看这篇https://blog.csdn.net/qq_16234613/article/details/80268564
1、DQN
原因:在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。
通常做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。如下式,通过更新参数 θ 使Q函数逼近最优Q值 。
Q(s,a;θ)≈Q′(s,a)
而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络最合适不过了。
DRL是将深度学习(DL)与强化学习(RL)结合,直接从高维原始数据学习控制策略。而DQN是DRL的其中一种算法,它要做的就是将卷积神经网络(CNN)和Q-Learning结合起来,CNN的输入是原始图像数据(作为状态State),输出则是每个动作Action对应的价值评估Value Function(Q值)。
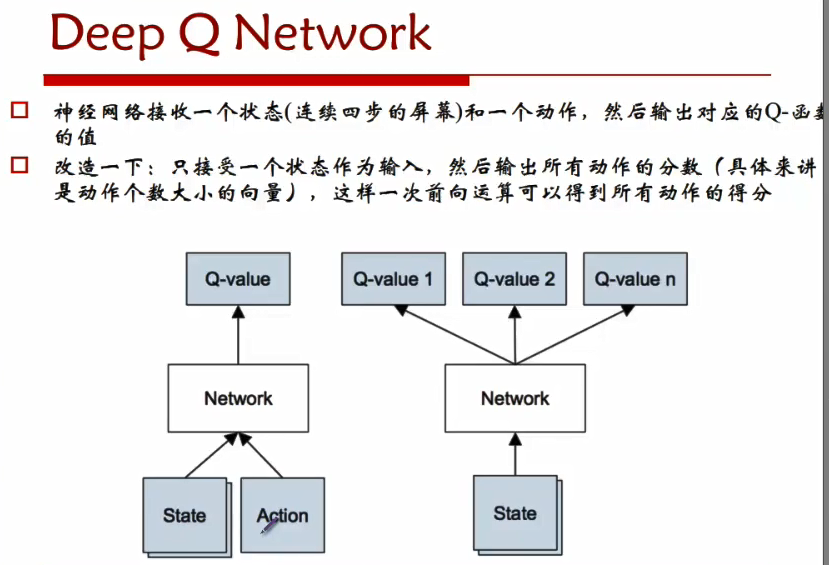
2、模型:

3、算法
2013版

2015版


其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降。 他根据每次更新所参与样本量的不同把更新方法分为增量法(Incremental Methods)和批处理法(Batch Methods)。前者是来一个数据就更新一次,后者是先攒一堆样本,再从中采样一部分拿来更新Q网络,称之为“经验回放”,实际上DeepMind提出的DQN就是采用了经验回放的方法。为什么要采用经验回放的方法?因为对神经网络进行训练时,假设样本是独立同分布的。而通过强化学习采集到的数据之间存在着关联性,利用这些数据进行顺序训练,神经网络当然不稳定。经验回放可以打破数据间的关联。
另外,为了保证算法稳定收敛,还使用了经验回放(experience replay)技术。所谓 t 时刻的经验 e_t ,就是 t 时刻的观测、行为、奖励和 t+1 时刻的观测集合。
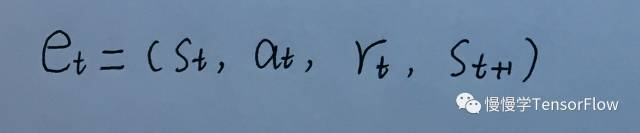
将时刻 1 到 t 所有经验都存储到 Dt 中,称为回放记忆(replay memory)。
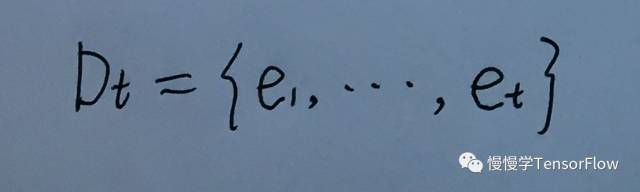
每次迭代,会从 D 中均匀采样得到一组经验,对当前权值使用 SGD 算法进行更新。这样避免了使用相邻经验的过度耦合(游戏中相邻几帧的观测都是非常近似的,容易造成训练发散)。训练 Q 网络时,输入(s, a) 变为序列输入
(s1, a1), (s2, a2), ..., (sn, an)。
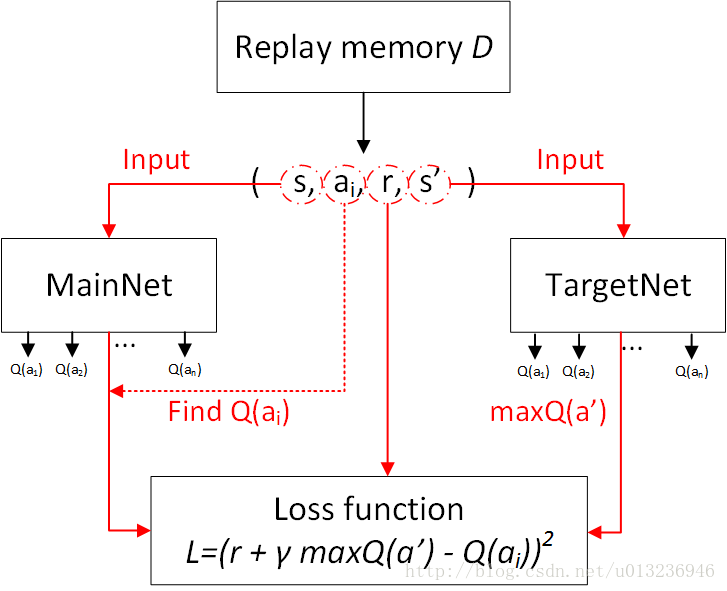
主要流程图:

损失函数的构造: