树莓派基础
===========================
烧写系统
①将sd卡插入读卡器,读卡器插入电脑
②在树莓派官网下载树莓派系统,并压缩包解压读写器
③下载etcher做系统烧写
④在读卡器G:boot里新建一个文件包括后缀的名字改为ssh(因为新版默认树莓派系统默认不支持ssh连接方式)
===========================
获取树莓派的IP地址
①用网线将树莓派与电脑连接
②打开网络共享,win10下右键电脑右下角wifi图标点击"打开网络和共享中心",点击电脑所连wifi会进入"WLAN状态",点击左下角"属性",点击"共享"
③获取树莓派IP地址。
方式1:进入cmd,通过ping raspberrypi.local获取
方式2:进入cmd,输入arp -a
方式3:使用IPscaner软件
遇到的bug:cmd中无ping和arp命令
解决方法:在环境变量Path中添加C:\Windows\System32
===========================
树莓派终端控制及传输
putty - 首次登陆树莓派使用
WinSCP - 方便树莓派与本地文件进行传输
===========================
SSH登陆树莓派 - Windows
用户:pi
密码:raspberry
 IP地址一般是192开头的那个,经验得出先将网线连接好再给树莓派上电找到IP的概率大一些
IP地址一般是192开头的那个,经验得出先将网线连接好再给树莓派上电找到IP的概率大一些

===========================
接口设置
sudo raspi-config,选择5 Interfacing Options
将P1 P2 P3使能

设置后再Config中选择 8 Update升级更新
===========================
VNC安装及使用
VNC是图形化树莓派系统的显示装置
"Raspberry Pi Configuration"中
修改resolution为1280x720,
修改localisation->language为中文keyboard为china chinese
===========================
利用VNC向树莓派导入文件
===========================
利用VNC向电脑导入文件
点右上角VNC图标

===========================
利用SFTP客户端导入文件
打开WinSCP,选择SFTP协议填写树莓派IP端口号为22,填写用户名和密码并登陆,当传输文件数量多的时候使用这种方式更方便快捷
===========================
树莓派安装卸载程序
树莓派->首选项->add/remove software
===========================
Linux系统简单命令应用
apt-get install (装系统本身的)
pip3 install (装python相关的)
===========================
安装tensorflow
方式1:(推荐)
sudo apt install libatlas-base-dev
pip3 install tensorflow
注意事项:
①此方法会装好很多依赖文件比较简单,但是解压时间比较长
②下载失败可能是网络原因。笔者因此采取了如下措施:让树莓派直接wifi连接且换清华源
方式2:
先下载好Whl文件,再导入tensorflow的whl文件
sudo pip3 install -v tensorflow-1.1.0-cp35m-linux_armv7l.whl
(-v是显示出来所有安装信息)
===========================
安装keras
sudo pip3 install -v numpy
sudo apt-get install python3-scipy
sudo pip3 install -v scikit-learn
sudo pip3 install -v pillow
sudo apt-get install python3-h5py
sudo pip3 install -v keras
===========================
在树莓派上写程序 - Geany
打开geanty: 菜单->编程->Geany
注意保存文件名要以.py结尾
===========================
给树莓派装中文输入法
sudo apt-get install fcitx fcitx-googlepinyin fcitx-module-cloudpinyin fcitx-sunpinyin
sudo apt-get -y install ttf-wqy-zenhei
安装后重启,ctrl+空格切换输入法
===========================
给树莓派系统备份
Windows下使用Win32 Disk Imager,选择TF卡储存名后加后缀.img
===========================
L298N控制下的电机
===========================
电机驱动板使用原因
树莓派GPIO单个引脚最大输出电流为16mA,同一时刻全部引脚总输出电流不得超过50mA,而遥控车直流电机空载电流350mA,堵转时电流更好。通过控制一个外设 - 电机驱动板,树莓派提供控制信号来驱动电机转动
===========================
电机驱动板原理
驱动原理:
三极管基极电流很小的变化可以引起电极电流很大的变化。
电机正反转电路原理:
H桥
L298N芯片:
