一、设计方案
1.主题式网络爬虫名称:爬取猫眼电影TOP100
2.爬取内容与数据特征分析:爬取猫眼电影TOP100榜单电影评分与出版年份..
3.设计方案概述、思路:首先打开目标网站,进行目标站点分析 打开猫眼电影 点击榜单 TOP100 每一页10个电影,通过URL offset参数改变电影的展示,然后进行网页代码分析 审查源代码,由dd标签包围,抓取单页内容,利用request请求目标站点,得到单个网页HTML代码,返回结果根据HTML代码分析得到电影的名称,主演,上映时间,评分,图片链接等信息、保存文件、开启循环及多线程....
难点:html源码过于杂乱,难以提取数据,数据实时更新,会导致部分上传的数据偏差
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:通过分析页面得知所要获取的数据分布于dd标签中,p为发行时间标签,i为影片评分标签。
2.Htmls页面解析:

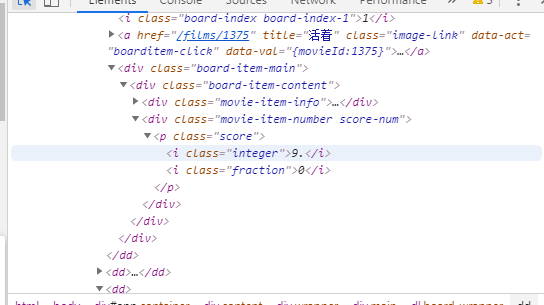
3.节点(标签)查找方法与遍历方法:通过re模块的findall方法进行查找。
三、网络爬虫程序设计
1.数据的爬取与采集
import requests
import bs4
import pandas as pd
def get_one_page(url):
# 设置头文件信息
#伪装爬虫
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' ,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '__mta=213236267.1587572266990.1587576183155.1587608996146.4; uuid_n_v=v1; uuid=CD3E8DF084B411EA92CE8B62796C19887B6E5F257E434EBFA5AFAA7C50986BB1; _csrf=d046dea14a42fa27a03f55d5df7be9fc2669e4f8e3f4e33ea42418cf07c04703; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1587572266; _lxsdk_cuid=171a2ae53b0c8-0824067bcb9761-366b420b-fa000-171a2ae53b1c8; _lxsdk=CD3E8DF084B411EA92CE8B62796C19887B6E5F257E434EBFA5AFAA7C50986BB1; mojo-uuid=0f40d6f281ba65600ee90a8fb913b7ac; t_lxid=171a2ae579fc8-0428f77e331d8b-366b420b-fa000-171a2ae579fc8-tid; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1587608996; _lxsdk_s=171a580f996-9c1-c73-c3f%7C%7C1',
'Host': 'maoyan.com',
'Upgrade-Insecure-Requests': '1'
}
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
response.encoding = response.apparent_encoding
return response.text
except :
return None
#解析网页
def get_soup(htm):
soup = bs4.BeautifulSoup(htm,'html.parser')
return soup
#找到电影名
def find_name(soup):
x=soup.find_all('p',class_="name")
n=[]
for i in x:
n.append(i.text)
return n
#找到电影上映时间
def get_time(soup):
x=soup.find_all('p',class_="releasetime")
n=[]
for i in x:
n.append(i.text)
return n
#找到电影评分
def get_score(soup):
x=soup.find_all('p',class_="score")
n=[]
for i in x:
n.append(i.text)
return n
def main():
url='https://maoyan.com/board/4?'
html = get_one_page(url)
#print(html)
soup = get_soup(html)
#print(soup)
#电影名
name = find_name(soup)
'''for i in name:
print(i)'''
#上映时间
time = get_time(soup)
'''for i in time:
print(i)'''
#评分
score = get_score(soup)
'''for i in score:
print(i)'''
#保存excel文件
df = pd.DataFrame({'电影名':name,'上映时间':time,'评分':score})
df.to_excel('猫眼电影.xlsx')
if __name__=='__main__':
main()
抓取的单页内容:



