爬取猫眼TOP100信息
1.目标:
使用python的requests库爬取猫眼电影TOP100的电影名称,上映时间,评分等信息,爬取的网站
为"https://maoyan.com/board/4",结果保存为文件形式
2.思路分析
首先打开"https://maoyan.com/board/4",可以看到结果如下图所示

可以看到,排名第一的电影是霸王别姬,并且可以看到主演,上映时间,评分等信息。
往下翻,我们可以观察到下面有分页的列表,并且每一页有10部电影的信息。让我们翻到下一页
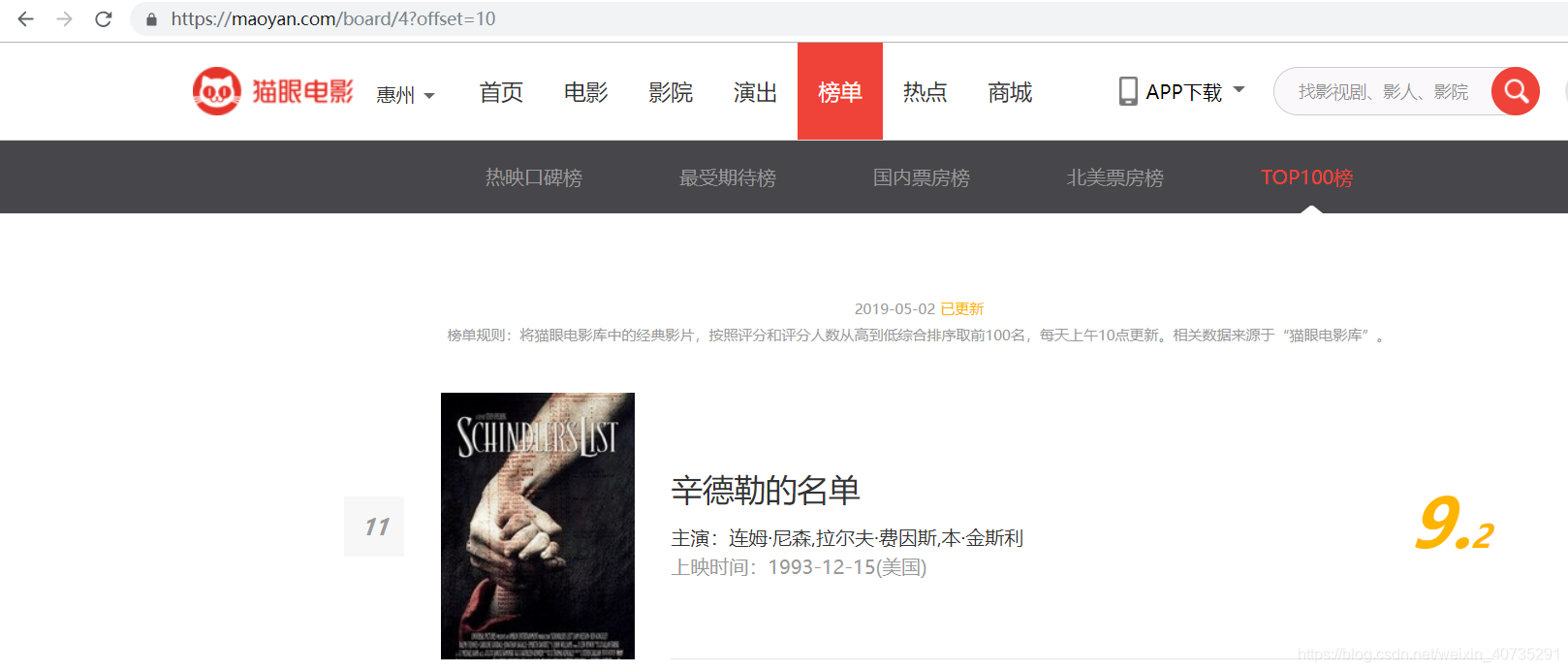
可以看到,在浏览器地址栏发生了变化,URL最后offset参数从0变成了10,再翻到下一页会发现offset变成了20,由此我们发现规律:每翻一页offset加10。
这样一来我们就得到了所有需要爬取的网页的URL,因此我们只用编写爬取其中一个页面的代码,再对全部的URL使用就可以爬取到所有信息了。
3.页面抓取
编写getPageText(base_url, params)函数获取某一url的text,其中params为URL的参数(在本文中是offset)
import requests
def getPageText(base_url, params):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400',
}
r = requests.get(base_url, params = params, headers = headers)
if r.status_code == 200:
return r.text
else:
return None
4.信息提取
在浏览器中点击右键->检查,或者使用F12进入控制台查看源代码。
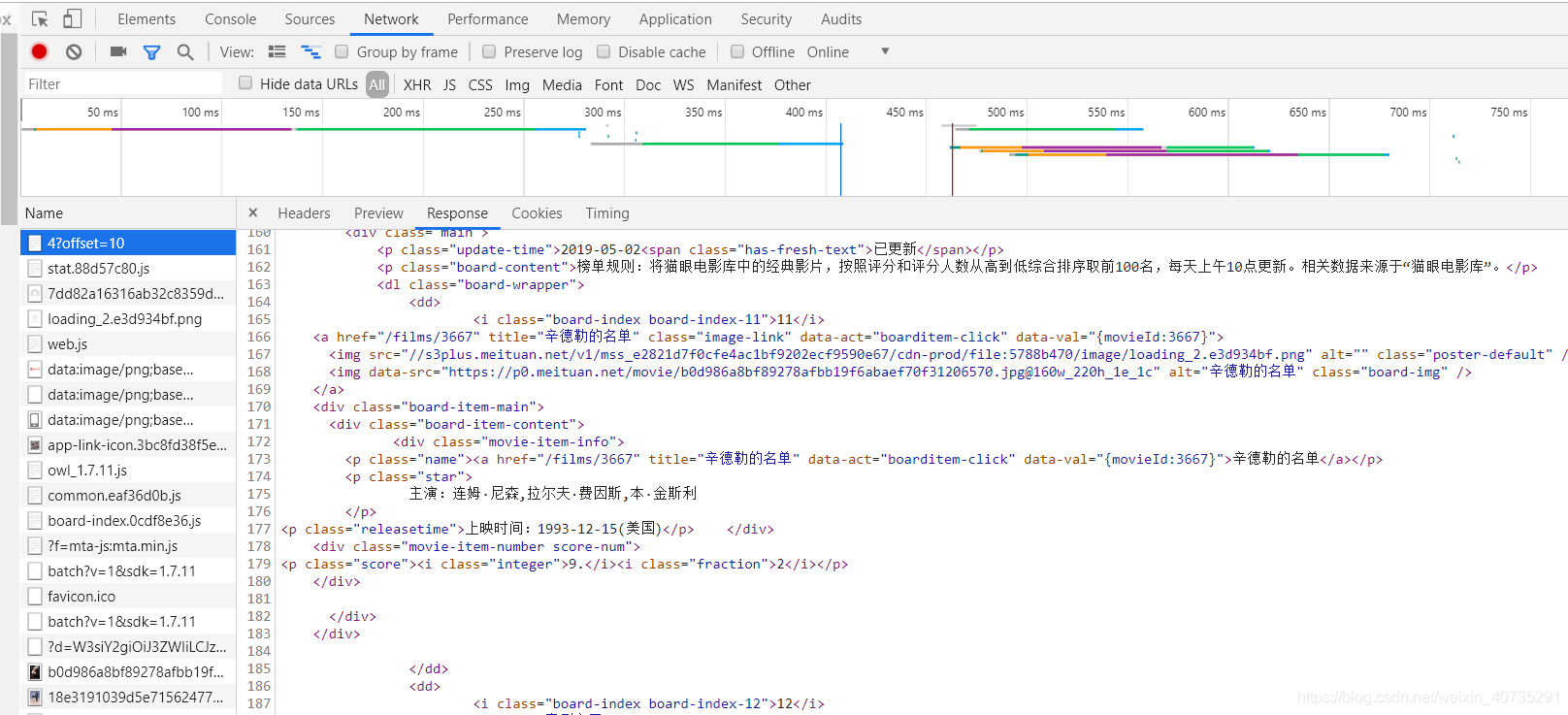
找到目标部分后,观察其结构,然后用正则表达式提取信息。因为爬取下来的HTML文本大多带有大量空白字符(不可见字符),因此我们先使用sub方法将文本中的空白字符替换为空字符串(即删除空格符)
import re
def fromTextGetData(text):
text = re.sub('[\s\n]+','', text)
pattern = re.compile(r'<pclass="name"><a[^>]*?>(.*?)</a></p><pclass="star">(.*?)</p>.*?<pclass="releasetime">(.*?)</p>', re.S)
score_pattern = re.compile(r'<iclass="integer">(.*?)</i><iclass="fraction">(.*?)</i></p>', re.S) #提取评分