双H桥电机驱动芯片,每个H桥可以提供2A电流,供电电压范围是2.5~48V
L298N驱动板:
以L298N芯片为核心,加入稳压模块
===========================
树莓派与L298N电机驱动板相连
树莓派通过对L298
坑:python3报错没有库RPi.GPIO
sudo pip3 install RPi失败
各种安装失败最后下载了RPi模块再进行安装
https://sourceforge.net/projects/raspberry-gpio-python/files/
python3 setup.py install
===========================
如何调节小车速度及相关库函数
仅对两个直流电机无法完成功能,现可通过pwm输出,当PWM波输出速度很快时,通过调节占空比就可以完成调速功能,pwm输出有两种方式:
①对电机驱动板使能端输入pwm
②对直流电机输入端输出pwm波
编程配置:RPi.GPIO.PWM(port,frequency)函数
开始输出pwm:RPi.GPIO.PWM.start(Duty cycle) - Duty cycle范围0~100
改变pwm占空比:RPi.GPIO.PWM.ChangeDutyCycle(66)
停止输出PWM:RPi.GPIO.PWM.stop()
===========================
驱动小车
①导入库RPi.GPIO和time
②初始化树莓派模式
③初始化IO口为输出
④初始化IO口输出电平
⑤清除IO口
import RPI.GPIO as GPIO
import time
backMotorInput1 = 7
backMotorInput2 = 11
GPIO.setmode(GPIO.BOARD)
GPIO.setup(backMotorInput1,GPIO.OUT)
GPIO.setup(backMotorInput2,GPIO.OUT)
GPIO,output(backMotorInput1,GPIO.HIGH)
GPIO,output(backMotorInput2,GPIO.LOW)
time.sleep(2)
GPIO.cleanup()
===========================
树莓派摄像头使用方法
使用前注意事项
①断电连接,连好后再开机,注意接插方向
②撕掉镜头前面的贴纸
③用双面胶将镜头固定在对应区域
④树莓派Interfaces使能Camera
测试
cd Desktop
raspistill -o image.jpg
摄像头会打开几秒拍一张名为image.jpg的图片存在桌面上
基本使用
预览拍摄图像,需在option里设置enable experimental direct capture mode

拍摄照片
raspistill -vf -hf -o image.jpg
-vf 上下翻转
-hf 左右翻转
-o后+ 输出文件名
间隔拍摄
raspistill -t 30000 -tl 2000 -o image%04d.jpg
-t :总时长是30000ms(即30s)
-tl:间隔是2000ms(即2s)
%04d:名字从0000一直取名递增
拍摄视频
raspivid -o video.h264 -t 6000
拍摄一段长度为6000ms的是视频并存为video.h264
omxplayer video.h264
使用Python预览摄像头数据 - picamera包
from picamera import PiCamera
import time
camera = PiCamera()
camera.start_preview()
time.sleep(10)
camera.stop_preview()
使用Python控制摄像头 - 旋转
from picamera import PiCamera
import time
camera = PiCamera()
camera.vflip = Ture
camera.hflip = Ture
camera.start_preview()
time.sleep(10)
camera.stop_preview()
vflip = Ture 则上下翻转 (vertical)
hflip = Ture 则左右翻转 (horizon)
flip - 翻动 vertical - 垂直 horizon - 水平
使用Python控制摄像头 - 控制分辨率
from picamera import PiCamera
import time
camera = PiCamera()
camera.resolution = (1280,720)
camera.start_preview()
time.sleep(10)
camera.stop_preview()
静态最大分辨率2592x1944
视频最大分辨率1920x1080
最小分分辨率64x64
使用Python控制摄像头 - 控制亮度
from picamera import PiCamera
import time
camera = PiCamera()
camera.brightness = 70
camera.start_preview()
time.sleep(10)
camera.stop_preview()
默认亮度是50
可设置范围是0~100
可根据实际调节,现场光线暗则可以增加亮度
使用Python控制摄像头 - 设定帧率
from picamera import PiCamera
import time
camera = PiCamera()
camera.framerate = 30
camera.start_preview()
