
随着技术进步,尤其是地理信息系统 (GIS)工具的进步,可以更有效地对土地利用进行分类。分类的使用可用于识别植被覆盖变化、非法采矿区和植被抑制区域,这些只是土地利用分类的众多示例中的一部分。
分类的一大困难是确定要解决的问题的级别。我分类的目的是什么?分类是否需要具有高精度以减少对人工交互进行校正的需要?分类的目的只是为了识别随时间的变化吗?是否会使用机器学习分类来减轻地理团队的工作量?只有免费图片才能解决我的问题?
简要介绍这项工作中使用的两种学习类型,机器学习和深度学习有什么区别?
机器学习是机器学习的一种形式,是人工智能 (AI) 领域的一个子集,它使系统能够向操作员学习。这个学习领域使用数据来训练和找到准确的结果。
深度学习 或深度学习已经是机器学习的一个子集,模型将从更复杂的神经网络中学习。算法的创建就像机器学习一样,但包含更复杂的层次和更强大的计算能力。
理解这种差异的一种更简单的方法是,机器学习更依赖于人为干预进行学习,而深度学习则不依赖于人为干预。根据 Lex Fridman 的说法,深度学习是一种“更具可扩展性的机器学习” 。
第一种方法是使用机器学习技术进行分类,在这种分类中可以使用两种类型的方法,例如无监督或监督,并联合使用,称为混合分类。
假设类的数量和迭代次数给定,算法能够识别类的无监督方法。这种分类通常由称为聚类的分组方法使用。
监督方法需要一个运算符,该运算符将从图像中创建样本并表示要分类的每个类。关于这项工作,我选择仅使用监督方法进行机器学习。
这项工作的第一阶段是使用Earth Explorer平台下载Sentinel-2A图像。下载图像后,我将 4 个感兴趣的波段导出到 ArcGIS,蓝色 (B2)、绿色 (B3)、红色 (B4) 和红外 (B8) 波段。在条带之间进行假色合成 (8,4,3),并使用感兴趣区域 (ROI) 切割合成。

机器学习分类
为分类定义的类别是:水、原始森林、裸露的土壤、农业、人工林和田地,记住这项工作只是一个应用示例。
定义类后,我创建了多边形格式的样本,包含要作为一个整体分类的图像。我将面向对象的方法与随机树分类器结合使用,除了这些分类器之外还有其他分类器,例如:最大似然,支持向量机,k-最近邻。
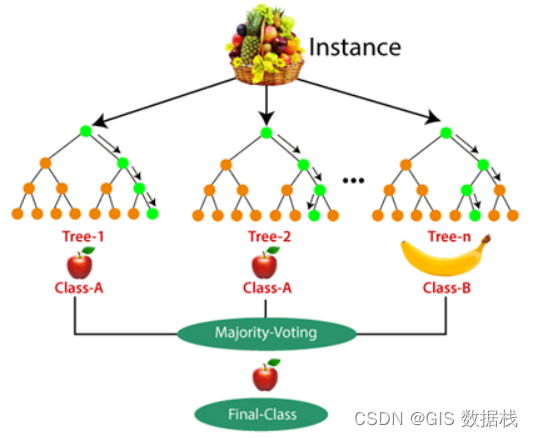
随机树分类器由一起运行的决策树组成,每棵树决定类别,得票最多的类别成为模型预测。下面是一个例子,说明最后一类的票数最高,在这种情况下,在一个水果篮中,我们有 2 棵苹果树和 1 棵香蕉树,最后一类将被定义为苹果,用于展示 2/3总票数。
为了进行分类,我对复合材料进行了分段,因为它是面向对象方法的必要步骤。分割对具有相似特征的像素进行分组,是减少逐像素分类中分散像素的替代方法。
这一步使用的工具是Image Classification Wizard,分类结果如下图所示。左图代表 RGB 合成,右图代表分类。

混淆矩阵
分类后,我用推理样本执行了混淆矩阵。主对角线表示以“正确”方式分配给每个类别的样本数量,行和列表示样本“出错”的位置,使用此数据可以为我们的模型执行准确性和Kappa索引. 混淆矩阵显示89% 的准确度和85% 的 kappa。

深度学习排名
为了利用上次分类的结果,我会将栅格文件转换为多边形,并在“为深度学习导出训练数据”工具中使用它,之后使用一些参数作为模型的基础,以及一个 45°使用旋转角度,这将有助于增加我的图像(样本)。此步骤耗时约 2 小时 51 分钟。
随着数据的导出,现在是训练深度学习模型的步骤。下一个工具是Train Deep Learning Model,我使用10个epochs,也就是模型通过整个层的次数,以及Resnet34架构,一种用于更复杂训练的神经网络,之后我使用10这些数据的百分比用于模型验证。
1 小时 40 分钟后,模型得到训练,其准确率约为 79%。现在是最期待的一步,我们要测试我们的模型,我将使用相同的组合,但在不同的地方训练。这一步使用的工具是Classify Pixels Using Deep Learning,结果如下图所示,我将真彩色图像与分类结果进行了比较。

在这两种分类中,原生植被和人工林之间以及田野和农业之间都存在问题,但这项工作的主要目的是基于机器学习提出这两种分类形式。
机器学习分类的准确率为 89%,而深度学习分类为79%。这并不意味着一种分类比另一种更好,而是需要在两种学习中进行更多的测试。
在某些情况下,使用机器学习对土地利用进行分类已经是一种解决方案,但在更复杂的情况下,有必要使用深度学习。