reference:《GPU Pro 5》
总览
本章将介绍一种计算动态3D场景反射的新方法,该方法适用于任意形状的表面。Mirror’s Edge早期研究的算法和技术已经提出并共享。
我们将研究的方法在性能和图像质量方面都由于任何其它方法,如第4.8节“性能”和第4.9”结果“中所示。
我们将研究在实时反射领域所做的最新工作,分析它们的优缺点以及它们未能实现的目标。然后我们将研究一种在游戏交互式帧率下实时计算反射的新方法。
首先,我们将介绍算法本身,它使用屏幕空间平齐的四叉树,我们称之Hierarchical-Z(Hi-Z)缓冲区来加速光线追踪。层次结构存储在Hi-Z纹理的mip通道中。该加速结构用于在空的空间中跳跃来有效地达到交点。我们将进一步讨论光泽反射所需的所有预计算通道以及如何构造它们。我们还将研究一种称为屏幕空间椎体跟踪的技术,用于近似粗糙表面,从而产生模糊的反射。此外,还讨论了算法的性能和优化。然后展示算法的扩展以改进和稳定结果。一个扩展是使用时间上的滤波,这允许我们累积几个先前帧的反射结果,来重新投影先前图像来稳定当前帧的输出结果,即使在相机移动时也是如此。由于先前的帧已包含反射,因此在进行时间滤波时,能够低成本地近似反射多个光线反弹的效果。我们还将提到目前正在开发的研究和技术,例如将若干光线一起分组,组成数据包,然后在找到粗略的焦点后细分并发出较小的光线。未来研究的另一个方向是基于屏幕空间图块的追踪,如果整个图块包含大部分粗糙表面,我们可以发射更少的光线,因为结果很可能是模糊的,从而提升了性能,这给了我们更多空间用于其它类型的计算,以产生更好的图像。
最终我们将为PC显示计时器。对于PC,我们将使用基于NVDIA和AMD的显卡,在我们结束本章之前,我们还将提到目前正在研究和开发的一些想法。
本章提出的这种新颖的且经过生产验证的方法(用于Mirror's Edge)可确保计算局部反射的最高质量、稳定性和良好性能,尤其是当它与游戏行业中已有方法结合使用时,例如局部立方体映射 [Bjorke 07, Behc 10]。特别注意需要计算物理精确的光泽/粗糙反射,来匹配反射的拉伸和扩散在不同角度的现实生活中的表现,这是一种微观裂缝引起的现象。
简介
让我们从反射的实际定义开始:
反射是波的方向变化,例如光或声波,远离波遇到的边界时,反射波保留在原始介质中,而不是进入它们遇到的介质。根据反射定义,反射波的反射角等于其入射角(图4.1)。

图4.1 反射定律表明入射角i等于反射角j。
反射是照明的重要组成部分,人眼所感知的一切都是反射,无论是高光(镜面),光泽(粗糙),或是漫反射(不光滑的),这是实现材质和光照真实感的重要部分。反射遮蔽有助于将被反射到场景中的的物体接地到接触点中,如图4.2和4.3所示。它是我们实现真实视觉效果的重要组成部分,不应掉以轻心,因为它可以在实现真实感效果方面产生重大影响。

图4.2 反射对实现照片级渲染目标的影响。注意地板接触点附近的反射遮挡和阻挡入射光的门。

图4.3 光照在射线击中阻挡光的障碍物时,呈现反射遮挡,就像图4.2中门挡住了白色的光一样。
最近几乎没有发展用于在高性能游戏帧速率水平的实时图形工业中产生精确的反射,特别是光泽的反射,这意味着算法必须以每帧毫秒的一小部分预算来进行。
由于计算的高性能要求,解决计算机游戏中的反射一直是一个巨大的挑战。我们为每帧提供有限的毫秒预算,60fps为16.6毫秒,30fps为33.33毫秒,在此期间重新计算所有内容,并向用户显示最终的图像。这包括从游戏模拟、物理、图形、AI到网络的所有内容。如果我们不能将性能水平维持在毫秒级,用户将不会在游戏输入中得到实时反馈。现在想象一下,这些毫秒的一小部分只需要进行反射,使用GPU硬件运行的基于光栅化的技术,在运行速度可达几毫秒且仍然保持最高质量水平的算法很难实现。
尽管在很长的一段时间内,游戏开发人员已经能够在简单的情况下产生假的反射,但是并没有一个解决方案能将每个问题都修复到可接受的真实水平,并具有一定的性能。对于平面,即墙壁和地板,可以轻松翻转相机,然后重新渲染整个场景,并将生成的图像投影到平面上,以实现我们今天所提到的平面反射。这适用于平面表面,例如地板和墙壁,但是对于任意形状的表面,它可以反射到每个像素的任何方向,这是完全不同的。重新渲染整个场景并重新计算每个平面的所有照明也是一项昂贵的操作,并且很容易成为性能瓶颈。
现有的完美结果的唯一解决方案是我们所说的光线追踪。但是,跟踪反射光线和几何图元(一组构成3D世界的小三角形)的相交在计算上性能消耗很大,因为光线可能到了任何地方,我们需要维护buffer中的整个场景,并具有可快速遍历访问的数据结构。即使在今天使用最优化的算法和数据结构,光线跟踪在游戏上部署的性能方面仍然不够快。
之前的工作
如今,使用GPU中基于光栅化的硬件即使不是不可能的,也很难产生100%准确有效的反射。虽然我们已经转向更通用的计算架构,允许我们更自由地发挥,但仍然没有足够的效率来使用真正的光线跟踪器。出于这个原因,游戏开发人员长期依赖于平面反射,你可以从镜像相机为每个平面(如地板或墙壁)重新渲染场景,并投影图像以创建平面反射。人们长期以来的另一种技术是立方体贴图,用六个图像从一个点捕获周围环境的360度环绕效果,每侧有一个90度的视野,因此这些反射仅针对具体点。
一个名为屏幕空间局部反射的新想法首先由[Graham 10]在Beyond3D论坛上展示,然后由Crytex引入Crysis2 DX11的补丁。他们都在屏幕空间中提出了一种更简单的ray-matching算法。屏幕空间意味着我们在2D帧缓冲对象,即图像中执行所有操作,作为后处理效果。这是一个相当简单的想法,你只需使用场景普通缓冲区计算一个屏幕空间的反射向量,然后通过一定步长的像素进行Ray-match,直到光线深度低于深度缓冲区里的场景深度。一旦光线深度低于场景深度,我们检测到相交并使用新的屏幕空间坐标来读取场景颜色,该场景颜色用作我们开始Ray-match的像素的反射。该技术如图4.4所示。