time.sleep(10)
camera.stop_preview()
实际测试15帧是可以达到的
使用Python控制摄像头 - 控制对比度
from picamera import PiCamera
import time
camera = PiCamera()
camera.start_preview()
for i in range(100):
camera.annotate_text = "Contrast:%s"%i
camera.contrast = i
time.sleep(0.1)
camera.stop_preview()
annotate_text是注释文本
使用Python控制摄像头 - 加特效
from picamera import PiCamera
import time
camera = PiCamera()
camera.image_effect = 'cartoon'
camera.start_preview()
time.sleep(10)
camera.stop_preview()
使用Python控制摄像头 - 保存照片
#连续的
from picamera import PiCamera
import time
camera = PiCamera()
camera.rotation = 180
camera.start_preview()
for i in range(5):
time.sleep(3)
camera.capture('cam_cap%s.jpg'%i)
camera.stop_preview()
#单张
from picamera import PiCamera
import time
camera = PiCamera()
camera.rotation = 180
camera.start_preview()
time.sleep(10)
camera.capture('cam_cap.jpg')
camera.stop_preview()
使用Python控制摄像头 - 保存视频
from picamera import PiCamera
import time
camera = PiCamera()
camera.rotation = 180
camera.start_preview()
camera.start_recording('video.h264')
time.sleep(10)
camera.stop_recording()
camera.stop_preview()
使用with语句
精简代码
自动配置资源访问语句
自动处理进入与退出
with picamera.PiCamera() as camera:
camera.start_recording('video.h264')
camera.wait_recording(120)
camera.stop_recording()
with open("text.txt") as file:
text_data = file.read()
Custom outputs
import picamera
class MyOutput(object):
def __init__(self):
self.size= 0
def write(self,s):
self.size += len(s)
def flush(self):
print(self.size)
with picamera.PiCamera() as camera:
camera.resolution = (640,480)
camera.framerate = 60
camera.start_recording(MyOutput,'video.h264')
camera.wait_recording(10)
camera.stop_recording()
实时保存每张照片
import io
import time
import picamera
class SplitFrames(object):
def __init__(self):
self.frame_num = 0
self.output = None
def write(self,buf):
if buf.startswith(b'\xff\xd8')
if self.output:
self.output.close()
self.frame_num += 1
self.output = io.open('image%02d',self.frame_num,'wb')
self.output.write(buf)
......
camera.start_recording(output,format='')
......
神器的数字:ffd8代表一个JPG图片的开始
视频流实时处理每张照片
采用多线程,使用python的threading,每接受到一帧,放入一个空闲的线程进行处理
python字符串前面加u,r,b的含义
u/U:表示unicode字符串
r/R:非转义的原始字符串
b:bytes
python基础之Event对象、队列和多进程基础
Event对象
用于线程间通信,即程序中的其一个线程需要通过判断某个线程的状态来确定自己下一步的操作,就用到了event对象,event对象默认为假(Flase),即遇到event对象在等待就阻塞线程的执行
具体参考:https://www.cnblogs.com/lidagen/p/7252247.html
#子线程之间的通讯
import threading
import time
event=threading.Event()
def foo():
print('wait server...')
