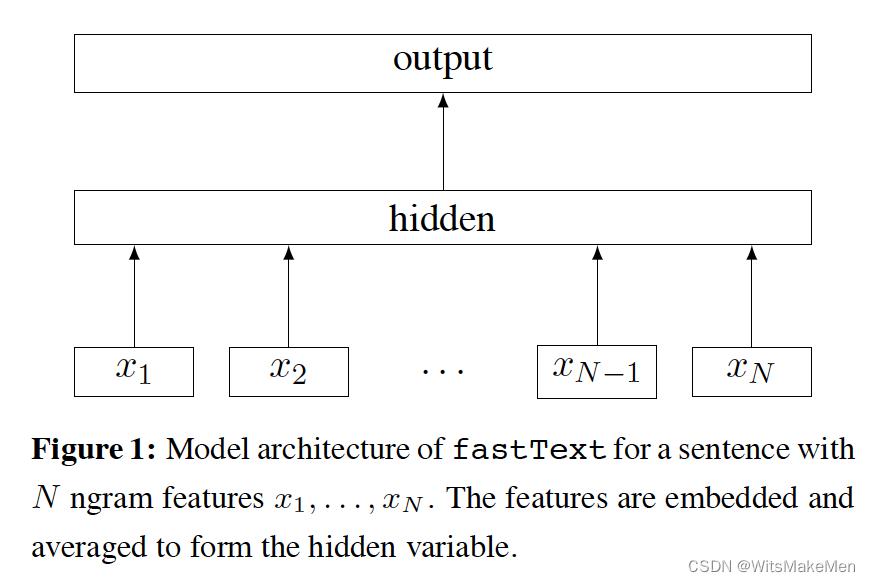
主要的有点就是快,用途就是用于文本分类,模型结构如上,主要是通过embedding将文本转换成向量,然后进行mean-pooling,然后输入到hidden隐向量中,通过softmax输出多分类,损失函数是对数似然损失函数(log-likelihood loss).
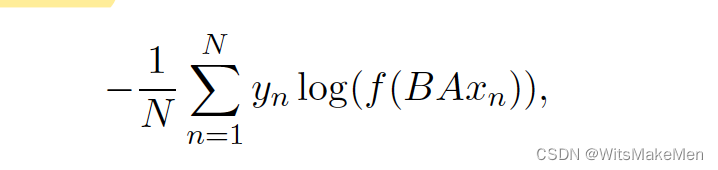
Bag of Tricks for Efficient Text Classification(FastText)
猜你喜欢
转载自blog.csdn.net/WitsMakeMen/article/details/133968101
今日推荐
周排行