temp_result = pattern.findall(text)
score_result = score_pattern.findall(text)
result = [None]*len(temp_result)
for i in range(0, len(temp_result)):
if (i < len(score_result)):
string = '分数:' + str(score_result[i][0] + score_result[i][1])
dic = {
#将结果存入字典中
'影片名字': temp_result[i][0],
'主演:':temp_result[i][1][3:],
'上映时间:':temp_result[i][2][5:],
'分数:':string[3:]
}
result[i] = dic
return result
5.写入文件
爬虫爬取的数据一般需要保存到本地,我们先将其保存为TXT文件
这里使用JSON库中的dumps()方法实现字典的序列化(将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式的过程称为序列化;反之,则称为反序列化)
因为json.dumps 序列化时对中文默认使用的ascii编码,因此需要使用ensure_ascii=False来指定出中文,这样可以保证输出结果是中文格式,而不是Unicode编码
json.dumps返回的类型是str类型
def writeToFile(filePath, content):
with open(filePath, 'a', encoding = 'utf-8') as f:
#print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii = False) + '\n')
6.代码整合
在main方法中调用其余函数,方便后续管理与拓展
def main():
base_url = 'https://maoyan.com/board/4'
offset = 0
result = []
for i in range(offset, 100, 10):
params = {
'offset':i
}
text = getPageText(base_url, params)
result += fromTextGetData(text)
print(result)
for i in result:
writeToFile('maoyan.txt', i)
7.完整代码
import requests
import json
import re
def getPageText(base_url, params):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400',
}