event.wait() #括号里可以带数字执行,数字表示等待的秒数,不带数字表示一直阻塞状态
print('connect to server')
def start():
time.sleep(3)
print('start server successful')
time.sleep(3)
event.set() #默认为False,set一次表示True,所以子线程里的foo函数解除阻塞状态继续执行
t=threading.Thread(target=foo,args=()) #子线程执行foo函数
t.start()
t2=threading.Thread(target=start,args=()) #子线程执行start函数
t2.start()
python语言中threading.Thread类的使用方法
编程语言里面的任务和线程是很重要的一个功能。在python里面,线程的创建有两种方式,其一使用Thread类创建
# 导入Python标准库中的Thread模块
from threading import Thread
# 创建一个线程
mthread = threading.Thread(target=function_name, args=(function_parameter1, function_parameterN))
# 启动刚刚创建的线程
mthread .start()
function_name: 需要线程去执行的方法名
args: 线程执行方法接收的参数,该属性是一个元组,如果只有一个参数也需要在末尾加逗号。
线程等待,我们的主线程不会等待子线程执行完毕再结束自身。可以使用Thread类的join()方法来子线程执行完毕以后,主线程再关闭。t.join()
import threading
def thread_job():
print("This is a added Thread ,number is %s"%threading.current_thread)
def main():
added_thread = threading.Thread(target = thread_job)#添加线程并制定功能
added_thread.start() #运行线程
print(threading.active_count)#输出目前运行的线程数
print(threading.enumerate)#输出已经运行的线程名
print(threading.current_thread())#输出目前运行的线程名
setDaemon
使用setDaemon()和守护线程这方面知识有关, 比如在启动线程前设置thread.setDaemon(True),就是设置该线程为守护线程,
表示该线程是不重要的,进程退出时不需要等待这个线程执行完成。
这样做的意义在于:避免子线程无限死循环,导致退不出程序
thread.setDaemon()#设置为True, 则设为true的话 则主线程执行完毕后会将子线程回收掉,设置false,主进程执行结束时不会回收子线程,默认False不回收,需要在 start 方法前调用
#调用示范
capture_thread = threading.Thread(target=pi_capture,args=())
capture_thread.setDaemon(True)
capture_thread.start()
道路采集
采集方式
1、先录像,后标记(比较麻烦,可pass)
2、遥控器遥控汽车,记录遥控器硬件信息(比较麻烦)
3、VNC遥控并记录(可以容易),利用pygame中的检测键盘输入
4、网页遥控(socket)(比较复杂,受限传输速度)
总体流程
同时picamera拍照
同时pygame检测 //两个同时运行,利用线程的方法
将图像储存
记录图像对应的方向
利用pygame检测键盘输入
设置pygame为不打开显示
初始化一个分辨率为1X1窗口
死循环监测事件
判断事件类型
获取键盘输入
import os
os.environ['SDL_VIDEORIVER'] = ‘dummy' #最新版的就改为1x1
import pygame
pygame.init()
