近期接触了一个需求,业务背景是需要将关系型数据库的数据传输至HDFS进行计算,计算完成后再将计算结果传输回关系型数据库。听到这个背景,脑海中就蹦出了Sqoop迁移工具,可以非常完美的支持上述场景。
当然,数据传输工具还有很多,例如Datax、Kettle等等,大家可以针对自己的工作场景选择适合自己的迁移工具。
目录
一、介绍
二、架构
三、安装
1. 下载Sqoop
2. 配置环境变量
四、操作
1. 列出数据库
2. 列出数据表
3. MySQL导入到HDFS
4. HDFS导出到MySQL
一、介绍
Sqoop的命名,仔细一看是不是有点像 sql 和 hadoop 两个词语的拼接产物。其实从它的命名来看也就很明显,Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
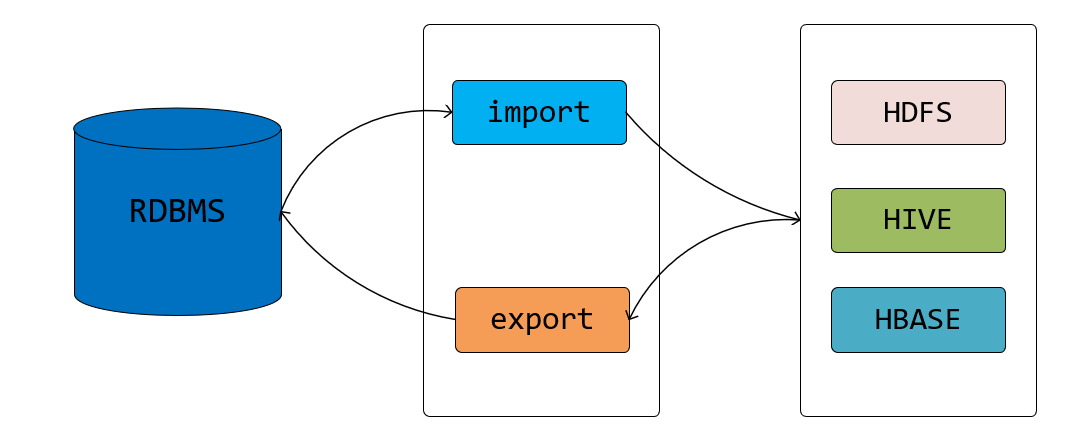
从关系型数据库到 hadoop 我们称之为 import,从 hadoop 到关系型数据库我们称之为 export。文章后面大家就会看到 "import"、"export" 对应命令的两个模式。
二、架构
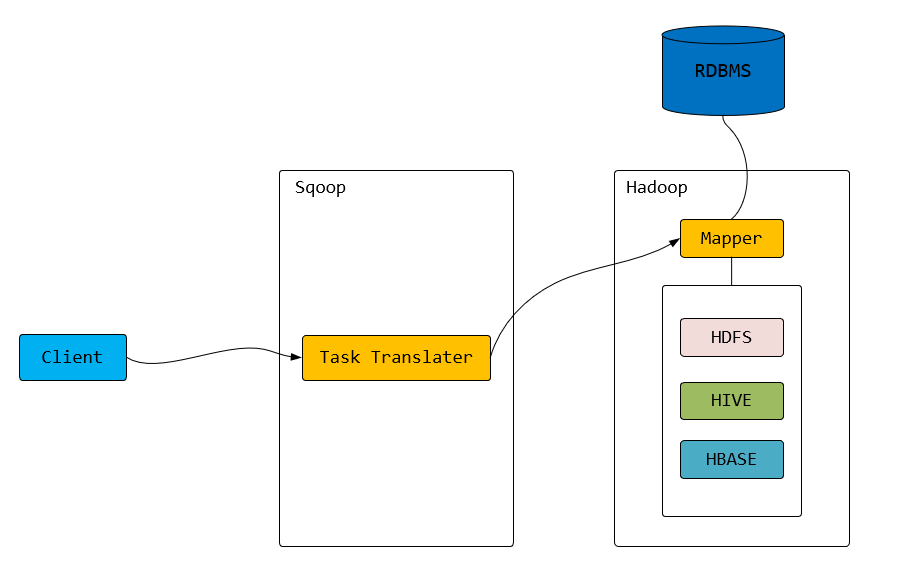
三、安装
1. 下载Sqoop
Sqoop安装包可以从官网下载:http://sqoop.apache.org/
从官网可以看到,Sqoop有两个大的版本:Sqoop1和Sqoop2。
1.4.x 的为 Sqoop1,1.99.X 为 Sqoop2。
关于 Sqoop1 与 Sqoop2 的区别,通俗来讲就是:
- sqoop1 只是一个客户端工具,Sqoop2 加入了 Server 来集中化管理连接器
- Sqoop1 通过命令行来工作,工作方式单一,Sqoop2 则有更多的方式来工作,比如 REST api接口、Web 页
- Sqoop2 加入权限安全机制
对于笔者来说,Sqoop 就是一个同步工具,命令行足够满足工作需求,并且大部分数据同步都是在同一个局域网内部(也就没有数据安全之类问题),所以选择的是 Sqoop1(具体版本是 1.4.7)。
下载好了之后,在你想安装的路径下进行解压, 这里选择将Hadoop 安装到当前路径下:
# tar xvzf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz # mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
2. 配置环境变量
# vi /etc/profile export SQOOP_HOME=/root/sqoop export PATH=$PATH:$SQOOP_HOME/bin
使得sqoop命令在当前终端立即生效
# source /etc/profile
配置好环境变量后,将数据库连接驱动放入 $SQOOP_HOME/lib 目录中。这里使用的是MySQL数据库,选择的MySQL连接驱动mysql-connector-java-5.1.46.jar ,当然,如果你使用的是其他关系型数据库,相应的就需要导入其他关系型数据库的jar包。
四、操作
了解了 Sqoop 是什么,能做什么以及大概的框架原理,接下来我们直接使用 Sqoop 命令来感受一下使用 Sqoop 是如何简单及有效。本文案例中的关系型数据库使用的是 MySQL,Oracle 以及其他使用 jdbc 连接的关系型数据库操作类似,差别不大。