图4.4 通过z-buffer(深度缓冲区,使用浮点数来表示场景深度的图像)在屏幕空间中采取较小的步长进行Ray-matching,直到射线的深度低于场景深度。一旦它低于表面深度,我们就可以停止Ray-matching并使用新的坐标来获取反射颜色并将其应用于我们开始Ray-matching的像素。
然而,由于该计算是在屏幕空间中执行的,因此需要注意一些限制。这种技术的内在问题是,并非所有信息都可供我们所用。想象一下镜子在视线方向的相反方向的反射光线,此信息在屏幕空间中不可用。这意味着遮挡和丢失信息对于这种技术来说是一个巨大的挑战,如果我们不能处理这个问题,我们将产生伪影,并产生不正确的反射颜色。衰减的光线落在屏幕边框之外,落在遮挡的物体后面,此处建议使用指向相机的光线。
另一方面,如果为极短的距离反射执行少量步骤/样本,这种类型的线性Ray-mathcing可能非常有效,一旦你有一个很长的光线,这个方法开始执行的非常慢,因为它需要在每个循环中获取所有纹理,以从z-buffer中读取场景深度。因此延迟隐藏(latency hiding)开始减少,我们的核心也基本上停止了,什么也不做。
由于在每个样本处都采用恒定步长,这也容易出错,因为可能会错过非常小的细节。如果光线旁边的小细节小于步长,我们可能跳过它得到不正确的反射结果。
这些步骤的数量以及这些步骤的大小在这种线性Ray-match的质量方面产生巨大差异。这种技术也会产生阶梯状的伪影,一旦找到交叉点,必须采用某种形式的细化。这种改进将在先前的Ray-match位置和Ray-match交点之间,汇聚成更加精细的交点。用少量的二分搜索或单一的线段搜索通常足以处理纯镜面光线的阶梯伪影(参见图4.5)。Crytek在每个迭代步骤中使用光线抖动长度来消除阶梯伪影。
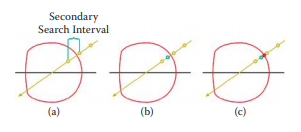
图4.5 交点位置和光线最后位置之间的二分搜索。基本上,它需要两者的中间点,并检查它否是仍然相交。如果返回true则继续检查,直到它能重现,于是得到一个精确的位置。我们还可以看到线性Ray-match采用恒定步长,并以错误的坐标结束,这将产生阶梯状的伪影,因此我们需要某种程度的细化。二分搜索和线段搜索很受欢迎。
遍历深度缓冲区的简单线性Ray-match算法可以用少于15行的代码编写,如列表4.1所示。
#define LINEAR_MATCH_COUNT 32
for(int i = 0; i < LINEAR_MATCH_COUNT; i++)
{
// Read scene depth with current ray.
float d = depthBuffer.SampleLevel(pointSampler,ray.xy,0);
// Check if ray is greater than the scene, it means we intersected something so end.
if(ray.z > d)
break;
// Else advance the ray by a small step and continue the loop.
// Step is a vector in screen space
ray += step;
}List 4.1 一个简单的Ray-match,用于说明遍历深度缓冲区直到找到交点的概念。我们很快可以看到这种技术会受限于获取部分,ALU单元没有做很多工作,因为ALU指令太少,无法隐藏延迟,必须等待全局内存提取完成。
那么让我们仔细看看这种技术的一些主要问题。
1. 它需要较小的步长,延迟会很快陷入瓶颈。
2. 如果所使用的步长大于光线旁边小细节,则可能会遗漏小细节。
3. 它会产生阶梯伪影并需要细化,例如线段或二分搜索。
4. 它只对较短的长度较快,如果Ray-match跨越了整个场景会使核心停滞并导致性能下降。
我们的目标是引入一种可以解决以上四点的算法。
所有这些点都可以通过引入一个加速结构来解决,然后加速结构可以用于加速Ray-match过程,基本可以穿过光线可能经过的距离,而不会有任何细节遗漏的风险。这种加速结构将允许光线采取任意长度的步长,特别是大的步长,只要它可以。它也会减少提取次数。加速结构将产生很好的结果,而不需要额外的细化通道,尽管在前一个像素和当前像素之间做最终线段搜索并没有什么坏处,因为加速结构通常是一组离散的数据。由于我们通过使用加速结构获得了大幅加速,因此我们也可以做更长时间的行进,并以更好的性能对整个场景做Ray-match。
本章提出的称为Hi-Z屏幕空间锥跟踪算法可以通过快速收敛来反射整个场景,并且比基于线性步长的Ray-match算法快几个数量级。
算法
提出的算法可分为五个不同的步骤:
1. H-Z pass.
2. 预整合 pass.
3. 光线追踪 pass.
4. 预卷积 pass.
5. 锥形追踪 pass.
我们现在将逐步来完成每一步。
Hi-Z Pass
Hierarchical-Z缓冲区,也称为Hi-Z缓冲区,是通过获取z-buffer中四个相邻值得最小值或最大值将其存储在原有缓冲区一半大小的缓冲区来构造情况下,我们将使用最小值的版本。
Z-buffer将3D场景的深度值保存在诸如纹理/图像的缓冲器中,下图表示Hi-Z结构的最小值版本是如何运行的:

结果是原始缓冲区的粗略表示。我们在生成的缓冲区上连续执行此操作,直到我们遇到大小为1的缓冲区,这意味着我们不再能够继续变小了。我们将计算值存储在纹理的mip通道中,如图4.6所示。
我们将结果称为Hi-Z缓冲区,因为它以分层方式来表示Z值(也就是场景深度值)。
这一缓冲区是算法的核心,它本质上是一个屏幕/图像对齐的四叉树,它允许我们通过关注和跳过场景中的空白空间来加速光线追踪算法,以通过在不同层次结构级别中索引来有效且快速地到达我们所期望的交点/坐标。在我们的例子中,空白区域使我们在图像中看到的图块,即四边形。

图4.6 原始场景(顶部)和相应的Hi-Z(Hierarchical-Z)缓冲区(底部),使用连续2x2最小深度构建。它可以作为屏幕空间中光线的加速结构。Mip0是我们的深度缓冲区,表示每个像素的场景深度。在每个级别,我们采用最小2x2像素并产生深度值的这种分层表示。
与先前开发的方法不同,即在图像中采用恒定的步长,我们通过采用大步长并通过在层次结构级别中索引来达到快速收敛,因此Ray-match的方法会运行的更快。
图4.7显示了一个简单的Hierarchical-Z表示,将屏幕空间逆投影回世界空间来进行可视化,它本质上是一个高度场,暗处靠近相机,亮处则离相机较远。
无论是在后投影深度缓冲区,还是视图空间的z-Buffer上构造此pass,都会影响其余pass的处理方式,需要相应的更改它们。
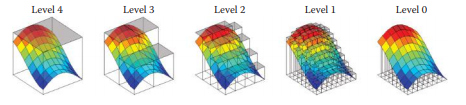
图4.7 Hi-Z(Hierarchical-Z)缓冲区,已从屏幕空间投影回世界空间来进行可视化。
预整合Pass
预整合pass以分层方式计算锥形追踪过程中计算场景可见性。这篇文章借鉴了[Crassin 11],[Crassin 12]和[Lilley et al.12]中使用体素结构而非2.5D深度的思想。此pass的输入是我们的Hi-Z缓冲区。在我们深度的根层级,所有像素都是可见的;然而,当我们进入层级结构后,单元格粗略表示的总可见性相比四个更精细像素的可见性更小或相等:
![]()
(另请参见图4.8)我们将粗略的深度单元视为包含更精细几何体的体积,我们的目标是计算在粗略水平上的可见度。
然后,锥形追踪通道将在不同层级对此预先集成的可见性缓冲区进行采样,直到我们的Ray-match累积了100%的可见度,这意味着该椎体内的所有光线都会与某些物体发生碰撞,这近似于椎体足迹。我们基本上整合了所有光泽反射光线。我们从光线可见度1.0开始,在进行锥形追踪时,我们将持续减去累积的量,直到达到0.0(见图4.9)。

图4.8 我们计算可见度的四个像素的最小和最大深度平面之间的感兴趣区域,基本上,我们会取空体积的百分比。
但是,我们不能仅依赖于可见性缓冲区。我们必须知道我们的椎体实际上与几何体相关的程度,为此我们将使用我们的Hi-Z缓冲区。我们最终计算的权值将是一个可见度的累积量,依据我们的锥形球在Hi-Z缓冲区之上、之间或之下的程度。
我们使用每通道8bit的缓冲区来记录预整合结果,它能提供256个值来表达我们的可见性。这为我们的可见性值(1.0/256.0)提供了0.390625%的增量,这对于透明度而言已经足够精确。
同样,这一pass高度依赖于我们使用后投影深度的Hi-Z还是视图空间的Hi-Z缓冲区。

图4.9 分层预整合可见性缓冲区的2D表示。百分比是在最小和最大深度之间计算的。高度是深度,颜色是可见度。
光线追踪 pass
以下函数是反射公式,其中V是视线方向,N是曲面法线方向(曲面朝向),返回值是反射向量。
![]()
点是两个向量之间的点积,也称为标量积。我们稍后将使用次函数来计算算法的反射方向。
在继续使用光线追踪算法之前,我们必须了解3D场景的深度缓冲区实际包含的内容。深度缓冲区是非线性的,这意味着3D场景的深度值的分布不会随着到相机的距离而线性增加。我们在相机附近精度较高,而远离精度较低,这有利于我们确定在绘制时哪个物体最接近相机,因为更近的物体比更远的物体更重要。
根据定义,除法是一种非线性运算,在透视校正过程中会存在除法运算,此时我们得到了非线性的深度。非线性值无法线性插值。然而,尽管深度缓冲区中的z值相对于相机的z距离不是线性增加的,但在另一方面,由于透视,它在屏幕空间中确实是线性的。当从三个顶点绘制时,透视校正光栅化硬件需要在整个三角形表面上进行线性插值。特别地,硬件使用原始三个顶点对构成三角形表面的每个点用1/z进行插值。直接用z进行线性插值不会在三角形表面上产生正确的深度值,但是1/z可以。图4.10解释了为什么非透视插值是错误的。