pygame.display.set_mode((1,1))
while 1:
events = pygame.event.get()
for event in events:
if event.type == pygame.KETDOWM:
key_input = pygame.key.get_pressed()
print(key_input[pygame.K_w]) #K_w是一个常量,库中定义好的,对应键盘的w键
如何记录图像对应的方向
简单方法:在命名的时候加一个数字,比如在末尾加一个数字,0代表直走,1代表左转,2代表右转,3代表停止
多线程处理方法
在摄像头检测和图片处理的时候没有必要设置两个线程,直接在一个py文件中设置两个函数,若其中给一个入图片处理函数,只要停止了图片处理函数,摄像头检测函数也会停止
keras搭建深度学习神经网络
新建python虚拟环境
1、在桌面新建项目文件夹,例如selfdriving
2、cd命令进入selfdriving文件夹
3、python -m venv kerasenv
4、在selfdriving文件夹内会出现一个kerasenv文件夹
5、继续输入kerasenv\Scripts\activate。命令行开头会出现(kerasenv)字样
安装tensorflow和keras
在虚拟环境中输入pip install tensorflow
然后安装keras,pip install keras
△确保python是3.5或3.6并且是64位,且这种安装是cpu版本,此次安装是在电脑上而不是在树莓派上
keras搭建深度学习神经网络流程
导入数据->数据预处理->构建模型->编译模型->训练模型->测试模型
keras使用-手写数字识别任务
为方便图形展示安装matplotlib模块,在已激活虚拟环境的命令行中输入pip install matplotlib。
#导入数据并展示
from keras.datasets import mnist
import matplotlib.pyplot as plt
(x_train,y_train),(x_test,y_test) = mnist.load_data()
plt.figure() #创立一个窗口
plt.imshow(x_train[30],cmap='gray') #负责对图像进行处理
plt.show() #负责imshow函数处理后的数据显示
print(x_train.shape) #查看数据尺寸,可以得到60000,28,28
#转换数据类型并进行归一化处理
img_rows,img_cols = 28,28
x_train = x_train.reshape(x_train.shape[0],img_rows,img_cols,1) #x_train.shape[0]就是60000,样本量
x_test = x_test.reshape(x_test.shape[0],img_rows,img_cols,1) #reshape后由3维变4维,最后1维是干什么做的,不同卷积核对同一图片有不同结果
input_shape = (img_rows,img_cols,1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:',x_train.shape)
print(x_train.shape[0],'train samples')
print(x_test.shape[0],'test samples')
#标签数据转换为2进制数组
#例如3转换为[0,0,0,1,0,0,0,0,0,0]
import keras
num_classes = 10
y_train = keras.utils.to_categorical(y_train,numclasses)
y_test = keras.utils.to_categorical(y_test,numclasses)
#构建序列式神经网络模型
from keras.model import Sequential
from keras.layers import Dense,Dropout,Flatten