2.对数据进行清洗和处理
#读取csv文件
df = pd.DataFrame(pd.read_excel('猫眼电影.xlsx'))
df.head()

#缺失值处理 df.isnull().head() #True为缺失值,False为存在值

#空值处理# df.isnull().sum() #0表示无空值

#查找重复值 df.duplicated() #显示表示已经删除重复值
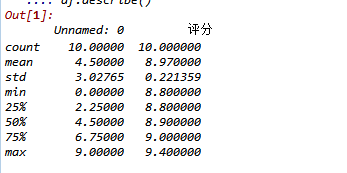
#查看统计信息 df.describe()
4.数据分析与可视化
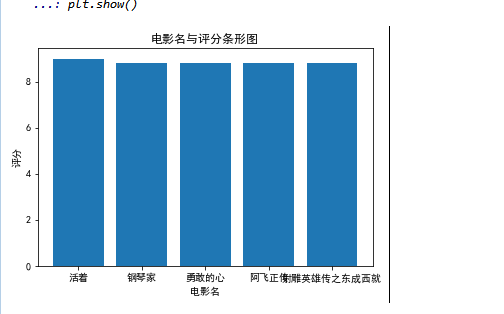
条形图
#绘制条形图
df = pd.read_excel('猫眼电影.xlsx')
x = df['电影名'][:5]
y = df['评分'][:5]
plt.xlabel('电影名')
plt.ylabel('评分')
plt.bar(x,y)
plt.title("电影名与评分条形图")
plt.show()
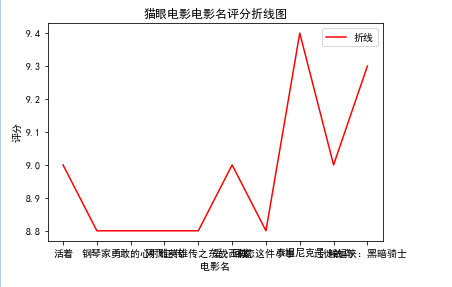
#绘制折线图
df = pd.read_excel('猫眼电影.xlsx')
x = df['电影名'][:10]
y = df['评分'][:10]
plt.xlabel('电影名')
plt.ylabel('评分')
plt.plot(x,y,color="red",label="折线")
plt.title("猫眼电影电影名评分折线图")
plt.legend()
plt.show()
散点图
df = pd.DataFrame(pd.read_excel('猫眼电影.xlsx'))
x = df['上映时间'][:1]
y = df['评分'][:10]
sns.lmplot(x="上映时间",y= "评分",data=df)
p0=[0,0,0]
Para=leastsq(error_func,p0,args=(q,w))
a,b,c=Para[0]
plt.figure(figsize=(6,3))
plt.scatter(q,w,color="grenn",label=u"最高评分散点",linewidth=2)
x=np.linspace(0,20,15)
y=a*x*x+b*x+c
plt.plot(x,y,color="green",label=u"回归方程曲线",linewidth=2)
plt.xlabel("电影名")[:10]
plt.ylabel("最高评分")[:10]
plt.title("猫眼电影回归曲线图")
plt.legend()
plt.show()