图4.10 直接在屏幕空间插值会得到不正确的结果,必须按照[Low 02]中的描述进行透视校正插值。深度缓冲区值1/z是透视正确的,这允许我们直接在屏幕空间插值而无需任何进一步的计算。
我们可以通过将深度缓冲区作为颜色值来输出,并使用Microsoft HLSL中的ddx和ddy指令获取它们的偏导数、梯度等来观察到深度缓冲区在屏幕空间是线性的。对于任何平面表面,结果将是恒定的颜色,这告诉我们在屏幕空间中平面到相机的距离是线性变化率。
任何线性的东西也允许我们线性插值,就像硬件一样,这是一个非常强大的事实。这也是我们在非线性深度缓冲区上进行Hi-Z构造的原因。我们的光线跟踪将发生在屏幕空间中,我们希望利用深度缓冲区值可以在屏幕空间中正确插值的事实,因为它是经过透视校正的,因为透视校正消除了这些值的非线性。
如果希望使用视图空间的Hi-Z缓冲区而不是后投影缓冲区的情况下,必须手动内插Z值,就像透视插值一样设计为1/z。这两种情况都是可行,并且会影响到其它pass,如前所述。我们假设从现在开始我们使用透视后的Hi-Z。现在我们知道我们可以在屏幕空间中做深度缓冲区的插值,之后可以回到Hi-Z光线追踪算法本身,并使用我们的Hi-Z缓冲区。
我们可以参数化我们的光线追踪算法,来利用深度缓冲区可以插值的事实。设O是我们的起始屏幕坐标的原点,让矢量D为我们的反射方向,最后让我们的参数在0~1之间变化,它在起始坐标O和结束坐标O+D之间进行插值。
![]()
其中向量D和点O可以如下定义:

D可以从各个方向延伸到远裁剪面。结果除以![]() 可将Zcoordinate设置为1.0,但它仍然指向相同的方向,因为除以标量不会改变向量的方向。然后O将设置为对应于0.0深度的点,即近平面。我们可以把它想象成一条从近平面到远平面的反射方向形成的线,穿过我们图4.11中标亮的点。
可将Zcoordinate设置为1.0,但它仍然指向相同的方向,因为除以标量不会改变向量的方向。然后O将设置为对应于0.0深度的点,即近平面。我们可以把它想象成一条从近平面到远平面的反射方向形成的线,穿过我们图4.11中标亮的点。

图4.11 等式中O,D,P,V变量的图示。O + D * t 将使我们取得起点O和终点 O + D 之间的任何地方,其中t在0到1之间。注意V是矢量方向,它并没有位置。
我们现在可以输入任何值t,使我们在屏幕空间中的Ray-match算法起点和终点之间。t值将是我们的Hierarchical-Z缓冲区的一个函数。
但我们需要首先计算向量V和P来获得O和D。通过屏幕/纹理坐标和深度,我们已经可以得到P。为了得到V,我们需要另一个屏幕空间点![]() ,它对应于反射方向的某个点。利用这两者的不同得到一个屏幕空间的反射向量:
,它对应于反射方向的某个点。利用这两者的不同得到一个屏幕空间的反射向量:
![]()
其中已知的点P可定义为:
![]()
可以通过取视图空间的点、方向和表面法线来计算沿反射方向的另一个点![]() ,以计算视图空间的反射点,并将其投影到裁剪空间[-1,1] 范围内,最后从裁剪空间转换为屏幕空间[0,1]范围,如下所示:
,以计算视图空间的反射点,并将其投影到裁剪空间[-1,1] 范围内,最后从裁剪空间转换为屏幕空间[0,1]范围,如下所示:

一旦我们有了一个屏幕空间的反射向量,我们就可以使用O,D和t沿着加速结构运行HI-Z遍历来做Ray match。
我们首先来看一下清单4.2中的伪代码。该算法使用我们之前构建的Hi-Z缓冲区来加速Ray match。可参照图4.12的操作来可视化清单4.2中的算法。一旦开始运行Ray match算法,我们在屏幕空间中的新坐标就是我们的光线交叉点。一些想法借鉴了文献中的位移映射技术,一个主要的区别是我们从根级开始,而位移技术从叶级开始Ray match。由于我们不得不手动内插Z坐标,因为无法在屏幕空间插入Z坐标,因此使用视图空间Z buffer做Ray match会更加复杂。
level = 0 // starting level to traverse from
while level not below N // ray-trace until we descend below the root level defined by N,demo use 2
minimumPlane = getCellMinimumDepthPlane(...)
// reads from the Hi-Z texture using our ray
boundaryPlane = getCellBoundaryDepthPlane(...)
// gets the distance to next Hi-Z cell boundary int ray direction
closestPlane = min(minimumPlane, boundaryPlane)
// gets closest of both planes
ray = intersectPlane(...)
// intersects the closest plane, returns O + D * t only.
if intersectedMinimumDepthPlane
// if we intersected the minimum plane we should go down a level and continue
descend a level
if intersectedBoundaryDepthPlane
// if we intersected the boundary plane we should go up a level and continue
ascend a level
color = getReflection(ray) // we are now done with the Hi-Z ray marching so get color from the intersection
List4.2 Hi-Z光线追踪的伪代码

图4.12 Hi-Z光线追踪一步一步地在缓冲层次结构中上下移动,以在每一步进行更长时间的跳跃。
预卷积 Pass
预卷积pass适用于计算从微观粗糙表面发射的模糊光泽反射的算法的基本pass。就像输出图像层次结构的Hi-Zpass一样,这个pass也是如此,但是考虑了不同的目标。
我们将原始场景颜色缓冲区做卷积,以产生几个不同的模糊版本,如图4.13所示,最终结果是另一个分层表示。不同分辨率的图像具有不同的卷积级别,存储在mip-map通道中。
这些模糊的颜色缓冲区将有助于加速粗糙反射,以获得类似于图4.14所示的结果。

图4.13 卷积颜色纹理的简单场景。每个级别的卷积层级不同,这将在以后用于创建我们的粗糙反射。
通常为了模拟基于光线追踪的渲染中的这种模糊反射,我们会记录很多由锥形光圈定义的发散光线,比如32个,并将所得到的颜色平均后产生模糊的反射(见图4.15和4.16)
然而,这一操作非常昂贵,并且性能会随着我们记录的光线数量线性减少。即便是如此,该技术也会产生噪声以及不可接受的结果,需要进一步处理才能平滑。一种这样的技术被称为图像空间采集,它即使在纯镜面反射上也能很好地工作,使它看起来像后期处理的粗糙反射。

图4.14 球体上不同程度的粗糙度产生发散的反射光线,这导致观察者感知到了模糊的反射。
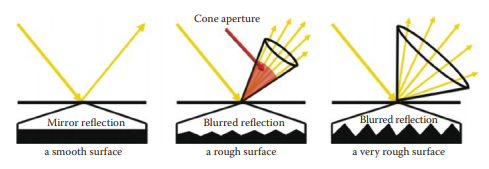
图 4.15 表面在微观层面越粗糙,反射越模糊和微弱。较少的光线照射到眼睛虹膜上,得到了一个较为模糊的外观。
在锥孔内记录随机抖动射线的另一个缺点时,诸如GPU的并行计算硬件倾向于以组/批的形式来运行线程和存储器事务。如果我们引入抖动光线,我们就会减慢硬件速度,因为所有的内存事务都在相互远离的内存地址中,由于缓存未命中和全局内存提取导致计算速度变慢,带宽成为瓶颈。

