每次在我们做模型的时候都会为模型的好坏而发愁,那么有没有什么办法可以有效的提高模型的评分呢?
今天我刚好学习到这里,那么我就记下来(主要防止自己忘记,哈哈哈!)
1 import sklearn 2 import numpy as np 3 import matplotlib 4 from matplotlib import pyplot as plt 5 import pandas as pd 6 %matplotlib inline 7 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] 8 from sklearn.preprocessing import LabelEncoder 9 from sklearn.model_selection import train_test_split 10 df = pd.read_csv('汽车.data',header=None) 11 dataset=df.values 12 # print(dataset) 13 # print(df.info()) 14 # print(df.head()) #6个特征,1个标签,都是object 15 encoder_list=[] #存放编码器 16 # print(dataset) 17 encoder_set=np.empty(dataset.shape) 18 # print(encoder_set) 19 for i in range(len(dataset[1])): 20 encoder=LabelEncoder() 21 encoder_set[:,i]=encoder.fit_transform(dataset[:,i]) 22 encoder_list.append(encoder) #将列编码器加入到列表中 23 #取出特征和标签,并将fload转int 24 print(encoder_set) 25 datasetX=encoder_set[:,:-1].astype(int) 26 datasetY=encoder_set[:,-1].astype(int) 27 train_X,test_X,train_Y,test_Y=train_test_split(datasetX,datasetY,test_size=0.2,random_state=9) 28 #构建随机森林 29 from sklearn.ensemble import RandomForestClassifier 30 rf_regressor=RandomForestClassifier(max_depth=8,n_estimators=200) 31 rf_regressor.fit(train_X,train_Y) 32 print(test_X) 33 predict_test_y=rf_regressor.predict(test_X) 34 35 #评分 36 from sklearn.model_selection import cross_val_score 37 def print_model_score(classifier,test_X,test_Y): 38 acc=cross_val_score(classifier,test_X,test_Y,scoring='accuracy',cv=6).mean() 39 pre=cross_val_score(classifier,test_X,test_Y,scoring='precision_weighted',cv=6).mean() 40 rec=cross_val_score(classifier,test_X,test_Y,scoring='recall_weighted',cv=6).mean() 41 f1=cross_val_score(classifier,test_X,test_Y,scoring='f1_weighted',cv=6).mean() 42 print('准确率:',acc,'精确率',pre,'召回率',rec,'F1',f1) 43 print_model_score(rf_regressor,test_X,test_Y) 44 #这里我们模型的分数就已经全部出来了
这里我们的书就已经求出来了

这里截图展示一下
现在我们开始进行优化
优化分为两种:
1、验证曲线(主要用于随机森林中对节支的限制,这里随机森林中有三个参数,这里我们因为要求的最优值是:n_estimators=,所有)
2、学习曲线(主要用于随机森林中对数据集的分割,数据集在什么位置分开是最合适的)
直接上代码:
#参数组合:验证曲线
#训集合大小:学习曲线
from sklearn.model_selection import validation_curve
vc_classifier = RandomForestClassifier(min_samples_split=50,random_state=9,max_depth=8)
#生成一组参数数
param_grid = np.linspace(start=100,stop=400,num=20).astype(int) #20,40,60,80
# print(param_grid)
#获取训练得分和验证得分
traint_score,validation_score=validation_curve(vc_classifier,train_X,train_Y,'n_estimators',param_grid,cv=6)
# print(traint_score)
plot_valid_curve(param_grid,traint_score,validation_score,'验证曲线','n_estimators 值','准确率')
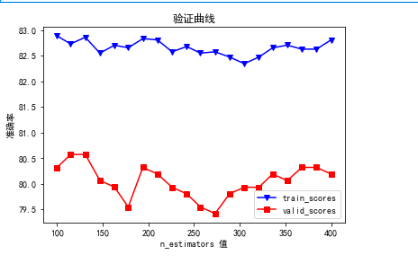
这里的红线,我们暂时不用看,首相看蓝线,我们看这条线时首相要明白,x轴越小,但是y轴要越大,这个点事自己挑的
随意的挑,但是一定要符合条件,就是x轴最小,但是y轴是最大的,就像这里,x轴为150的时候y轴最低,x轴为200的时候
y轴相对平稳,所以我们这里取值,200,也就是说,随机森林的树的个数是200,n_estimators=200是最优的模型
这是第一种优化方式,第二种方式:
学习曲线
上代码
1 from sklearn.model_selection import learning_curve 2 #初始化模型 3 lc_classifier = RandomForestClassifier(n_estimators=140,max_depth=10,random_state=9) 4 param_spilit=np.linspace(start=0.1,stop=0.9,num=10) 5 # print(param_spilit) 6 train_sizers,train_score,valid_score=learning_curve(lc_classifier,datasetX,datasetY,train_sizes=param_spilit,cv=6) 7 plot_valid_curve(param_spilit,train_score,valid_score,'学习曲线','训练集大小','模型得分') 8 9 #这里要得到的是分割的最优点在哪里
得到数据的截图:
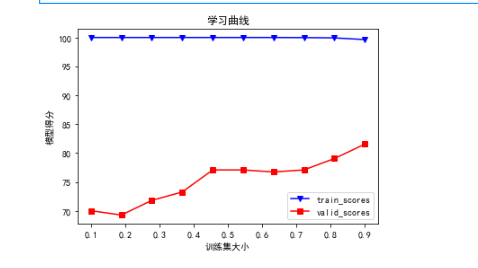
这里我们看红线,可以暂时理解蓝线为验证曲线的得分,红线为学习曲线的得分(应该不正确,欢迎大佬做出指导)
红线中我们还是那个理论,x轴越小,y轴要越大,但是相邻的点要比较平稳
这里我们选择的分割点为0.45,这是我们的最优点
那么我们最终的模型就得出来了,
1 train_X,test_X,train_Y,test_Y=train_test_split(datasetX,datasetY,test_size=0.55,random_state=9) #这里分割数据集是最优点,但是这里放的是预测集的份数,图中求的是训练集的份数所有需要1减去我们得的x轴的点 2 bast_classifier=RandomForestClassifier(n_estimators=200,random_state=9) 3 bast_classifier.fit(train_X,train_Y) 4 print_model_score(bast_classifier,test_X,test_Y) 5 6 7 8 #这里我们的模型就确定了,直接求分数
截图

这里明显分数上升了0.1个百分点,大功告成!