r = requests.get(base_url, params = params, headers = headers)
if r.status_code == 200:
return r.text
else:
return None
def fromTextGetData(text):
text = re.sub('[\s\n]+','', text)
pattern = re.compile(r'<pclass="name"><a[^>]*?>(.*?)</a></p><pclass="star">(.*?)</p>.*?<pclass="releasetime">(.*?)</p>', re.S)
score_pattern = re.compile(r'<iclass="integer">(.*?)</i><iclass="fraction">(.*?)</i></p>', re.S)
temp_result = pattern.findall(text)
score_result = score_pattern.findall(text)
result = [None]*len(temp_result)
for i in range(0, len(temp_result)):
if (i < len(score_result)):
string = '分数:' + str(score_result[i][0] + score_result[i][1])
dic = {
'影片名字': temp_result[i][0],
'主演:':temp_result[i][1][3:],
'上映时间:':temp_result[i][2][5:],
'分数:':string[3:]
}
result[i] = dic
return result
def writeToFile(filePath, content):
with open(filePath, 'a', encoding = 'utf-8') as f:
#print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii = False) + '\n')
def main():
base_url = 'https://maoyan.com/board/4'
offset = 0
result = []
for i in range(offset, 100, 10):
params = {
'offset':i
}
text = getPageText(base_url, params)
result += fromTextGetData(text)
print(result)
for i in result:
writeToFile('maoyan.txt', i)
if __name__ == '__main__':
main()