图4.16 通过产生多个发散光线来产生有噪声的反射,并对结果求平均来产生光滑反射。即使每像素32条光线也不足以产生完美平滑的反射,并且性能会随着额外的光线线性减少。
4.4.5节将提出一种近似方法,但运行速度非常快,无需发射多条射线或进行抖动。通过在此pass中我们讨论的模糊彩色图像层级结构中导航,并根据我们反射表面的反射距离和粗糙度,我们可以产生精确的光泽反射。
锥形追踪 Pass
锥形追踪Pass在Hi-Z光线追踪Pass完成后立即运行,并产生光泽反射。此pass种使用我们所有的分层缓冲区。
如前所述,光线追踪Pass的输出是我们屏幕空间的交点坐标。有了这个,我们可以构建一个屏幕空间对齐的椎体,它相当于一个等腰三角形。
这个想法很简单:图4.17显示了一个屏幕空间中的圆锥体,它对应于地板在最大程度上散射反射光线的程度。我们的目标是累加该椎体内的所有颜色,整合每一条发散的光线。这种积分可以通过在圆心处进行采样来近似,其中圆的大小决定了我们从纹理中读取颜色的层次级别,如4.4.3节所述。图4.18也说明了这一点。

图4.17 屏幕空间中的圆锥基本上是等腰三角形,其半径为原型,能够采样/读取分层缓冲区。
我们需要确定椎体是否与我们的Hi-Z相交。如果相交,我们确定它相交多少,并将此权重乘以为此层的点预计算的可见性。最终的权重将会积累到100%,我们在遍历的过程中计算颜色样本的权重。我们确定椎体是否在空白空间与Hi-Z相交的方式很大程度上取决于我们使用的是后投影Hi-Z还是视图空间Hi-Z。

图4.18 椎体整合了光线、箭头。我们可以根据距离和表面粗糙度,通过在卷积、模糊后的彩色图像的不同层级进行采样、读取来观察图像。它在相邻像素和层级结构级别之间进行融合,这就是我们所说的平滑过渡和混合结果的三线性插值。
首先,我们需要找到特定粗糙度水平的锥角。我们的反射向量基本上是Phong反射模型,因为我们只是通过反射法线上的视线方向来计算反射向量。为了近似Phong模型的锥角,我们使用:
![]()
其中α是镜面反射率,ξ硬编码为0.244。这是用于镜面反射的重要性采样的基本公式,它是Phong分布的逆累积分布函数。重要性采样应用为ξ生成的一维均匀随机变量[0 - 1],并且使用了上述公式在球面坐标中的镜面椎体内生成的随机光线方向。硬编码值0.244似乎是一个很好的数字,它覆盖了一定范围的锥角范围。图4.19显示了该方程在极坐标中如何映射到Phong镜面椎体的锥角范围。

图4.19 具有各种镜面反射功率值的镜面椎体的极坐标图。红色椭圆是镜面椎体,黑色等腰三角形使用前面给出的公式显示的锥角度范围;α 是角度,cos α 是不同镜面的能量值。
要使用Phong模型获得完美的镜像光线,镜面反射功率值必须是无穷大。由于这在现实中是不会发生的,应用程序也通常会对镜面反射功率值设置上限,因此我们只需要一个阈值来支持锥形跟踪器的镜面反射。我们可以很清楚地看到1024和2048之间的功率没有太大的变化。因此,1024到2048范围内的任何镜面反射功率都应该内插到0角度。
如果我们想要另一种具有更复杂分布的反射模型,我们需要预先计算一个2D查找表并将其粗糙度作为u坐标并将V·N作为v坐标进行索引,然后返回局部反射方向。需要将局部反射方向转换为Hi-Z追踪Pass的全局反射方向。
因此,对于任何分布模型,我们在预计算的时候平均在镜面椎体的所有反射向量——使用[0,1]随机变量重要性采样——找到具有给定反射向量最强向量的特定粗糙度值。然后,我们将此向量存储在2D纹理表中。我们在椎体内平均所有反射向量的原因是,复杂的BRDF模型通常不产生相对于纯镜面反射的椎体。它们有可能在垂直方向上更加垂直或在掠射角度上表现不同,我们要找到这个镜面椎体内最强的反射向量,这可以在图4.20中清楚看到。

图4.20 用于复杂分布镜面椎体的球面坐标预览。我们可以清楚地看到,叶片不一定需要以纯反射向量为中心。如果我们平均在叶片内的所有向量,我们将得到一个新的反射向量R,它更准确地代表了我们的反射向量。
此表格中的RGB通道包含了局部反射向量,并且alpha通道包含了具有单个值的各向同性锥角度范围或具有两个值的各向异性锥角度范围,以实现垂直拉伸的反射,我们稍后将重新考虑这一点。
在本章中,我们假设我们使用Phong模型。我们需要使用新获得的角度θ为锥形追踪pass构造等腰三角形。设P1为屏幕空间中光线的起始坐标,P2为屏幕空间中光线的终点坐标,那么长度l将定义为:
![]()
一旦我们得到了交点的长度,我们可以假设它是我们等腰三角形的相邻边。通过一些简单的三角函数,我们可以计算出对边。三角法表示下θ的正切是相邻边的对边。
![]()
使用一些简单的代数,我们发现我们在寻找的另一边就是θ 乘以相邻边的正切。
![]()
但是,这仅适用于直角三角形。对于等腰三角形而言,它实际上是两个直角三角形在相邻一侧拼合而成,其中一个被翻转。这意味着对边实际上是直角三角形的两倍:
![]()
一旦我们同时具有相邻侧和相对侧,我们就拥有了计算锥形跟踪Pass的采样点所需的所有数据(见图4.21)。

图4.21 等腰三角形带有锥形追踪pass中屏幕空间的采样点。要在屏幕空间中找到椎体的样本点,我们必须使用一些几何体并计算此等腰三角形的半径。请注意,这是一个近似值,我们并没有完全整合整个椎体。
要计算等腰三角形的半径(圆半径接触三侧),可以使用以下公式:

