版权声明:转载请注明出处 https://blog.csdn.net/qq_42292831/article/details/88911494
决策函数:(其中需要对数据x进行预处理)
![]()
损失函数L :
![]()
样本总体损失函数:(在已知训练样本(经验E)的基础上计算出来的一个综合指标,也称为经验风险)

评估:找到一个参数,使得样本总体损失函数/经验风险最小化
![]()
通过不断地输入样本训练集的数据,就会得到损失函数的不同取值,当经验函数的取值不是最小,那么就改进决策函数中的θ值,直到经验风险收敛。

最优化风险函数,使得经验风险最小的方法称为"参数学习法/学习算法":梯度下降法(常用)
( 如果一个函数f(x)在a处可微,那么该函数在a点 沿着梯度相反的方向下降最快 )
![]()
梯度下降法原理证明(利用一阶泰勒展开式):
( 泰勒展开式原理:函数的局部线性近似 )
=> 根据图像的直线方程可得:
![]()

由于(θ - θ0)是一个向量,可将其分为单位向量v与一个常量η的乘积:
![]()
![]()
因为每次变化都需要使得f(θ)的值减小,所以要满足f(θ)<f(θ0):
![]()
因为 η 是正值,现将其与忽略(不等式仍成立):
![]()
因为梯度与v都是向量,当二者反向时,上述取得最小值:
![]()
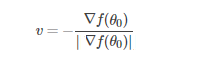
将上述 v 带入 下式:
![]()
合并常量参数后可得:
![]()
不同机器学习算法的区别在于决策函数与学习算法的差异,相同的决策算法也可以有不同的学习算法。