一、目标
在上一篇博客中,利用RFM模型,使用Kmeans算法,把客户分成了三类,并打好标签,生成了带标签的训练数据。接下来利用这些打好标签的分类数据,使用深度学习和机器学习方法对未打标签的客户进行分类。
环境:
python3.5
机器学习:随机森林
深度学习:基于TensorFlow的TFlearn,这个用起来跟sklearn比较相似
二、数据采集和分析
代码
import numpy as np
import tflearn
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier as RFC
import pymssql
import pandas as pd
#连接数据库
def get_db_connection():
host = 'xx'
port = 1433
user = 'sa'
password = 'xx'
database = 'xx'
conn = pymssql.connect(host=host,user=user,password=password,database=database,charset="utf8")
print('数据库连接成功')
return conn
#查询SQL结果并生成excel
def get_rawdata(conn):
sql= '''select top 10000 MEMBER_CODE,datediff(day,max(dob),'2018-12-31')as R,count(1) as F,sum(sales) as M
from xx
where dob between '2018-10-01' and '2018-12-31'
and MEMBER_CODE is not null
group by MEMBER_CODE'''
#直接使用pandas的read_sql即可转化成DataFrame
df=pd.read_sql(sql,conn)
df.to_excel('raw_data.xlsx')
return df
# 数据预处理
data =pd.read_excel('data_with_labor.xlsx')
x = data.iloc[:,1:4]
y = data.Labor
X=x.values #把x从DataFrame转换成array
y = y.values.reshape(10000, 1) #把y也转换成一万行的array
y = OneHotEncoder().fit_transform(y).toarray() #把标签转成独热码
Y=np.delete(y,[0],axis=1)#为了避免虚拟变量陷进,把y第一列删除。比如前两个数字是0,肯定知道第三个数字是1,真正有用信息只有2列
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1) # random_state表示随机种子
x_train = StandardScaler().fit_transform(x_train) #对x进行标准化
x_test = StandardScaler().fit_transform(x_test)
#随机森林结果
# clf=DTC().fit(x_train,y_train)#决策树
clf = RFC(n_estimators=50).fit(x_train, y_train) # 随机森林
result = classification_report(y_test, clf.predict(x_test))
print(result)
#深度学习结果
net = tflearn.input_data(shape=[None, 3]) # 输入层,有3个特征
net = tflearn.fully_connected(net, 6, activation='relu') # 隐藏层1
net = tflearn.fully_connected(net, 6, activation='relu') # 隐藏层2
net = tflearn.fully_connected(net, 6, activation='relu') # 隐藏层3
net = tflearn.fully_connected(net, n_units=3, activation='softmax') # 输出层3表示输出单元
net = tflearn.regression(net)
model = tflearn.DNN(net)
model.fit(x_train, y_train, n_epoch=30, batch_size=32,
show_metric=True) # n_epoch:数据训练几个轮次batch_size:每一次输入给模型的数据行数show_metric:训练过程中要不要打印结果
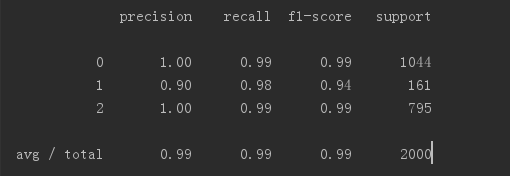
先来看看随机森林的结果:
可以发现准确率已经达到99%,这个是相当不错的结果了
接着看看深度学习的结果,可以看到loss大概是0.15左右,准确率为91.55%:

从这里来看,似乎传统的机器学习结果要好于深度学习的结果。这个估计跟数据量、模型使用范围关系比较大。
接下来利用TensorBoard可视化界面在看看结果:
在cmd中切换到log文件的上一层,然后输入:
tensorboard --logdir=log --host=127.0.0.1 --port=5022
host和端口自己随便指定
在浏览器输入http://127.0.0.1:5022/#scalars
可以看到数据可视化的图了,这是训练过程中的可视化,可以看到准确率在提升,Loss在降低。

切换到Graph界面,可以看到神经网络的结构图形。

有的人可能会遇到报错,tensorboard提示拒绝了我们的连接请求(指定host和端口或者换浏览器即可)
或者Tensorboard图片无法显示问题:
No dashboards are active for the current data set.
Probable causes:
- You haven’t written any data to your event files.
- TensorBoard can’t find your event files.
未完待续这个是因为没有找到日志文件导致的,记录,要放到文件的上一层,比如你当前日志的文件路径是
D:\log\events.out.tfevents.1552880407.EDZ-20180702DQV

那么你在cmd中只需要切换到D盘即可,如下图。