其中a是等腰三角形的底边,h是等腰三角形的高度,r是计算得到的半径。回想一下,等腰三角形的高度是我们之前计算的交点的长度,而等腰三角形的底边是相反的一侧。使用此公式,我们就找到了内接圆的半径。一旦我们得到等腰三角形的半径,我们可以取相邻边并从中减去半径,来找到我们感兴趣的采样点。现在我们可以从屏幕空间中的正确坐标来读取颜色。
为了计算其余的采样点,我们所要做的就是在半径中再减一次以到达圆的最左边,然后使用公式![]() 重新计算这个新的邻边的相对边,再使用内接圆公式得到下一个较小的圆圈。我们为我们想要得到的样本多次执行这一过程。
重新计算这个新的邻边的相对边,再使用内接圆公式得到下一个较小的圆圈。我们为我们想要得到的样本多次执行这一过程。
我们通过使用三线性滤波方案(在相邻像素之间和层级之间平滑过滤)来累积得到正确的颜色。我们还根据我们的椎体和深度单元相交的程度,来混合透明度缓冲区的颜色权重。这是按照从前到后的顺序完成的,因此基本上可以认为它是一种线性搜索算法。椎体越大,运行则越快。通过累加权重来得到整合后的可见度。
人们可能希望在圆圈之间采用较小的偏移以获得更加平滑的结果,然而,这会使得计算量增加。如果锥形追踪器无法累积100%的可见度,我们可以使用具有相同粗糙度的立方体贴图来混合其余可见性。这里同样也会取决于Hi-Z缓冲区的格式:如果我们使用视图空间的z,那么我们要确定椎体-球体是否与Hi-Z缓冲区相交,以及计算椎体上的采样点的方式是不一样的。我们可以使用锥角和视图控件z距离来查找球体大小,然后使用透视划分将其投影到屏幕空间中,同时保持纵横比。
实现
Hi-Z Pass
清单4.3中的代码片段显示了如何使用HLSL在DirectX中实现Hi-Z构造pass。该着色器将会连续质心,结果存储在Hi-Z缓冲器的mip通道中。我们从N-1级读取并写入N,直到我们达到第4.4.1节中提到的1x1大小。
要渲染我们在DirectX中读取的相同纹理,我们必须确保我们的ID3D11ShaderResourceView对象指向单个mip通道而不是整个mip通道范围。同样的规则也适用于我们的ID3D11RenderTargetViews对象。
(我们每次使用不同的偏移值来对深度值进行采样。我们使用点采样以消除硬件的双线性过滤。常量preLevel是一个全局变量,应用程序使用整数来指定每次连续执行时从哪个级别来采样深度值,它对应着前一个级别)
float4 main(PS_INPUT input) : SV_Target
{
// Texture/image coordinates to sample/load/read the depth values with
float2 texcoords = input.tex;
// Sample the depth values with different offset each time.
// We use point sampling to ignore the hardware bilinear filter.
// The constant prevLevel is a global that the application feeds
// with an integer to specify which level to sample the depth values
// from at each successive execution. It corresponds to the previous
// level.
float4 minDepth;
minDepth.x = depthBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,0));
minDepth.y = depthBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,-1));
minDepth.z = depthBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(-1,-1));
// Take the minimum of the four depth values and return it.
float d = min(min(minDepth.x, minDepth.y), min(minDepth.z, minDepth.w));
return d;
}List 4.3 实现从深度缓冲区获取最小2x2深度值的Hierarchical-Z缓冲区
预整合 Pass
清单4.4中的代码片段显示了如何使用HLSL在DirectX中实现预整合Pass。它计算深度单元格的最小值和最大值内的空白空间所占百分比,并根据之前的透明度进行调制。
float4 main( PS_INPUT input) : SV_Target
{
// Texture/image coordinates to sample/load/read the depth values with.
float2 texcoords = input.tex;
float4 fineZ;
fineZ.x = linearize( hiZBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int2(0,0).x );
fineZ.y = linearize( hiZBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int(0,-1).x );
fineZ.z = linearize( hiZBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int(-1,-1).x );
// hiZBuffer stores min in R and max in G.
float minZ = linearize( hiZBuffer.SampleLevel( pointSampler, texcoords, mipCurrent).x);
float maxZ = linearize( hiZBuffer.SampleLevel( pointSampler, texcoords, mipCurrent).y);
// Pre-divide
float coarseVolume = 1.0f / (maxZ - minZ);
// Get the previous four fine transparency values.
float4 visibility;
visibility.x = visibilityBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int2(0,0) ).x;
visibility.y = visibilityBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int2(0,-1) ).x;
visibility.z = visibilityBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int2(-1,0) ).x;
visibility.w = visibilityBuffer.SampleLevel( pointSampler, texcoords, mipPrevious, int2(-1,-1) ).x;
// Calculate the percentage of visibility relative to the calculated coarse depth. Modulate with transparency of previous mip.
float4 integration = fineZ.xyzw * abs(coarseVolume) * visibility.xyzw;
// Data-parallel add using SIMD with a weight of 0.25 because we derive the
// transparency from four pixels
float coarseIntergration = dot( 0.25f, intergration.xyzw );
return coarseIntegration;
}List 4.4 该demo同时使用了最小的Hi-Z缓冲区和最大的Hi-Z缓冲区。使用它们,我们可以计算层次结构深度单元格之间有多少空白空间。我们将后投影的深度线性化为视图空间的z来进行计算。我们还可以在Hi-Z pass期间输出线性Z缓冲区,但是这需要在光线追踪Pass和锥形追踪Pass中做一些修改,因为默认情况下我们无法在屏幕空间插值视图空间z。
光线追踪 Pass
清单4.5中的实现是HLSL中的Hi-Z光线追踪代码。代码片段注释很多,一旦理解清楚4.4.3节中介绍的算法,就应该很容易理解。
float3 hiZTrace( float3 p, float3 v )
{
const float rootLevel = mipCount - 1.0f; // Convert to 0 based indexing
float level = HIZ_START_LEVEL; // HIZ_START_LEVEL was set to 2 in the demo
float interations = 0.0f;
// Get the cell cross direction and a small offset to enter the next cell when doing cell crossing
float2 crossStep, crossOffset;
crossStep.x = ( v.x >= 0 ) ? 1.f : -1.f;
crossStep.y = ( v.y >= 0 ) ? 1.f : -1.f;
crossOffset.xy = crossStep.xy * HIZ_CROSS_EPSILON.xy;
corssStep.xy = saturate( crossStep.xy );
// Set current ray to the original screen coordinate and depth
float3 ray = p.xyz;
// Scale the vector such that z is 1.0f (maximum depth)
float3 d = v.xyz /= v.z;
// Cross the next cell so that we don't get a self-intersection immediately.
float2 rayCell = getCell(ray.xy, hiZSize.xy);
ray = intersectCellBoundary( o.xy, d.xy, rayCell.xy, hiZSize.xy, crossStep.xy, crossOffset.xy);
// The algorithm loop HIZ_STOP_LEVEL was set to 2 in the demo; going too high can create artifacts.
[loop]
while( level >= HIZ_STOP_LEVEL && interations < MAX_ITERATIONS )
{
// Get the minimum depth plane in which the current ray resides.
float minZ = getMinimumDepthPlane( ray.xy, level, rootLevel);
// Get the cell number of our current ray.
const float2 cellCount = getCellCount(level, rootLevel);
const float2 oldCellIdx = getCell(ray.xy, cellCount);
// Intersect only if ray depth is below the minimum depth plane.
float3 tmpRay = intersectDepthPlane( o.xy, d.xy, max(ray.z, minZ));
// Get the new cell number as well.
const float2 newCellIdx = getCell(tmpRay.xy, cellCount);
// If the new cell number is different from the old cell number,
// we know we crossed a cell.
[branch]
if ( crossedCellBoundary( oldCellIdx, newCellIdx) )
{
// So intersect the boundary of that cell instead, and go up
// a level for taking a larger step next loop.
tmpRay = intersectCellBoundary( o, d, oldCellIdx, cellCount.xy,
crossStep.xy, corssOffset.xy);
level = min(HIZ_MAX_LEVEL, level + 2.0f);
}
ray.xyz = tmpRay.xyz;
// Go down a level in the Hi-Z/
--level;
++iterations;
} // end while
return ray;
}List 4.5 由于代码长度受限,某些功能未显示。为简单起见,这只是最小的追踪。可以通过本书网站上的演示代码查看这些功能的完整实现。该demo使用最小/最大追踪,比这要更复杂。视图空间的Z追踪有点复杂,没有演示。
预卷积 Pass
预卷积Pass只是一个简单的可分离模糊,具有归一化的权重,因此当求和时它们加起来等于1.0,否则我们将创建比原有图像更多的能量。(见图4.22)

图4.22 demo中用于加权颜色的归一化高斯曲线
在彩色图象上连续执行滤波,在每一步中,我们将图像缩小到一半大小并将其存储在纹理的mip通道中。假设我们使用半分辨率,这对应着960x540,在第二层卷积(240x135)时,我们从第一层(480x270)读取并应用可分离的模糊通道。
用于计算水平和垂直模糊权重的1D高斯函数是:
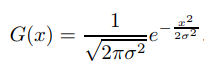
因此,例如,对于7x7的滤波器将包含从-3到3的范围,归一化的高斯权重为0.001,0.028,0.233,0.474,0.233,0.028和0.001,它们求和将精确地等于1.0.
我们不希望在图像中进行局部模糊时会产生更多的能量,而是希望保持图象中的总能量相同,因此当求和时权重必须等于1.0,否则我们将得到更多的能量,导致图像变得更加明亮。列表4.6时一个简单的水平和垂直的高斯模糊实现,使用HLSL着色器语言。
通过首先运行水平模糊pass然后垂直模糊pass,连续在每个级别产生最终的卷积图象,然后将其存储在我们颜色纹理的mip通道中。7x7的滤波器已经能为demo提供较好的效果,使用具有更宽范围权重的高斯核将会导致错误的结果。因为我们的透明度缓冲区和其关联的颜色不再在像素级别上进行匹配。请注意,我们的高斯权重主要来自两个相邻像素的颜色。
// Horizontal blur shader entry point in psHorizontalGaussianBlur.hlsl
float4 main( PS_INPUT input) :SV_Target
{
// Texture/image coordinates to sample/load the color values with.
float2 texcoords = input.tex;
float4 color;
// Sample the color values and the weight by the pre-calculated normalized
// Gaussian weights horizontally.
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(-3,0)) * 0.001f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(-2,0)) * 0.028f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(-1,0)) * 0.233f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,0)) * 0.474f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(1,0)) * 0.233f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(2,0)) * 0.028f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(3,0)) * 0.001f;
return color;
}
// Vertical blur shader entry point in psVerticalGaussianBlur .hlsl
float4 main( PS_INPUT input ) : SV_Target
{
// Texture/image coordinates to sample/load the color values with.
float2 texcoords = input.tex;
float4 color;
// Sample the color values and weight by the pre-calculated normalized
// Gaussian weights vertically.
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,3)) * 0.001f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,2)) * 0.028f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,1)) * 0.233f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,0)) * 0.028f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,-1)) * 0.233f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,-2)) * 0.028f;
color += colorBuffer.SampleLevel( pointSampler, texcoords, prevLevel, int2(0,-3)) * 0.001f;
return color;
}List 4.6 简单的水平和垂直分离模糊滤波着色器,使用7x7内核。
锥形追踪 Pass
锥形追踪Pass是比较小且比较易于理解的pass之一。简而言之,它计算了由锥形构成的三角形的半径以及在我们分层颜色卷积缓冲区和预整合可见性缓冲区中不同级别的样本(参见列表4.7)。有关算法说明,可参阅第4.4.5节,结果如图4.23所示。

