1.问题描述?
本文要解决的问题是手写数字识别。使用的数据集为:mnist。

我们需要让计算机识别图片中的手写数字是多少。
这个问题对于我们人类来说非常简单,一眼就看出来图片中的数字是几了。 但是对于机器来说却很难,因为机器从一张图片中看到的是一堆没啥意义的数字。

2.解决思路?
那如何让计算机认出图片中的数字是几呢?
在计算机中,图片是由多个像素组成的。如果图片是灰度图则每个像素由8位二进制组成。

如果图片是彩色图片,则每个像素由三个8位二进制表示(分别表示红、绿、蓝三种颜色的值)。

虽然单个像素不能表达任何信息,但是把多个像素连在一起,不同数字的图片就有不同的特征了。 比如,下面这张图片。
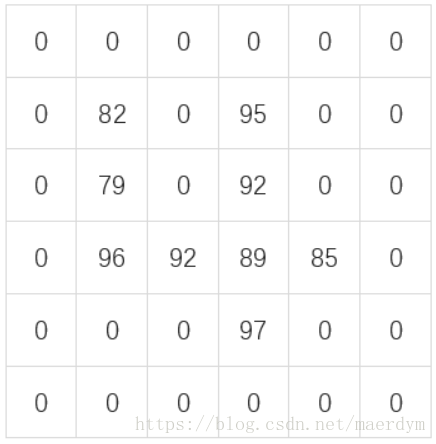
乍一看,我们可能看不出来图片表示什么。但是如果我们把不是0的部分都加上阴影,数字越大阴影越深。
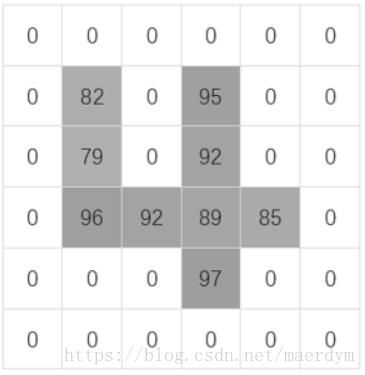
你就能看出来上面的图片代表数字4了。
计算机可以采用同样的原理。一个像素代表不了什么,但是多个像素组合起来,就能表示出不同数字的特征了。 依据这些特征,就可以识别出图片中代表的数字了。
3.模型架构?
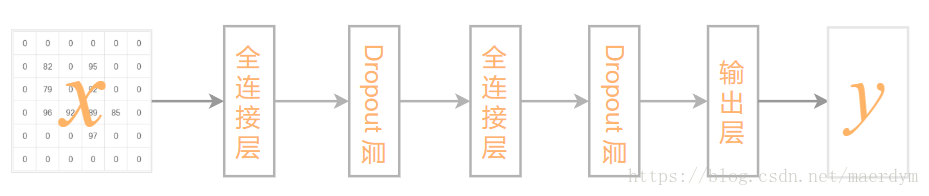
本文将采全连接网络来实现手写数字的识别。整个网络包含两个 全连接层、 两个Dropout层 和一个输出层。
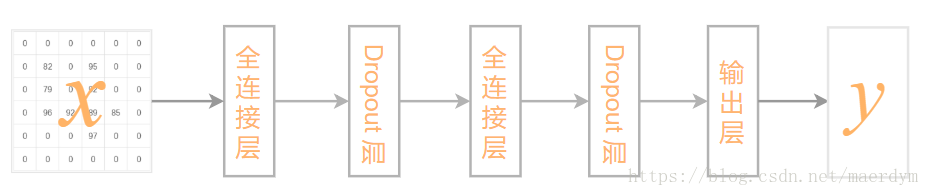
因为输出的结果为0-9数字中的一个,一共包含10类。因此使用SoftMax输出图片对于每种类别的概率。
4.工具包说明?
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
1). 首先导入keras核心类库
2). 接着导入keras自带的数据工具类mnist,该类会从amazonaws下载mnist数据集(无法下载怎么办)。
3). 然后导入线性模型构造器(也叫贯穿模型Sequential,用来构造简单的流水线式机器学习模型)
4). 之后导入全连接层Dense和Dropout层Dropout
5). 最后导入模型优化器RMSprop,Keras会通过优化器来更新参数,优化模型。
5.定义全局变量?
batch_size = 128
num_classes = 10
epochs = 20
1). 设置每批处理的样本数量,本例中每批随机抽泣128个样本进行处理
2). 设置总分类数,本例会将图片分为0-9,共10个类别
3). 设置训练轮数,本例总总共训练20轮,即所有样本都会被重复训练20次
6.加载数据?
(x_train, y_train), (x_test, y_test) = mnist.load_data()
1). 通过keras自带的mnist工具包加载数据
2). 加载出的数据分成两部分,训练数据集(60000张图片)和测试数据集(10000张图片)
3). 每个数据集中又包含样本特征和样本标签两个部分
4). 样本特征为图片的像素数据,每张图片有28*28共784个像素组成
5). 样本标签为图片上对应的真实数字
keras会总动从amazonaws下载数据集,如果下载失败请参考无法下载怎么办
7.设置数据形状?
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
1). 将训练样本集的特征数据,变成60000行784列(28*28)
2). 将测试样本集的特征数据,变成10000行784列
3). 转化后,样本集中的每一行都代表一个样本,每个样本有784个特征(784个像素)
如果是手工下载的数据集,数据集本身已经做过形状处理了,无需本步操作
8.设置数据类型?
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
将特征数据强制转化成float32类型,方便tensorflow等框架的处理
如果是手工下载的数据集,数据类型已经转化过了,无需本步操作
9.数据归一化?
x_train /= 255
x_test /= 255
1). 因为每个像素都是用8位二进制表示的,因此最大值为255
2). 特征数据除以255后,其值缩小到0-1范围内了,此操作称作Min-Max归一化
3). 数据归一化后,可以加速模型收敛,提升训练速度
如果是手工下载的数据集,数据已经归一化了,无需本步操作
10.将标签转化成one-hot形式?
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
1). 目前样本标签为1、2、3……等自然数
2). SoftMax分类输出的结果为各个类别的概率,而不是1、2、3……等自然数
3). 因此需要将样本标签转化成One-Hot向量,样本标签对应的元素为1,其他元素为0。
转化后,训练样本集的标签数据将包含60000行10列,每行为1个样本标签,样本标签为一个向量,向量中值为1的元素索引就是图片对应的数字。