from keras.layers import Conv2D,MaxPooling2D
model = Sequential()
model.add(Conv(32,kernel_size(3,3),
activation = 'relu',
input_shape = input_shape))
model.add(Conv2D(64,(3,3),activation = 'relu'))
model.add(Maxpooling2D(pool_size(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128,activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes,activation = 'softmax'))
编译神经网络模型
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics= [‘accuracy’])
optimizer:优化器
metrics:列表,包含评估模型在训练和测试时的网络性能指标
编译神经网络模型
model.fit(x_train,y_train,
batch_size=128,
epochs=12,
berbose=1,
validation_data=(x_test,y_test))
batch_size:梯度下降每个batch包含的样本数
epochs:训练多少轮结束
verbose:是否显示日志信息
validation_data:用来验证的数据集
评估神经网络模型
score = model.evaluate(x_test,y_test,verbose = 0)
print(‘Test loss:’,score[0])
print(‘Test accuracy:’,score[1])
使用神经网络模型测试
prediction = model.predict(x_test[20].reshape(1,28,28,1))#输出的事one-hot格式
prediction = prediction.argmax(axis=1)
plt.figure()
plt.imshow(x_test[20].reshape(28,28))
plt.text(0,-3,prediction,color=‘black’)
plt.show()
保存神经网络模型
先安装神经网络模型
pip install h5py
model.save(‘my_model.h5’)
使用训练好的模型
model = keras.models.load_model(‘my_model.h5’)
神经网络参数的调试
超参数
超参数是在学习过程之前设置值的参数,而不是通过训练得到的参数数据,例如学习率和batch size
学习率的初始化
如果不是自适应的,则需要调整
如果cost在减小,则可以逐步增加学习率,比如0.1,1.0
如果cost在增加,那就需要减小学习率,试试0.001,0.0001
batch size初始化
batch选越大,可以越充分利用矩阵、线性代数库进行计算加速,计算越充分,但是优化过程太漫长
batch选越小,计算加速效果越不明显,但是优化过程更快
参数调优
使用较小的训练集来调试超参数
先调试重要性高的超参数,固定一个最佳值后再去调试其他值
非自适应学习率调试策略:
常用技巧是学习速率退火,先以较高的学习率开始,然后慢慢地训练中的降低学习率,如果不是对结果数据集准确性极其严格,自适应即可
监控学习过程 - TensorBoard
可以记录的数据:Loss-Epoch,Accuracy-epoch
#引入Tensorboard
from keras.callbacks import TensorBoard
在命令行中输入tensorflow --logdir=logs,然后根据提示打开网页,logs是自己在log_dir写的,实际上目录名是自己输入的
#打开TensorBoard
tb = TensorBoard(log_dir = './logs', #训练的参数存储位置
histogram_freq= 1, #按照什么频率计算直方图,若为0则不计算
