一、背景和目标
随着大数据时代的到来,很多公司都建立了数据仓库,对分散在各处的数据进行收集,这只是解决了数据应用中的数据孤岛问题,但是不知道如何对数据进行使用。博主打算利用经典的RFM模型来挖掘数据,对某连锁餐饮行业客户进行分类,分成高价值客户、一般价值客户和普通价值客户,方便针对不同客户制定不同的营销策略
利用的工具:
1.Python3.5
2.SQL Server2014
3.Tableau
二、数据采集和处理
1.从数据库采集所需数据
采集模型中所需要的数据:
消费日期:R=观测结束日期-最后消费日期,单位为天
消费频率:观测窗口设置为最近三个月,单位为次
消费金额:客户的消费总金额
因为我直接从数据库获取的数据是很干净的数据,所以不会存在缺失、重复值,也不会有很大的数据差异,不需要进行清洗和规约。直接使用Python的Pandas从数据库获取数据,因为我电脑配置不高,所以就先选了一万条数据。:
import pymssql
import pandas as pd
import time
#连接数据库
def get_db_connection():
host = 'xxx'
port = 1433
user = 'sa'
password = 'xxx'
database = 'xxx'
conn = pymssql.connect(host=host,user=user,password=password,database=database,charset="utf8")
print('数据库连接成功')
return conn
#查询SQL结果并生成DataFrame
def get_df():
sql= '''select top 10000 MEMBER_CODE,datediff(day,max(dob),'2019-03-15')as R,count(1) as F,sum(sales) as M
from xxxx
where dob between '2019-01-01' and '2019-03-15'
and MEMBER_CODE is not null
group by MEMBER_CODE'''
conn=get_db_connection()
#直接使用pandas的read_sql即可转化成DataFrame
df=pd.read_sql(sql,conn)
print(df.head())
# columns=[column=cur.description[i][0] for i in range(len(column=cur.description))] #利用光标获得列名
if __name__ == '__main__':
get_df()
获取到的数据是这样的:
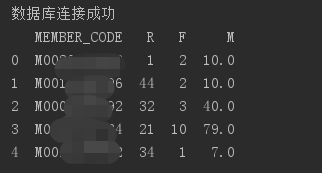
2.为了避免数据量级对结果产生影响,对采集的数据进行变换。这里采用的数据变换方法是标准化
def get_std_data():
df=get_df().iloc[:,1:]#会员号是str类型,去掉会员号才可以标准化
std_data=(df-df.mean(axis=0))/df.std(axis=0)
print(std_data.head())变换万之后的数据是这样的:
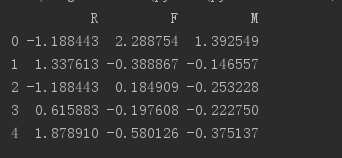
三、建模分析
采用K-Means对客户进行聚类分析,分成三类:高价值客户、一般价值客户和普通价值客户。
def get_result():
data=get_std_data()
model=KMeans(n_clusters=3,n_jobs=4)
model.fit(data)
print(model.cluster_centers_)#查看聚类中心
print(model.labels_)#查看个样本对应标签
结果:

四、报告和总结
客户群1在F和M的属性最大,在R的属性最小,说明该客户群经常购买公司的产品,并且很频繁,是优质客户。这一类客户贡献了公司很大的销售额,需要重点保持,优先把资源用在这一部分客户。
客户群2在M和F的属性稍微大点,在R属性最小,说明该客户群也是经常购买产品的,只是频率没那么高,属于一般价值客户。这一类客户消费近期有消费,需要提高他们的购买频率,就有可能成为优质的客户。
客户群3在R属性最大,在M属性最小,说明这个客户很久才购买一次,而且每次买东西也不贵,属于普通价值客户。
简单分析之后,把标签放回原来的数据源,保存成Excel,可以作为训练数据,接下来可以利用这些带标签的数据进行分类。

完整代码:
import pymssql
import pandas as pd
from sklearn.cluster import KMeans
#连接数据库
def get_db_connection():
host = 'xxx'
port = 1433
user = 'sa'
password = 'xxxx'
database = 'xxxx'
conn = pymssql.connect(host=host,user=user,password=password,database=database,charset="utf8")
print('数据库连接成功')
return conn
#查询SQL结果并生成DataFrame
def get_df(conn):
sql= '''select top 10000 MEMBER_CODE,datediff(day,max(dob),'2019-03-15')as R,count(1) as F,sum(sales) as M
from xxxx
where dob between '2019-01-01' and '2019-03-15'
and MEMBER_CODE is not null
group by MEMBER_CODE'''
#直接使用pandas的read_sql即可转化成DataFrame
df=pd.read_sql(sql,conn)
return df
# columns=[column=cur.description[i][0] for i in range(len(column=cur.description))] #利用光标获得列名
def get_std_data(df):
df=df.iloc[:,1:]#去掉会员号才可以标准化
std_data=(df-df.mean(axis=0))/df.std(axis=0)
return std_data
def get_result(data,df):
model=KMeans(n_clusters=3,n_jobs=4)
model.fit(data)
print(model.cluster_centers_)#查看聚类中心
#把便签放回数据源,这样就可以把会员进行分类了
df1=pd.DataFrame(list(model.labels_),columns=['Labor'])
DF=pd.merge(df,df1,how='inner',left_index=True,right_index=True)
DF.to_excel('data_with_labor.xlsx')
print(DF.head())
if __name__ == '__main__':
conn=get_db_connection()
df=get_df(conn)
data=get_std_data(df)
result=get_result(data,df)