运行 sqoop help 可以看到 Sqoop 提供了哪些操作
# sqoop help 19/04/09 22:37:04 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command.
这些操作其实都会一一对应到 sqoop bin 目录下的一个个可运行脚本文件,如果想了解细节,可以打开这些脚本进行查看
# ll bin/ total 96 drwxr-xr-x 2 1000 1000 4096 Dec 19 2017 ./ drwxr-xr-x 9 1000 1000 4096 Dec 19 2017 ../ -rwxr-xr-x 1 1000 1000 6770 Dec 19 2017 configure-sqoop* -rwxr-xr-x 1 1000 1000 6533 Dec 19 2017 configure-sqoop.cmd* -rwxr-xr-x 1 1000 1000 3133 Dec 19 2017 sqoop* -rwxr-xr-x 1 1000 1000 1055 Dec 19 2017 sqoop.cmd* -rwxr-xr-x 1 1000 1000 3060 Dec 19 2017 sqoop-codegen* -rwxr-xr-x 1 1000 1000 3070 Dec 19 2017 sqoop-create-hive-table* -rwxr-xr-x 1 1000 1000 3057 Dec 19 2017 sqoop-eval* -rwxr-xr-x 1 1000 1000 3059 Dec 19 2017 sqoop-export* -rwxr-xr-x 1 1000 1000 3057 Dec 19 2017 sqoop-help* -rwxr-xr-x 1 1000 1000 3059 Dec 19 2017 sqoop-import* -rwxr-xr-x 1 1000 1000 3070 Dec 19 2017 sqoop-import-all-tables* -rwxr-xr-x 1 1000 1000 3069 Dec 19 2017 sqoop-import-mainframe* -rwxr-xr-x 1 1000 1000 3056 Dec 19 2017 sqoop-job* -rwxr-xr-x 1 1000 1000 3067 Dec 19 2017 sqoop-list-databases* -rwxr-xr-x 1 1000 1000 3064 Dec 19 2017 sqoop-list-tables* -rwxr-xr-x 1 1000 1000 3058 Dec 19 2017 sqoop-merge* -rwxr-xr-x 1 1000 1000 3062 Dec 19 2017 sqoop-metastore* -rwxr-xr-x 1 1000 1000 3060 Dec 19 2017 sqoop-version* -rwxr-xr-x 1 1000 1000 3987 Dec 19 2017 start-metastore.sh* -rwxr-xr-x 1 1000 1000 1564 Dec 19 2017 stop-metastore.sh*
工作中一般常用的几个操作或者命令如下:
- list-databases : 查看有哪些数据库
- list-tables : 查看数据库中有哪些表
- import : 关系型数据库到 hadoop 数据同步
- export : hadoop 到关系型数据库数据同步
- version :查看 Sqoop 版本
1. 列出数据库
# sqoop list-databases --connect jdbc:mysql://192.168.1.123:3306/?useSSL=false --username root --password 12345678
2. 列出数据表
# sqoop list-databases --connect jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false --username root --password 12345678
3. MySQL导入HDFS
# sqoop import --connect jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false --username root --password 12345678 --table product --target-dir /hadoopDir/ --fields-terminalted-by '\t' -m 1 --columns 'PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME' --last-value num --incremental append
--where 'QUANTITY > 500'
| 选项 | 说明 |
| --connect | 数据库的 JDBC URL,后面的 databasename 想要连接的数据库名称 |
| --table | 数据库表 |
| --username | 数据库用户名 |
| --password | 数据库密码 |
| --target-dir | HDFS 目标目录,不指定,默认和数据库表名一样 |
| --fields-terminated-by | 数据导入后每个字段之间的分隔符,不指定,默认为逗号 |
| -m | mapper 的并发数量 |
| --columns | 指定导入时的参考列,这里是PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME |
| --last-value | 上一次导入的最后一个值 |
| --incremental append | 导入方式为增量 |
| --where | 按条件筛选数据,where条件的内容必须在单引号内 |
注意:工作中需要增量同步的场景下,我们就可以使用 --incremental append 以及 --last-value。比如这里我们使用 id 来作为参考列,如果上次同步到了 1000, 这次我们想只同步新的数据,就可以带上参数 --last-value 1000。
4. HDFS导出MySQL
# sqoop export --connect 'jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false&useUnicode=true&characterEncoding=utf-8' --username root --password '12345678' --table product --m 1 --export-dir /hadoopDir/ --input-fields-terminated-by '\t' --columns 'PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME'
HDFS导出到MySQL时,数据有可能乱码,此时需要在--connect参数中指定编码。
Mysql 与 hadoop 数据同步(迁移),你需要知道 Sqoop