大输出空间上下文中的泛化,其中一些类只有很少的例子。这个问题的常见解决方案是将线性分类器分解为低秩矩阵(Schutze, 1992; Mikolov et al., 2013)或使用多层神经网络(Collobert and Weston, 2008; Zhang et al., 2015)。、

图1显示了一个带有秩约束的简单线性模型。第一个权重矩阵A是单词的查找表。然后将单词表示平均为文本表示,然后将文本表示反馈给线性分类器。文本表征是一个隐藏层变量被重用。这种架构类似于Mikolov等人(2013)的cbow模型,其中中间的单词被一个标签替代。我们使用softmax函数f来计算预定义类的概率分布。对于一组N个文档,这将导致类的negative loglikelihood最小化
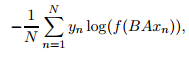
其中xn是第n个文档特征的标准化包,yn是标签,A和B是权重矩阵。该模型采用随机梯度下降和线性衰减学习率在多个cpu上异步训练。
2.1 Hierarchical softmax
当类数较大时,线性分类器的计算开销较大。更精确地说,计算复杂度是O(kh),其中k是类的数量,h是文本表示的维数。为了提高我们的运行时间,我们使用了基于霍夫曼编码树的Hierarchical softmax (Goodman, 2001) (Mikolov et al., 2013)。在训练过程中,计算复杂度降低到O(h log2(k))。
在搜索最有可能的类时,Hierarchical softmax最大值在测试时也很有优势。每个节点都与一个概率相关联,这个概率就是从根节点到该节点的路径的概率。如果节点深度为l + 1,父节点![]() ,它的概率是
,它的概率是
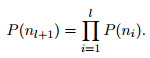
这意味着节点的概率总是小于其父节点的概率。先深度搜索树,然后跟踪叶子之间的最大概率,这样我们就可以丢弃任何与小概率相关的分支。在实践中,我们观察到在测试时复杂度降低到O(h log2(k))。该方法进一步扩展到使用二进制堆以O(log(T))为代价计算T -top目标。
2.2 N-gram features
单词包对单词顺序是不变的,但是明确地考虑这个顺序通常在计算上非常昂贵。相反,我们使用一个n-gram作为附加功能来捕获关于本地词序的部分信息。这在实践中是非常有效的,同时可以获得与显式使用order的方法相比较的结果(Wang and Manning, 2012)。
我们使用哈希技巧(Weinberger et al., 2009)来保持n-gram的快速高效内存映射,哈希函数与Mikolov et al.(2011)相同,如果只使用big,则使用10M bin,否则使用100M bin。
3 Experiments
我们在两个不同的任务上评估fastText。
首先,在情感分析问题上,将其与现有的文本分类器进行了比较。然后,我们评估了它在标签预测数据集上扩展到大输出空间的能力。注意,我们的模型可以使用Vowpal Wabbit库实现,但是我们在实践中发现,我们定制的实现至少比Wabbit库快2-5倍。
3.1 Sentiment analysis
Datasets and baselines. 我们使用了与Zhang等人(2015)相同的8个数据集和评估协议。我们报告了Zhang等人(2015)的n-gram和TFIDF baselines,以及Zhang和LeCun(2015)的字符级卷积模型(char-CNN)、Conneau等人(2016)的基于字符的卷积递归网络(char - CRNN)和very deep convolutional network (VDCNN)。我们也比较Tang等人(2015)遵循他们的评估方案。本文介绍了它们的主要baselines及其基于递归网络的两种方法(convg - grnn和LSTM-GRNN)。
Results.我们在图1中给出了结果。我们使用10个隐藏单元,运行5个epochs的fastText,在{0.05,0.1,0.25,0.5}的验证集上选择一个学习率。在这个任务中,添加bigram信息可以将性能提高1-4%。总体来说,我们的准确率略好于charn - cnn和charn - crnn,略差于VDCNN。注意,我们可以通过使用更多的n-g来稍微提高精度,例如使用三元组,搜狗的性能可以提高到97.1%。

最后,图3显示了我们的方法与Tang等人(2015)提出的方法具有竞争力。我们对验证集上的超参数进行调优,并观察到使用最多5个n-g可以获得最佳性能。与Tang等人(2015)不同,fastText不使用预先训练好的单词嵌入,这可以解释1%的准确率差异

Training time.cha-RCNN和VDCNN都是在NVIDIA Tesla K40 GPU上训练的,而我们的模型是在CPU上使用20个线程训练的。

表2显示使用卷积的方法比fastText慢几个数量级。虽然使用最新的卷积CUDA实现可以使charcnn的速度提高10,但是fastText在这些数据集上的训练只需要不到一分钟。Tang等人(2015)的GRNNs方法在单线程CPU上每epochs花费大约12小时。我们的速度, 与基于神经网络的方法相比,随着数据集的增大而增大,至少可以达到15,000×加速。
3.2 Tag prediction
Dataset and baselines. 为了测试我们的方法的可扩展性,我们对YFCC100M数据集(Thomee et al., 2016)进行了进一步的评估。我们主要根据标题和标题来预测标签(我们不使用图像)。我们将出现少于100次的单词和标签删除,并将数据分割为一个序列、验证和测试集。这个序列集包含91,188,648个示例(1.5B令牌)。验证包含930,497个示例,测试集包含543,424个。词汇量为297,141,有312,116个独特的标签。我们将发布一个重新创建该数据集的脚本,以便可以复制我们的数字。我们报告精度为1。
’我们考虑一个基于频率的baselines来预测最频繁的标签。我们还比较了Tagspace (Weston et al., 2014),这是一个类似于我们的标签预测模型,但基于Weston et al.(2011)的Wsabie模型。虽然标记空间模型是使用卷积来描述的,但是我们考虑了线性版本,它可以实现类似的性能,但是速度要快得多。
Results and training time. 表5给出了fastText和baselines的比较。

我们运行5个epochs的fastText,并将其与隐藏层的两种大小的Tagspace进行比较,即,50和200年。这两种模型都实现了类似的性能,只是隐藏了一个小层,但是添加bigrams可以显著提高精确度。在测试时,Tagspace需要计算所有类的分数,这使得它相对较慢,而当类的数量较大(这里超过300K)时,我们的快速推理可以显著加快速度。总的来说,我们比一个数量级更快地获得了具有更好质量的模型。测试阶段的加速更为显著(600×speedup)。表4显示了一些定性的例子。

4 Discussion and conclusion
本文提出了一种简单的文本分类基线方法。与来自word2vec的未经监督训练的单词向量不同,我们的单词特征可以平均在一起,形成良好的句子表示。在几个任务中,fastText的性能与最近提出的方法相当,这些方法受到了深度学习的启发,而且速度更快。虽然深层神经网络在理论上比浅层模型具有更高的表征能力,但尚不清楚情绪分析等简单的文本分类问题是否适合对其进行评估。我们将发布我们的代码,以便研究社区可以轻松地在我们的工作之上构建。