最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了。
1 看下猫眼电影的top100页面
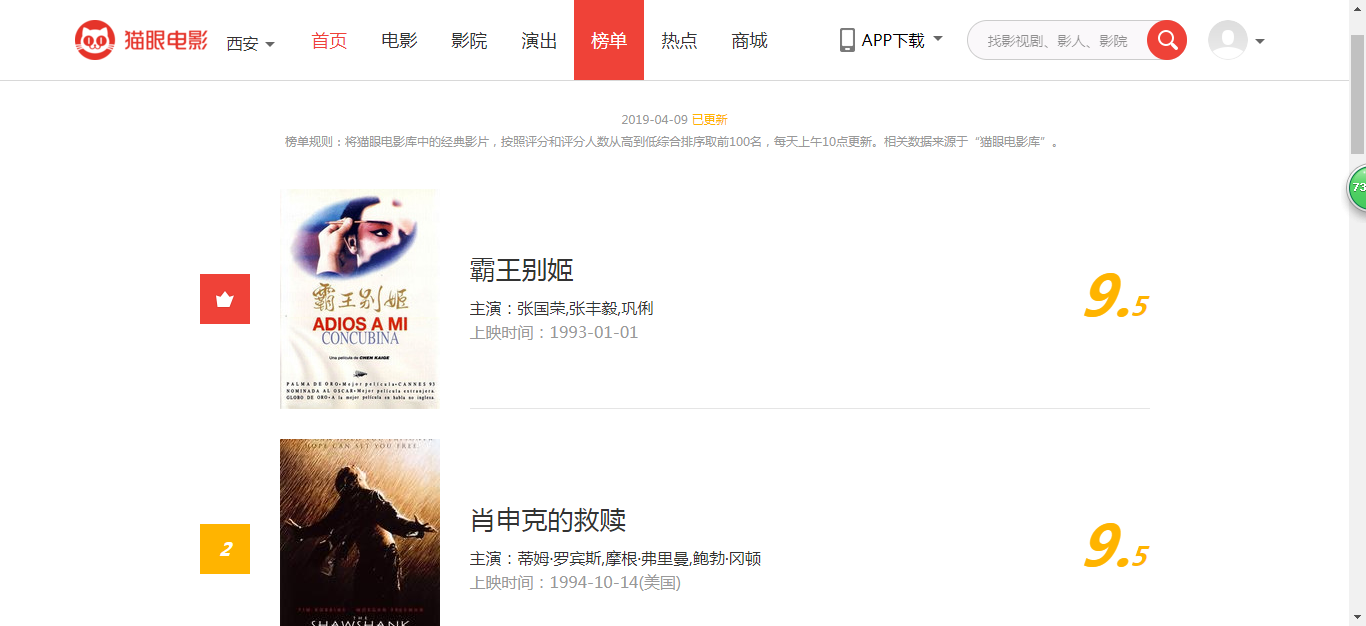
分了10页,url为:https://maoyan.com/board/4?offset=0
我们发起请求,得到相应:
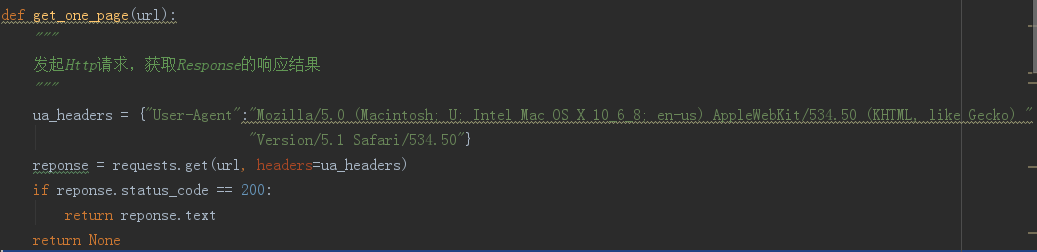 我们
我们
我使用的是requests库,这是一个第三方的库。
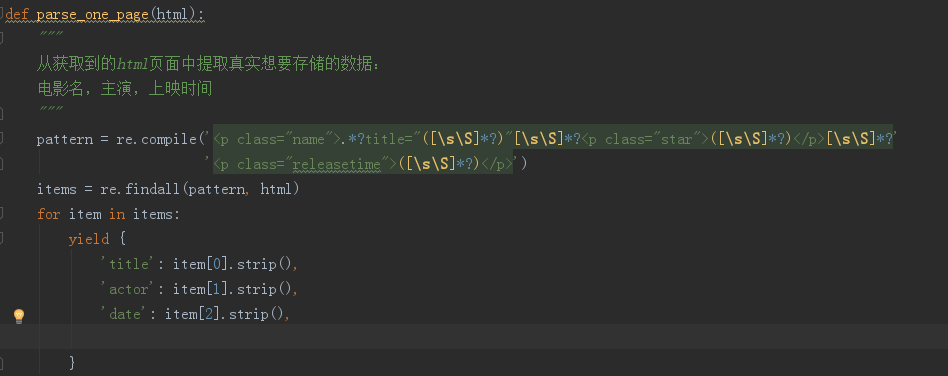
2 利用正则解析爬取下的页面
当然你也可以使用xpath和bs4。
我们先看一下网页的源代码:

然后根据代码写出要匹配的正则,然后对匹配出来的数据做解析:
3 将抓到的数据写入本地文件

4 最后得到的页面

5 一点小扩充
虽然实现了爬取的功能,但是其实这个程序还可以扩充
普通版:利用for循环实现爬取

多线程版:利用进程池创建多进程