图4.23 在屏幕空间中产生光泽反射的锥形追踪算法。注意算法是如何确保光表现得像现实世界一样,从源头反射得越远,它的传播范围也就越广。
// Read roughness from a render target and convert to a BRDF specular power.
float specularPower = roughnessToSpecularPower(roughness);
// Depending on what BRDF used, convert to cone angle. Cone angle is maximum
// extent of the specular lobe aperture.
float coneTheta = specularPowerToConeAngle(specularPower);
// Cone-trace using an isosceles triangles to approximate a cone in screen space
for(int i = 0; i < 7; ++i)
{
// Intersection length is the adjacent side, get the opposite side using trigonometry
float oppositeLength = isoscelesTriangleOpposite(adjacentLength, coneTheta);
// Calculate in-radius of the isosceles triangle now
float incircleSize = isoscelesTriangleInradius(adjacentLength, oppositeLength);
// Get the sample position in screen space
float2 samplePos = screenPos.xy + adjacentUnit * ( adjacentLength - incircleSize );
// Convert the in-radius into screen size (960x540) and then check what power N
// we have to raise 2 to reach it/
// That power N becomes our mip level to sample from.
float mipChannel = log2( incircleSize * max(screenSize.x, screenSize.y) );
// Read color and accumulate it using trilinear filtering (blending in xy and mip
// direction) and weight it.
// Uses pre-convolved image and pre-intergrated transparency buffer and Hi-Z buffer.
// It checks if cone sphere is below, in between, or above the Hi-Z minimum and
// maxamimum and Visibility is accumulated in the alpha channel.
totalColor += coneSampleWeightedColor( samplePos, mipChannel);
if( totalColor.a > 1.0f)
break;
// Calculate next smaller triangle that approximates the cone in screen space.
adjacentLength = isoscelesTriangleNextAdjacent( adjacentLength, incircleSize );
}List 4.7 同样由于代码长度受限没有显示某些功能的完整实现。在线提供的演示代码具有完整的功能,该demo还附带了不同的可替换代码,用于累积颜色,例如基本的平均、基于距离的权重、以及分层的预整合可见性缓冲区权重。
Hi-Z追踪器和锥形追踪器之间存在冲突,Hi-Z尝试尽可能快地找到完美的镜面反射,而锥形追踪器需要采用线性步骤以前后顺序整合总体可见度来获得正确地遮挡。
由于比较复杂,本章并未显示出这一点。但Hi-Z缓冲区实际上和锥角一起使用,以便在比较粗略的水准上更早地退出Hi-Z循环,确定对应的交点。然后,我们再进入锥形追踪pass,继续线性Ray-match来进行光泽反射。Hi-Z用于确定大致的相交空间,一旦我们与椎体有一个粗略的交点,我们就可以直接跳入锥形追踪器,从而将该点的可见性和颜色整合起来。
我们的表面越粗糙,这种技术执行消耗越低,因为我们可以采样更大的圆圈并进行更大的跳跃。相反,表面粗糙程度越低,Hi-Z则要移动的越远,以获得完美的反射。同样,实现机制取决于使用的是后投影Hi-Z还是视图空间Hi-Z。
扩展
平滑淡出的技术
我们已经在第4.2节中讨论了屏幕空间局部反射的一些问题。由于我们在屏幕空间中缺乏可用的信息,在观察光线的相反方向上行进的光线和靠近屏幕边界、屏幕外部的光线应该消失。我们还可以根据光线传播距离来衰减光线。
清单4.8显示了一个快速而简单的实现。demo实现了一个更强大的功能。
人们也可以根据局部遮挡,也就是射线开始在物体后面行进而无法找到合适的交点处逐步淡出。我们在光线进入这种状态时做记录,然后在该状态下淡化光线,以消除一些不必要的特征。
// Smoothly fade rays pointing towards the camera; screen space can't do mirrors
// ( this is in view space)
float fadeOnMirror = dot(viewReflect, viewDir);
// Smoothly fade rays that end up close to the screen edges.
float boundary = distance(intersection.xy, float2(0.5f, 0.5f)) * 2.0f;
float fadeOnBorder = 1.0f - saturate((boundary - FADE_START) / (FADE_END - FADE_START));
// Smoothly fade rays after a certain distance (not in world space for simplicity but should be).
float travelled = distance(intersection.xy, startPos.xy);
float fadeOnTravel = 1.0f - saturate((travelled - FADE_START) / (FADE_END - FADE_START));
// Fade the color now.
float3 finalColor = color * (fadeOnBorder * fadeOnTravel * fadeOnMirror);List 4.8 减弱很可能失败并计算不正确反射结果的光线的代码片段。FADE_START和FADE_END控制衰减的速度,取值在0到1之间。虽然代码片段对两种衰减方式使用了相同的参数,但是应该使用不同的参数并调整它们。
表面的膨胀
由于Ray-match有可能找不到真正的交点,我们可以推断丢失的信息。假设屏幕上覆盖着大部分具有光泽反射的粗糙表面,我们可以运行双边膨胀滤波器,这意味着在膨胀时缺失颜色时(即,填充孔洞)将表面法线和深度考虑在内。对于粗糙表面以外的任何表面,由于潜在的高频反射颜色,膨胀滤波器可能会失败。
提高Ray-match的精度
如我们所知的,如果我们使用非线性后投影深度缓冲区,大多数深度值会非常快地下降到0.9到1.0之间。为了提高Ray-match的精度,我们可以反转深度缓冲。这是通过交换投影矩阵中的近平面和元平面来完成的,将深度测试改为大于等于而不是小于等于。然后,我们可以将深度缓冲区清除为黑色而非白色,因为0.0是远处平面的位置。在深度缓冲区中,将1.0转为近平面,0.0转为远平面。这里存在两处非线性,一个是后透视深度,一个是由于浮点数,由于我们反转了其中一个,它们两个基本上相互抵消,是我们能够更好地分配深度值。
请记住,反转深度缓冲区也会影响我们的Hi-Z构造算法。
我们应该始终使用32位浮点深度缓冲区,在AMD硬件上,24位和32位深度缓冲区的内存占用量是相同的,第四代控制台也配备了这种缓冲区。
另一种可用于提高深度精度的技术是在视图空间z深度缓冲区上创建实际的Hi-Z缓冲区。我们需要在几何pass中将其输出到单独的渲染目标中,因为从后透视深度恢复这一数据不会提升精度。这为我们提供了均匀分布的深度值。视图空间z深度缓冲区的唯一问题是,由于它不是后透视,我们无法在屏幕空间中进行插值。要进行插值,我们必须使用与硬件插值相同的技术。我们取1/z并在屏幕空间中对其进行插值,然后将该插值再次除以1/Z来恢复最终的插值视图空间z。但是,输出专门的线性空间z缓冲区成本太高,我们应该首先选用反向的32位浮点深度缓冲区。
视锥空间z缓冲区的锥形追踪计算也有点不同。我们需要将球体投射回屏幕空间,以找到它在特定距离处覆盖的大小。
近似多射线反射
在实际反射中,多次反射是一个重要因素。如果镜子的反射本身没有反射,我们的大脑就会立即注意到出了问题。我们可以在图4.24中看到多次反射的影响。