代码汇总:
import requests
import bs4
import pandas as pd
import seaborn as sns
import numpy as np
from numpy import genfromtxt
import scipy as sp
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
def get_one_page(url):
# 设置头文件信息
#伪装
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' ,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '__mta=213236267.1587572266990.1587576183155.1587608996146.4; uuid_n_v=v1; uuid=CD3E8DF084B411EA92CE8B62796C19887B6E5F257E434EBFA5AFAA7C50986BB1; _csrf=d046dea14a42fa27a03f55d5df7be9fc2669e4f8e3f4e33ea42418cf07c04703; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1587572266; _lxsdk_cuid=171a2ae53b0c8-0824067bcb9761-366b420b-fa000-171a2ae53b1c8; _lxsdk=CD3E8DF084B411EA92CE8B62796C19887B6E5F257E434EBFA5AFAA7C50986BB1; mojo-uuid=0f40d6f281ba65600ee90a8fb913b7ac; t_lxid=171a2ae579fc8-0428f77e331d8b-366b420b-fa000-171a2ae579fc8-tid; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1587608996; _lxsdk_s=171a580f996-9c1-c73-c3f%7C%7C1',
'Host': 'maoyan.com',
'Upgrade-Insecure-Requests': '1'
}
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
response.encoding = response.apparent_encoding
return response.text
except :
return None
#解析网页
def get_soup(htm):
soup = bs4.BeautifulSoup(htm,'html.parser')
return soup
#找到电影名
def find_name(soup):
x=soup.find_all('p',class_="name")
n=[]
for i in x:
n.append(i.text)
return n
#找到电影上映时间
def get_time(soup):
x=soup.find_all('p',class_="releasetime")
n=[]
for i in x:
n.append(i.text)
return n
#找到电影评分
def get_score(soup):
x=soup.find_all('p',class_="score")
n=[]
for i in x:
n.append(i.text)
return n
def main():
url='https://maoyan.com/board/4?'
html = get_one_page(url)
#print(html)
soup = get_soup(html)
#print(soup)
#电影名
name = find_name(soup)
'''for i in name:
print(i)'''
#上映时间
time = get_time(soup)
'''for i in time:
print(i)'''
#评分
score = get_score(soup)
'''for i in score:
print(i)'''
#排名
#保存excel文件
df = pd.DataFrame({'电影名':name,'上映时间':time,'评分':score})
df.to_excel('猫眼电影.xlsx')
if __name__=='__main__':
main()
df = pd.DataFrame(pd.read_excel('猫眼电影.xlsx'))
df.head()
#缺失值处理 df.isnull().head() #True为缺失值,False为存在值 #空值处理# df.isnull().sum() #0表示无空值 #查找重复值 df.duplicated() #显示表示已经删除重复值 #查看统计信息 df.describe()
#绘制条形图
df = pd.read_excel('猫眼电影.xlsx')
x = df['电影名'][:5]
y = df['评分'][:5]
plt.xlabel('电影名')
plt.ylabel('评分')
plt.bar(x,y)
plt.title("电影名与评分条形图")
plt.show()
#绘制折线图
df = pd.read_excel('猫眼电影.xlsx')
x = df['电影名'][:10]
y = df['评分'][:10]
plt.xlabel('电影名')
plt.ylabel('评分')
plt.plot(x,y,color="red",label="折线")
plt.title("猫眼电影电影名评分折线图")
plt.legend()
plt.show()
df = pd.DataFrame(pd.read_excel('猫眼电影.xlsx'))
x = df['上映时间'][:1]
y = df['评分'][:10]
sns.lmplot(x="上映时间",y= "评分",data=df)
df = pd.DataFrame(pd.read_csv('E:/华北天气数据.csv'))
q = df['地点']
w = df['最高温度']
def func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return func(p,x)-y
p0=[0,0,0]
Para=leastsq(error_func,p0,args=(q,w))
a,b,c=Para[0]
plt.figure(figsize=(6,3))
plt.scatter(q,w,color="grenn",label=u"最高评分散点",linewidth=2)
x=np.linspace(0,20,15)
y=a*x*x+b*x+c
plt.plot(x,y,color="green",label=u"回归方程曲线",linewidth=2)
plt.xlabel("电影名")[:10]
plt.ylabel("最高评分")[:10]
plt.title("猫眼电影回归曲线图")
plt.legend()
plt.show()
1.经过对主题数据的分析与可视化,可以得到哪些结论?
可以更直观的发现和解决需求,大量数据一目了然,喜欢追求电影质量的可以更直接的观看高评分电影,如果需要查找影片也可以更快的从分析与可视化完的数据中查找,也更方便迅捷。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次程序设计任务完成时间较久,也是对python的不熟悉,但是随着这次的作业的完成,更熟识了许多库与语法,对自己有较大的提升,尽管还是有很多语法错误与不完整的地方,但是我相信一步一个脚印总会有收获的!