batch_size=128,
write_graph = Ture, #神经网络结构图
write_grads = False, #梯度,一般选择false
write_images = False) #慎重考虑,若ture则把图像存储下来,若开启则训练时间加长很多
callback = [tb] #
model.fit(x_train,y_train,
batch_size = 128,
epochs =12,
verbose = 1,
validation_data=(x_test,y_test),
callbacks = callbacks
)
#详细参考keras.io/zh/callbacks/
Epoch选择
将整个数据集分成三个互不相交的子集,Train Set,Validation Set,Test Set
训练每迭代一次就拿当前的模型去Validation Set上做预测
如果连续N代在Validation Set上的精度都不再上升,则
可以使用回调函数EarlyStopping当监控数量不再提升则停止训练
卷积核的作用
 找到合适的卷积核从图片中提取自己需要的部分
找到合适的卷积核从图片中提取自己需要的部分
卷积核的选择

一般使用ReLu激活函数,基本使用这个激活函数就可以满足需求
softmax激活函数适用于分类的任务当中最后一层
优化器的选择

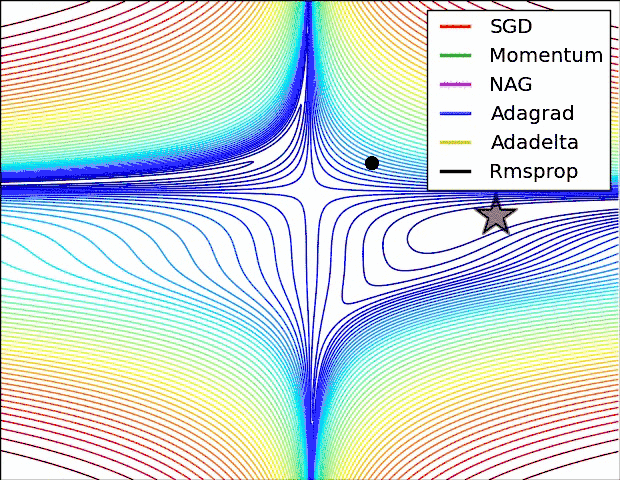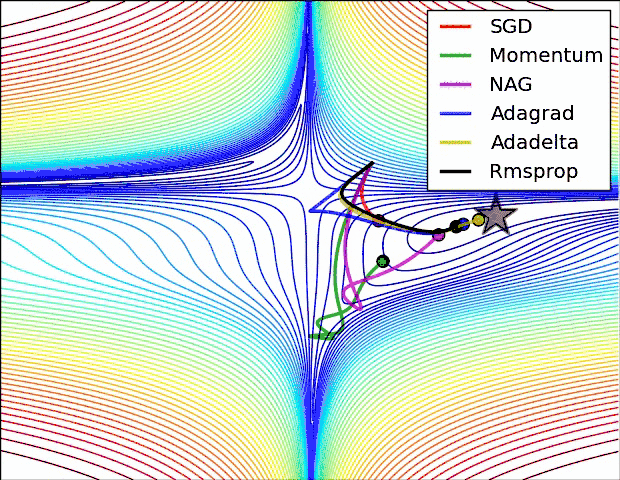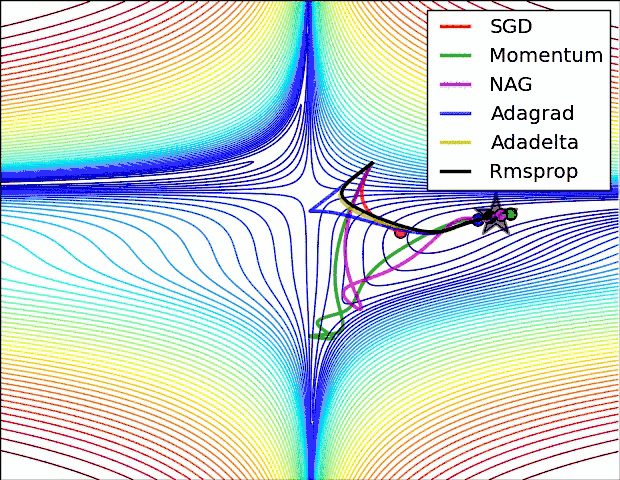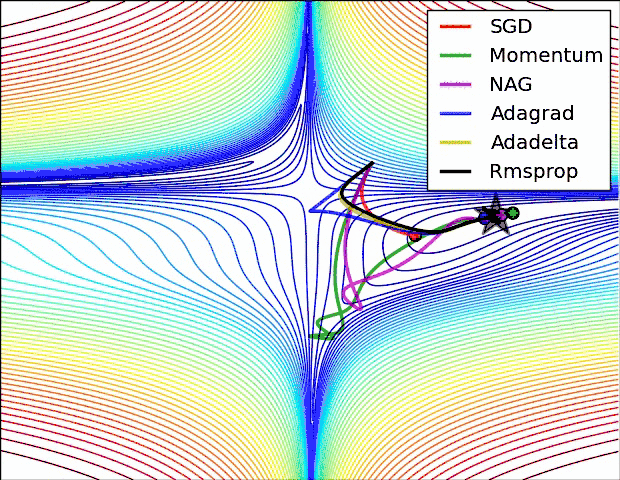
上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法
其他经验
卷积核个数:通常为32、64等2的N次方,这样方便CPU去计算
调参时先用小一些的数据集快速验证,再转移到大数据集
多多参考TensorBoard的反馈
Dropout一般选择0.5
自动驾驶模型真实道路模拟行驶
其他经验总结
问题一
问题:车从直线走到转弯处不会转弯,但直接放在转弯处会转弯
解决原因及方法:
①可能是训练集不够导致的
解决方法:加大数据集
②可能是跑到转弯处摄像头图像模糊了,摄像头抖动比较厉害
解决方法:可能没有完全将摄像头固定好
③直行后转弯的速度快,处理速度没有这么快,例如车到转弯处的摄像头图像已经是赛道外了,车子就会乱跑
解决方法:若打开了VNC则在正式测试的时候一定要关闭,因为占用内存过多,会导致树莓派运算速度慢。可以用SSH运行drive.py
问题二
问题:整个小车训练的流程
答案:
①collect data。运行collectdata.py文件,通过键盘去操控小车在赛道上跑,手动操作小车的时候摄像头会自动记录照片并将小车方向对应的数字记录下来并生成图片文件(此时得到的文件格式是.JPG),再运行process_img_npz.py将jpg格式转换为npz格式(这样做是节约模型训练的时间,当然也可以在训练的py文件里打开jpg图片然后转换为numpy数组,只不过会影响训练时间)。
②train model。在电脑上将Data喂入Keras神经网络训练得到模型文件.h5(在dripy.py同目录下建文件夹model,然后将.h5放入model文件夹)
③predict。.h文件放入树莓派上,在树莓派上运行drive.py,树莓派就用模型及摄像头预测控制小车
问题三
问题:class类里的__init__不是很理解
class Myclass(object):
def __init__(self,name):
self.name = name
def say_hi(self):
print(self.name)
my_class = Myclass('Bi')
my_class.say_hi()
my_class = Myclass(‘Bi’)实例化后会执行__init__函数,其他函数需要单独调用例如my_class.say_hi()
问题四
图片预处理优化
解决:
①转换为灰度值(取出光照影响)
②二值化