图4.24 当两个镜子彼此平行时会无限反射,反射强度会随着吸收导致的反射次数而减少,其中光被转换为热量而反射回来。结果是在更远的光线深度处有更暗的反射。请注意绿色的色调,由于普通钠钙玻璃中的氧化铁杂质,光线会随着时间的推移在玻璃中积聚,绿色色调通常在玻璃边缘最明显。
本章介绍的算法能够相对容易进行多次反射,并具有良好的特性。这个想法是反射已经反射过的图像。在这种情况下,已经反射的图像将是上一帧。如果我们计算已经反射的图像的反射,我们将随着时间累积多次反射(见图4.25)。但是由于我们总是按帧延迟原图像,我们必须重新投影像素。为了实现这种重新投影,我们将摄像机的运动考虑在内,将当前帧的像素转换为它前一帧中所属的位置。

图4.25 重新投影已经反射的图像并将其用作当前帧的源的效果。这会产生多次反射,就像在现实世界中一样,反射次数越多,强度越弱。
一旦我们知道它在前一帧中的位置,我们还需要检测该像素是否有效。比如,有些像素可能已经移除屏幕边缘,有些可能已被遮挡等。如果相机在前一帧和当前帧之间存在大幅移动,我们可能不得不舍弃某些像素。最简单的方法是存储前一帧的深度缓冲区,一旦我们将像素重新投影到前一帧,我们只需用epsilon比较它们并检测成功还是失败。如果它们不在epsion值内,我们知道该像素无效。为了获得更精确的结果,还可以使用前一帧的法线(表面方向)和重新投影像素的法线。该demo仅使用深度来舍弃无效的像素。
从数学上来讲,我们需要使用当前的摄像机投影矩阵和之前的摄像机投影矩阵的倒置将我们从当前帧的像素转移到前一帧:
![]()
其中M是级联的重投影矩阵,![]() 是当前帧的逆视图投影矩阵,
是当前帧的逆视图投影矩阵,![]() 是前一帧的视图投影矩阵。当与裁剪空间中的像素Pn相乘时,这将把我们带到同一空间中的前一帧中的对应像素Pn-1。我们只需要将结果与w分开,最后得到裁剪空间的坐标。然后我们可以将其映射到屏幕空间,并从前一帧的颜色缓冲区读取,从而得到无限数量的反射。图4.26和清单4.9显示了将像素重新投影到前一摄像机像素位置的概念。
是前一帧的视图投影矩阵。当与裁剪空间中的像素Pn相乘时,这将把我们带到同一空间中的前一帧中的对应像素Pn-1。我们只需要将结果与w分开,最后得到裁剪空间的坐标。然后我们可以将其映射到屏幕空间,并从前一帧的颜色缓冲区读取,从而得到无限数量的反射。图4.26和清单4.9显示了将像素重新投影到前一摄像机像素位置的概念。