11.构建模型?
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
1). 首先通过线性模型构造器,创建一个模型model
2). 接着向模型中添加一个全连接层Dense,该层包含512个神经元、激活函数为relu,输入样本的形状为(784,)
3). 然后向模型中添加一个Dropout层,该层会随机丢弃20%神经元(随机将20%神经元的输出强制清零)
4). 然后再向模型中添加一个全连接层Dense,该层包含512个神经元、激活函数为relu
5). 之后再向模型中添加一个Dropout层,该层会随机丢弃20%神经元(随机将20%神经元的输出强制清零)
6). 最后向模型中添加一个全连接层用作输出,该层神经元的数量与分类数量一致,使用的激活函数为SoftMax,来输出样本属于各个类别的概率。
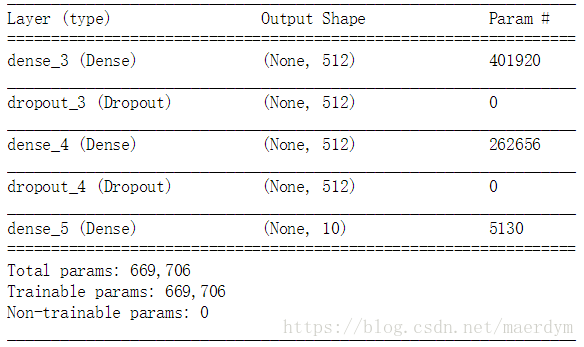
12.输出模型结构?
model.summary()
输出模型结构和参数数量
模型包含5层,总共的参数数量为:669,706
13.编译模型?
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),metrics=['accuracy'])
1). 使用函数compile来编译模型
2). 模型使用的损失函数为categorical_crossentropy,即交叉熵损失函数
3). 模型使用的优化器为RMSprop,通过优化器来调整参数,优化模型
4). 模型使用的度量指标为accuracy,即分类准确率
编译模型时,可以指明损失函数、优化器和度量指标。模型编译完成后,就可以进行训练啦。
14.训练模型?
history = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=1, validation_data=(x_test, y_test))
1). 使用函数fit来训练模型
2). 训练模型时需指明训练数据x_train, y_train
3). 训练模型时可指明每批处理的样本数量batch_size=batch_size,本例中每步训练会同时处理128个样本
4). 训练模型时可指明总共要训练多少轮epochs=epochs,本例中所有样本要被训练20轮
5). 训练模型时可指明日志等级verbose=1,verbose为1表示打印进度日志
6). 训练模型时可指明验证数据集validation_data=(x_test, y_test)
15.评估模型?
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
1). 使用函数evaluate来评估模型
2). 评估模型时需指明测试数据集x_test, y_test
3). 评估模型时可指明日志等级verbose=0,verbose为0表示不打印显示日志
4). 函数evaluate返回的结果中,包含两个元素:损失大小和分类准确率
评估完成后,系统将输出如下信息:
最终的识别准确率将超过98%

16.完整代码?
import gzip, pickle
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
#mnist数据集加载函数
def load_mnist():
with gzip.open("D:/software/datasets/mnist.pkl.gz", "rb") as f:
train, valid, test = pickle.load(f, encoding="latin-1")
train_X = train[0].astype("float32")
valid_X = valid[0].astype("float32")
test_X = test[0].astype("float32")
train_Y = train[1]
valid_Y = valid[1]
test_Y = test[1]
return train_X, train_Y, valid_X, valid_Y, test_X, test_Y
#定义常量,包括批数据大小、分类数量和训练轮数
BATCH_SIZE = 128
INPUT_SIZE = 784
NUM_CLASSES = 10
EPOCHS = 20
# 加载数据集
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = load_mnist()
train_Y = to_categorical(train[1], NUM_CLASSES)
valid_Y = to_categorical(valid[1], NUM_CLASSES)
test_Y = to_categorical(test[1], NUM_CLASSES)
print("shape of train_X is ", train_X.shape)
print("shape of train_Y is ", train_Y.shape)
# 构建贯穿模型,包括三个全连接层和两个Dropout层
model = Sequential()
model.add(Dense(units=256, activation="relu", input_shape=(INPUT_SIZE,)))
model.add(Dropout(0.2))
model.add(Dense(units=64, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(units=NUM_CLASSES, activation="softmax"))
# 编译模型
model.compile(optimizer=RMSprop(), loss="categorical_crossentropy", metrics=["accuracy"])
# 填充数据并训练模型
history = model.fit(train_X, train_Y, epochs=EPOCHS, batch_size=BATCH_SIZE, verbose=1, validation_data=(valid_X, valid_Y))
# 评估模型
score = model.evaluate(test_X, test_Y, batch_size=BATCH_SIZE, verbose=1)
# 打印损失大小和识别准确率
print(‘Test loss:’, score[0])
print(‘Test accuracy:’, score[1])
-------------------------完结--------------------------
感谢您的阅读,关注公众号袋马AI,获取最新资料。