图 4.26 通过重投影将屏幕空间中的像素转换为旧坐标,它可用于从先前的颜色缓冲区中读取。
float2 texcoords = input.tex.xy;
// Unpack clip position from texcoords and depth
float depth = depthBuffer.SampleLevel(pointSampler, texcoords, 0.0f);
float4 currClip = unpackClipPos(texcoords, depth);
//Unpack into previous homogenous coordinates
// inverse(view projection) * previous(view projection).
float4 prevHomogenous = mul(currClip, invViewPrjPrvViewProjMatrix);
// Unpack homogenous coordinate into clip-space coordinate.
float4 prevClip = float4(prevHomogenous.xyz / prevHomogenous.w, 1.0f);
// Unpack into screen coordinate [-1,1] into [0,1] range and flip the y coordinate.
float3 prevScreen = float3(prevClip.xy * float2(0.5f,-0.5f) + float2(0.5f,0.5f), prevClip.z);
// Return the corresponding color from the previous frame.
return prevColorBuffer.SampleLevel(linearSampler, prevScreen.xy, 0.0f);
List 4.9 将像素重新投影到前一帧彩色图像中的原本位置。省略了舍弃像素的实现细节,demo包含了完整的代码。
使用前一帧的另一个好处是我们可以考虑最终照明和所有透明对象的信息,以及应用于图像后处理的可能性。如果我们使用的是当前未完成的帧,我们则将缺少这些效果——虽然并非所有的后处理效果都很有趣。
如果你有一个运动模糊速度矢量需要传递,更具体地说是2D瞬时速度buffer,你可以直接使用它而不是使用上面的代码做重新投影。使用2D瞬时速度会更加稳定,但这不在本章的讨论范围内。
时域滤波
时域滤波器是另一种增强器,它通过尝试在几个帧上恢复和重用像素,来帮助算法产生更准确和稳定的结果,由于名称是包含时域的,所以该算法要随着时间的推移累积。我们的想法是构造一个存储旧反射计算的历史缓冲区,然后就像在4.6.4节中看到的那样对它进行重新投影传递,并拒绝无效像素。这个历史缓冲区与我们最终反射计算的缓冲区相同,因此它就像一个累积缓冲区,我们不断累积有效的反射颜色。
如果Ray-match阶段未能找到合适的交叉点,由于光线落在对象后面或者屏幕外部,我们可以依赖于先前已经存储在历史缓冲区中的重新投影结果,并且具有恢复丢失像素的机会。
时域滤波有助于得到稳定的结果,因为我们可以从帧N-1恢复由于遮挡或丢失信息导致的帧N中的失败像素,帧N-1通过重新投影像素而累积在若干帧上。可以恢复在先前帧有效但在当前帧无效的像素是必要的,并且将提供更好的结果、更稳定的算法。如果恢复足够准确,那么也可以通过不运行Ray-match代码来获得更大的加速,这样我们就不需要重新计算反射了。
这个小小的增强器与第4.6.2节中的多射线反射可以一并使用,因为两者都依赖于重新投影。
表面之下的遍历
可以使用最小和最大Hi-Z缓冲区在物体之后行进。如果光线穿过一个单元并落在新单元的最小和最大深度之后,我们也可以穿过该单元并继续进行Hi-Z遍历。这里假设表面没有无限长的深度。也可以使用全局小epsilon值,或者将每个对象厚度epsilon值用于渲染目标。如果我们没有关于物体厚度的信息,在物体后行进将会是一个难以解决的问题。
相机前的Ray-match
我们研究了使用最小Hi-Z层次结构的算法,让光线远离相机。镜像反射光线也可能朝向相机传播,从而有可能击中某些物体,尽管这种可能性非常小,并且大多在曲面上。算法需要进行一些小的改动,对于想要向相机传播的任何光线,使用额外的层次结构,即最大Hi-Z。
使用像R32G32F的纹理格式,R通道将存储最小值而G通道将存储最大值。
有一小部分像素有可能会实际碰到某些东西,所以这种改变可能不值得,因为这会增加整个算法的开销。
垂直拉伸的各向异性反射
在现实世界中,我们在光泽表面上看到的掠射角越多,我们感知的各向异性反射就越多。基本上反射波瓣内的反射向量传播方向更偏向垂直,这就是我们获取垂直拉伸效应的主要原因。
为了实现屏幕空间反射的现象,我们必须在反射颜色的锥形追踪累积过程中使用我们的颜色纹理的SampleGrad函数,给这个采样器硬件一些自定义计算的垂直和水平偏导数,并让硬件做各向异性过滤并为我们做拉伸反射。这很大程度上取决于我们所使用的BRDF以及粗糙度值如何映射到反射波瓣。
我们也可以手动取多个样本来获得相同的结果。基本上,我们不是采样四边形,而是以掠射角度对细长矩形进行采样。
我们在4.4.5节中已经看到,对于复杂的BRDF模型,我们需要预先计算局部反射矢量和锥角的2D表。适合这种情况的纹理是R16G16B16A16。RGB通道将存储局部适量,并且alpha 通道将存储一个各向同性锥角范围或两个各向异性垂直和水平锥角范围。椎体的这两个各向异性值将决定我们将垂直采样多少额外样本,来近似细长矩形以拉伸反射。
优化
结合线性和Hi-Z遍历
Hi-Z遍历的一个缺点是当光线靠近表面时它将向下遍历到较低的层次级别。对于这样的小步骤,评估整个Hi-Z遍历算法比使用相同步长进行简单线性搜索更加昂贵。不幸的是,光线将会立即开始靠近我们正在反射原始射线的表面。在开始的时候执行几个线性搜索步骤是一个很好的优化,可以让光线远离表面,然后让Hi-Z遍历算法完成它的工作。
如果通过线性搜索找到了交叉点,我们可以使用动态分支在着色器代码中提前输出并跳过整个Hi-Z遍历的阶段。我们应该尽可能在早的水平结束Hi-Z遍历,比如1到2层级时,然后继续进行另一次线性搜索。结束的层级可以根据到相机的距离来计算,因为距离像素越远,透视所需的细节越少,因此更早停止会提高性能。
改善获取延迟
部分展开动态循环以处理依赖纹理提取倾向于使用提取/延迟绑定算法来提高性能。因此,我们实际上预先为下一个N循环做了预提取工作,而不是每个线程处理一个工作。我们可以这样做是因为我们的光线上有一条确定的路径。然而,预提取会损害性能,因为寄存器使用率上升并且使用更多的寄存器意味着更少的线程桶可以并行运行。一个比较好的起点是N = 4。该值常用于常规线性追踪算法,并且能在NVIDIA和AMD硬件上检测到2x-3x的加速。本章后面出现的数字不包括这些改进,因为它没有在HI-Z追踪器上进行测试。
交错空间相干与信号重建
因为大多数光线都是空间相干的,所以我们可以每隔一个像素记录光线——也就是所谓的交错采样——然后从采样理论中应用某种信号重建滤波器。这对于粗糙反射非常有效,因为结果往往具有低频率,这对于信号重建而言是理想的。这是在基于线性追踪的算法上测试的,并且实现了约3x-4x的性能增加。交错模式是水平两次、垂直两次。这些改进也未在Hi-Z追踪器上进行测试,因此后面提供的数字也不包括这些内容。
跨双边上采样或时域超采样
由于我们以半分辨率运行光线追踪,因此我们需要一种智能上采样方案来弥补缺少的像素数。交叉双边图像上采样算法非常适合这种任务,而时域超采样效果会更好;在四帧之后,我们将使用前面解释的时间重新投影来获得全分辨率追踪结果。对于交叉双边上采样器,全分辨率深度缓冲器将与半分辨率反射颜色缓冲器一起作为输入。该算法将反射颜色缓冲区上采样到全分辨率,同时保留轮廓和硬边缘。计算半分辨率的反射比全分辨率更快、更便宜。但是,要将图像重新组合回原始屏幕,在全分辨率下,我们需要在保留硬边缘的同时进行缩放,而这正是跨双边上采样算法的优点。
虽然上采样也可以采用另一种方法,并将深度不连续处的像素附加到追加/消耗缓冲区,并在之后以高分辨率重新追踪那些像素来获得高质量。但这没有经过测试。
性能
该demo以半分辨率运行,意味着960x540,并且运行速度很快:
• NVidia GTX TITAN上0.35-0.39毫秒,
• NVidia GTX 670上0.70-0.80毫秒,
• AMD 7950上0.80-0.90毫秒。
定时器是Hi-Z Ray-Marching和Cone-Tracing的组合。
该demo有内存延迟限制,内存单元的有效率为80~90%,这使得我们的ALU单元几乎没有空间可以工作,因为它们只是在那里等待完成提取。
根据 GPU PerfStudio2,我们还有50%的缓存未命中,因为使用Hi-Z加速结构遍历时访问了非局部纹理缓冲区,并且我们还受到了非相干动态分支的影响,因为GPU以锁步模式执行分支。如果整个存储桶线程(Nvidia的32个线程组称为Warp,64个用于AMD的线程称为Wavefront)不采用相同的分支,我们就需要承受停止某些线程的代价,直到它们再次汇聚到同一道路上。随着线程不断地为某些像素采用不同的分支,这会变得更糟。
有一个未经尝试的优化,Tevs等人提出可以用3D纹理存储Hi-Z,而不是2D纹理。根据Tevs等人的说法,使用3D纹理进行位移映射技术,其中每个切片代表我们的Hi-Z层次级别,由于较少的L2流量和更多的纹理缓存命中,这能提供更好的缓存命中和20%的性能提升。
由于缓存未命中和非相干纹理访问导致的内存延迟受限,会使得在层次结构中上下跳跃。以上优化可能是一个很好的优化尝试,尽管它会使用更多的内存。
结果
我们提出的算法运行得非常好,并产生了很好的反射,既有镜面反射也有光泽,并且它以可接受的速度运行。最引人注入的细节是反射的扩散,因为它们离光源越来越远,这是整个算法的亮点。(见图4.27和4.28)

图4.27 在瓷砖材料上具有不同光泽度的锥形追踪算法,给出了发散的反射光线的外观。反射变得越来越远,它就像我们在现实世界中看到的现象一样伸展。

图4.28 另一个Hi-Z屏幕空间椎体追踪的例子,由于使用材料粗糙度的不同,它产生的散射反射越远。
结论
在本章中,我们研究了Hi-Z屏幕空间锥形追踪,以计算游戏交互式帧率和性能良好的镜面反射和光泽反射。虽然该算法适用于局部反射,但由于屏幕上的信息不足,可能会出现一些边缘情况。正如我们所看到的,该算法只能反映原始输入图像的内容。
也就是说,我们无法从镜子中看到自己,因为我们在屏幕空间中无法获得该信息。Hi-Z屏幕空间锥形追踪是动态3D场景中动态反射的补充效果,具有比较廉价的光泽外观,建议可以将其余其它类型的反射技术相结合,如在Hi-Z执行失败后使用盒形或球形立方体贴图。由于屏幕空间算法存在固有问题,Hi-Z屏幕空间锥形追踪不应该单独使用,除非你有一个非常具体的受控场景和特定的摄像机角度,你可以避免以上问题,如平坦的墙壁且没有镜子灯。光泽反射有助于隐藏镜面反射可见的伪影。
以后的工作
该系统可以通过多种方式进行扩展。一个想法是拍摄3D场景的屏幕截图并将颜色和深度信息与相机一起存储。有了这个,我们可以在运行时重新投影这个本地屏幕截图,而无动态对象模糊。屏幕截图就行本地反射探测器一样,我们会选择最接近的一个进行Hi-Z遍历。
Hi-Z屏幕空间追星追踪技术也可应用于立方体贴图,我们在此立方体体积内构建立方体映射的Hi-Z加速结构和Ray-match。这将允许我们反映屏幕外的任何内容以及完美的光线追踪效果。这项技术称为Hi-Z Cube-Map Ray Tracing,目前正在进行研究,并将在稍后发布。
另一个扩展是数据包追踪。这也是正在进行的研究,将在稍后发布。基本的想法是将几条光线组合在一起,我们捕获一束光线,就像截取锥体一样。当我们与粗略的Hi-Z相交时,我们可以细分数据包并捕获到更多的光线。
通过这种方式,我们可以快速地获取粗略Hi-Z级别的交点,然后我们在行进的时候会执行更少的操作,但这会使得实现更复杂,更难以维护并严重依赖主搜额器。对相干光线分组应该可以极好的提高性能。
我们还可以进行平铺追踪,其中每个平铺块标识着场景的粗糙度值,如果整个平铺块非常粗糙,我们可能会减少捕获的光线并推断大部分的像素颜色。这种多分辨率处理也会极大地提高速度,但同样也很大程度上依赖于计算着色器。
所有这些主题都是正在进行的研究,如前所述,如果它已经跨过研究和开发阶段,将在稍后发布。